Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision-Directed Data Decomposition
Paper and Code
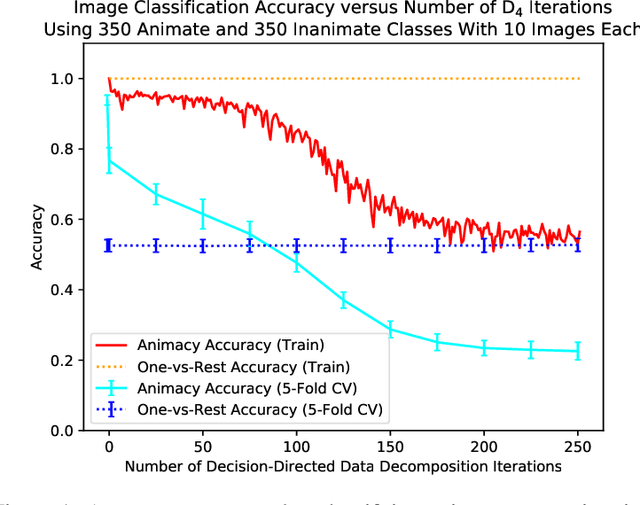

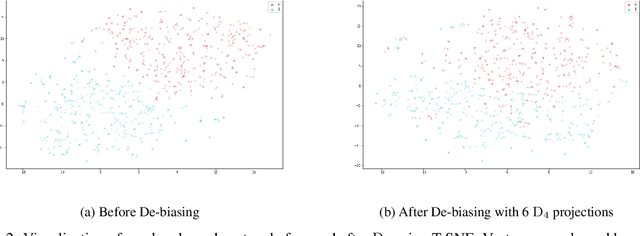
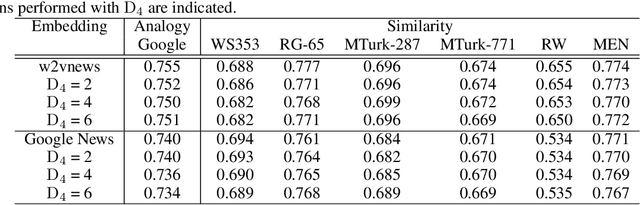
We present an algorithm, Decision-Directed Data Decomposition, which decomposes a dataset into two components. The first contains most of the useful information for a specified supervised learning task, and the second orthogonal component that contains little information about the task. The algorithm is simple and scalable. It can use kernel techniques to help preserve desirable information in the decomposition. We illustrate its application to tasks in two domains, using distributed representations of words and images, and we report state-of-the-art results showcasing $D_4$'s capability to remove information pertaining to gender from word embeddings.
View paper on