 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Feature- and Similarity-Based Models for Prediction and Interpretation using Large-Scale Observational Data
Apr 12, 2022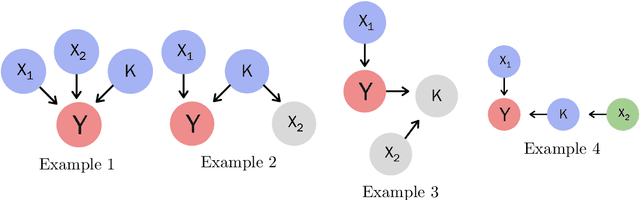
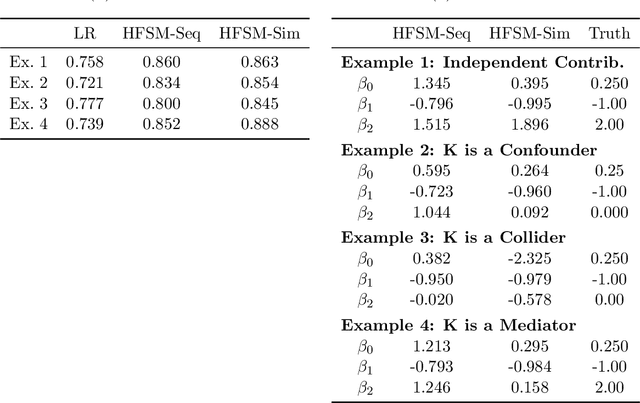
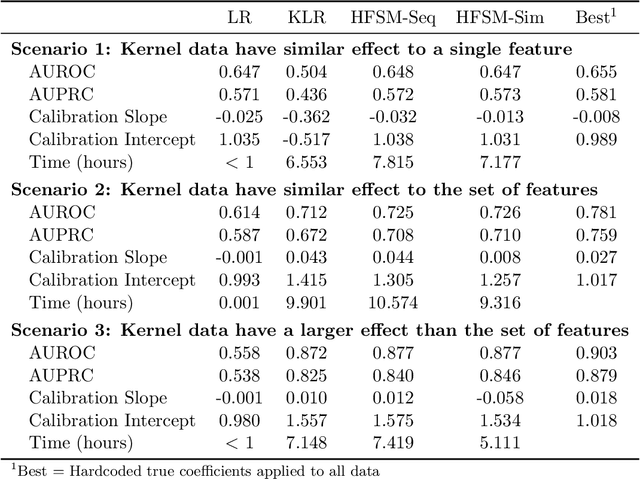
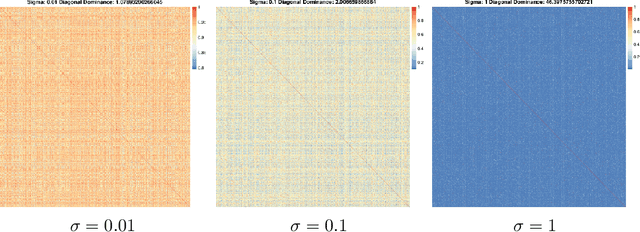
Introduction: Large-scale electronic health record(EHR) datasets often include simple informative features like patient age and complex data like care history that are not easily represented as individual features. Such complex data have the potential to both improve the quality of risk assessment and to enable a better understanding of causal factors leading to those risks. We propose a hybrid feature- and similarity-based model for supervised learning that combines feature and kernel learning approaches to take advantage of rich but heterogeneous observational data sources to create interpretable models for prediction and for investigation of causal relationships. Methods: The proposed hybrid model is fit by convex optimization with a sparsity-inducing penalty on the kernel portion. Feature and kernel coefficients can be fit sequentially or simultaneously. We compared our models to solely feature- and similarity-based approaches using synthetic data and using EHR data from a primary health care organization to predict risk of loneliness or social isolation. We also present a new strategy for kernel construction that is suited to high-dimensional indicator-coded EHR data. Results: The hybrid models had comparable or better predictive performance than the feature- and kernel-based approaches in both the synthetic and clinical case studies. The inherent interpretability of the hybrid model is used to explore client characteristics stratified by kernel coefficient direction in the clinical case study; we use simple examples to discuss opportunities and cautions of the two hybrid model forms when causal interpretations are desired. Conclusion: Hybrid feature- and similarity-based models provide an opportunity to capture complex, high-dimensional data within an additive model structure that supports improved prediction and interpretation relative to simple models and opaque complex models.