 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Has Curvature
Feb 13, 2026Does text have an intrinsic curvature? Language is increasingly modeled in curved geometries - hyperbolic spaces for hierarchy, mixed-curvature manifolds for compositional structure - yet a basic scientific question remains unresolved: what does curvature mean for text itself, in a way that is native to language rather than an artifact of the embedding space we choose? We argue that text does indeed have curvature, and show how to detect it, define it, and use it. To this end, we propose Texture, a text-native, word-level discrete curvature signal, and make three contributions. (a) Existence: We provide empirical and theoretical certificates that semantic inference in natural corpora is non-flat, i.e. language has inherent curvature. (b) Definition: We define Texture by reconciling left- and right-context beliefs around a masked word through a Schrodinger bridge, yielding a curvature field that is positive where context focuses meaning and negative where it fans out into competing continuations. (c) Utility: Texture is actionable: it serves as a general-purpose measurement and control primitive enabling geometry without geometric training; we instantiate it on two representative tasks, improving long-context inference through curvature-guided compression and retrieval-augmented generation through curvature-guided routing. Together, our results establish a text-native curvature paradigm, making curvature measurable and practically useful.
CurvGAD: Leveraging Curvature for Enhanced Graph Anomaly Detection
Feb 12, 2025Does the intrinsic curvature of complex networks hold the key to unveiling graph anomalies that conventional approaches overlook? Reconstruction-based graph anomaly detection (GAD) methods overlook such geometric outliers, focusing only on structural and attribute-level anomalies. To this end, we propose CurvGAD - a mixed-curvature graph autoencoder that introduces the notion of curvature-based geometric anomalies. CurvGAD introduces two parallel pipelines for enhanced anomaly interpretability: (1) Curvature-equivariant geometry reconstruction, which focuses exclusively on reconstructing the edge curvatures using a mixed-curvature, Riemannian encoder and Gaussian kernel-based decoder; and (2) Curvature-invariant structure and attribute reconstruction, which decouples structural and attribute anomalies from geometric irregularities by regularizing graph curvature under discrete Ollivier-Ricci flow, thereby isolating the non-geometric anomalies. By leveraging curvature, CurvGAD refines the existing anomaly classifications and identifies new curvature-driven anomalies. Extensive experimentation over 10 real-world datasets (both homophilic and heterophilic) demonstrates an improvement of up to 6.5% over state-of-the-art GAD methods.
Concept-Based Interpretable Reinforcement Learning with Limited to No Human Labels
Jul 22, 2024



Recent advances in reinforcement learning (RL) have predominantly leveraged neural network-based policies for decision-making, yet these models often lack interpretability, posing challenges for stakeholder comprehension and trust. Concept bottleneck models offer an interpretable alternative by integrating human-understandable concepts into neural networks. However, a significant limitation in prior work is the assumption that human annotations for these concepts are readily available during training, necessitating continuous real-time input from human annotators. To overcome this limitation, we introduce a novel training scheme that enables RL algorithms to efficiently learn a concept-based policy by only querying humans to label a small set of data, or in the extreme case, without any human labels. Our algorithm, LICORICE, involves three main contributions: interleaving concept learning and RL training, using a concept ensembles to actively select informative data points for labeling, and decorrelating the concept data with a simple strategy. We show how LICORICE reduces manual labeling efforts to to 500 or fewer concept labels in three environments. Finally, we present an initial study to explore how we can use powerful vision-language models to infer concepts from raw visual inputs without explicit labels at minimal cost to performance.
Meta-Analysis with Untrusted Data
Jul 12, 2024[See paper for full abstract] Meta-analysis is a crucial tool for answering scientific questions. It is usually conducted on a relatively small amount of ``trusted'' data -- ideally from randomized, controlled trials -- which allow causal effects to be reliably estimated with minimal assumptions. We show how to answer causal questions much more precisely by making two changes. First, we incorporate untrusted data drawn from large observational databases, related scientific literature and practical experience -- without sacrificing rigor or introducing strong assumptions. Second, we train richer models capable of handling heterogeneous trials, addressing a long-standing challenge in meta-analysis. Our approach is based on conformal prediction, which fundamentally produces rigorous prediction intervals, but doesn't handle indirect observations: in meta-analysis, we observe only noisy effects due to the limited number of participants in each trial. To handle noise, we develop a simple, efficient version of fully-conformal kernel ridge regression, based on a novel condition called idiocentricity. We introduce noise-correcting terms in the residuals and analyze their interaction with a ``variance shaving'' technique. In multiple experiments on healthcare datasets, our algorithms deliver tighter, sounder intervals than traditional ones. This paper charts a new course for meta-analysis and evidence-based medicine, where heterogeneity and untrusted data are embraced for more nuanced and precise predictions.
Successor Feature Sets: Generalizing Successor Representations Across Policies
Mar 15, 2021Successor-style representations have many advantages for reinforcement learning: for example, they can help an agent generalize from past experience to new goals, and they have been proposed as explanations of behavioral and neural data from human and animal learners. They also form a natural bridge between model-based and model-free RL methods: like the former they make predictions about future experiences, and like the latter they allow efficient prediction of total discounted rewards. However, successor-style representations are not optimized to generalize across policies: typically, we maintain a limited-length list of policies, and share information among them by representation learning or GPI. Successor-style representations also typically make no provision for gathering information or reasoning about latent variables. To address these limitations, we bring together ideas from predictive state representations, belief space value iteration, successor features, and convex analysis: we develop a new, general successor-style representation, together with a Bellman equation that connects multiple sources of information within this representation, including different latent states, policies, and reward functions. The new representation is highly expressive: for example, it lets us efficiently read off an optimal policy for a new reward function, or a policy that imitates a new demonstration. For this paper, we focus on exact computation of the new representation in small, known environments, since even this restricted setting offers plenty of interesting questions. Our implementation does not scale to large, unknown environments -- nor would we expect it to, since it generalizes POMDP value iteration, which is difficult to scale. However, we believe that future work will allow us to extend our ideas to approximate reasoning in large, unknown environments.
Understanding and Mitigating Accuracy Disparity in Regression
Feb 24, 2021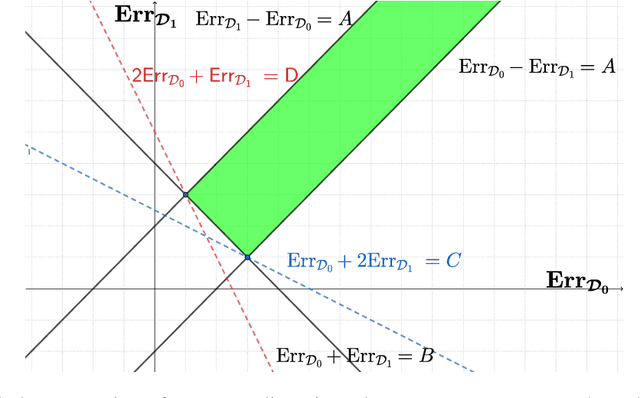

With the widespread deployment of large-scale prediction systems in high-stakes domains, e.g., face recognition, criminal justice, etc., disparity on prediction accuracy between different demographic subgroups has called for fundamental understanding on the source of such disparity and algorithmic intervention to mitigate it. In this paper, we study the accuracy disparity problem in regression. To begin with, we first propose an error decomposition theorem, which decomposes the accuracy disparity into the distance between marginal label distributions and the distance between conditional representations, to help explain why such accuracy disparity appears in practice. Motivated by this error decomposition and the general idea of distribution alignment with statistical distances, we then propose an algorithm to reduce this disparity, and analyze its game-theoretic optima of the proposed objective functions. To corroborate our theoretical findings, we also conduct experiments on five benchmark datasets. The experimental results suggest that our proposed algorithms can effectively mitigate accuracy disparity while maintaining the predictive power of the regression models.
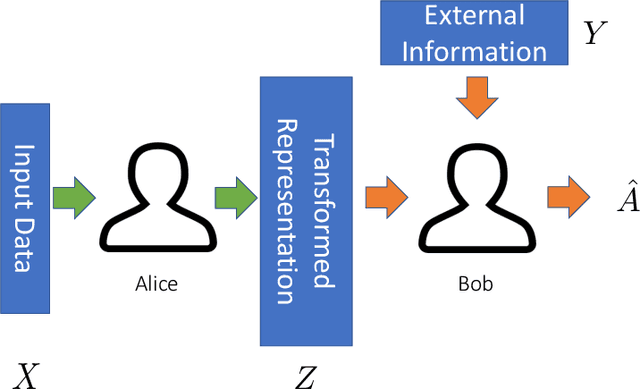
Fundamental Limits and Tradeoffs in Invariant Representation Learning
Dec 19, 2020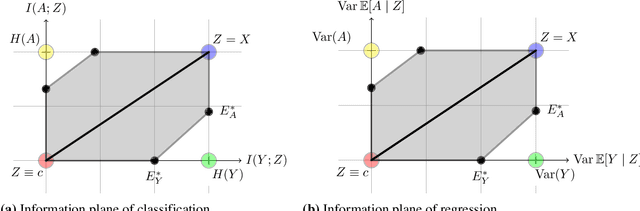
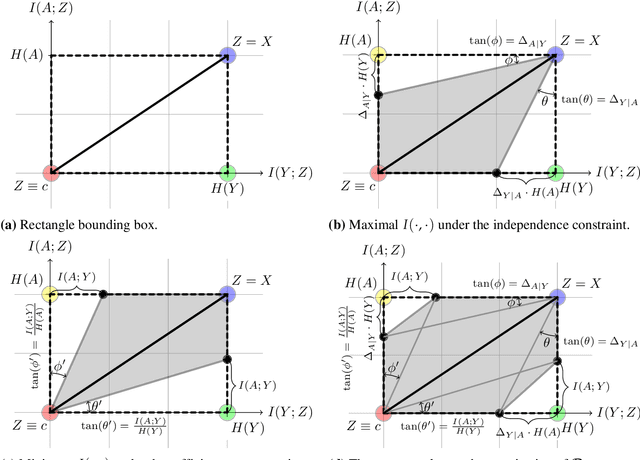
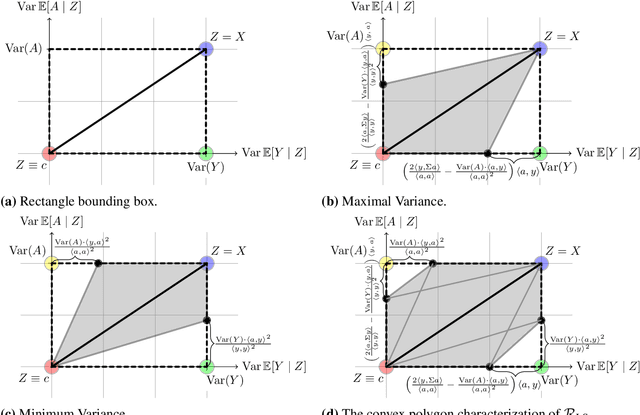
Many machine learning applications involve learning representations that achieve two competing goals: To maximize information or accuracy with respect to a subset of features (e.g.\ for prediction) while simultaneously maximizing invariance or independence with respect to another, potentially overlapping, subset of features (e.g.\ for fairness, privacy, etc). Typical examples include privacy-preserving learning, domain adaptation, and algorithmic fairness, just to name a few. In fact, all of the above problems admit a common minimax game-theoretic formulation, whose equilibrium represents a fundamental tradeoff between accuracy and invariance. Despite its abundant applications in the aforementioned domains, theoretical understanding on the limits and tradeoffs of invariant representations is severely lacking. In this paper, we provide an information-theoretic analysis of this general and important problem under both classification and regression settings. In both cases, we analyze the inherent tradeoffs between accuracy and invariance by providing a geometric characterization of the feasible region in the information plane, where we connect the geometric properties of this feasible region to the fundamental limitations of the tradeoff problem. In the regression setting, we also derive a tight lower bound on the Lagrangian objective that quantifies the tradeoff between accuracy and invariance. This lower bound leads to a better understanding of the tradeoff via the spectral properties of the joint distribution. In both cases, our results shed new light on this fundamental problem by providing insights on the interplay between accuracy and invariance. These results deepen our understanding of this fundamental problem and may be useful in guiding the design of adversarial representation learning algorithms.
An Empirical Investigation of Beam-Aware Training in Supertagging
Oct 10, 2020
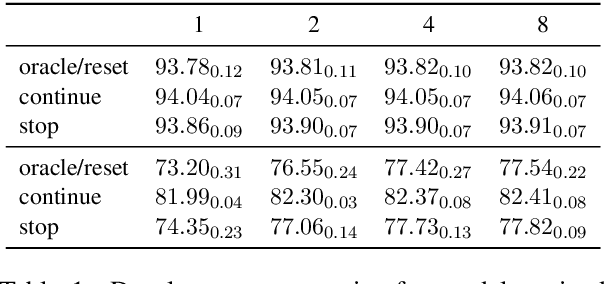
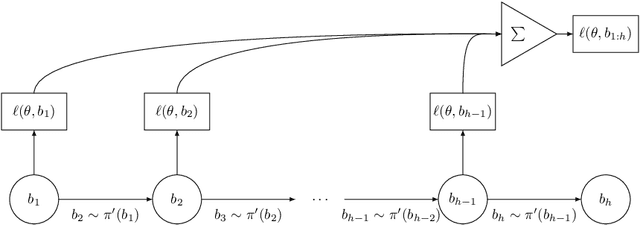
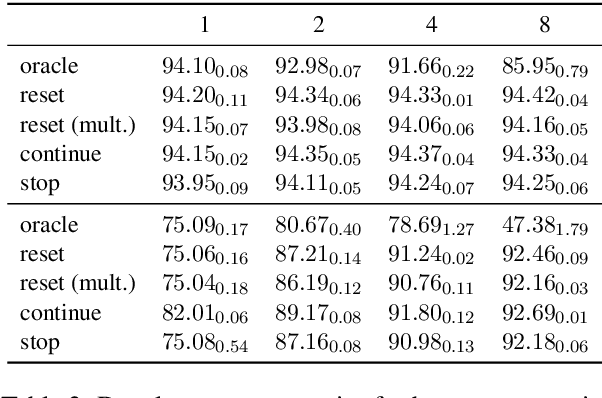
Structured prediction is often approached by training a locally normalized model with maximum likelihood and decoding approximately with beam search. This approach leads to mismatches as, during training, the model is not exposed to its mistakes and does not use beam search. Beam-aware training aims to address these problems, but unfortunately, it is not yet widely used due to a lack of understanding about how it impacts performance, when it is most useful, and whether it is stable. Recently, Negrinho et al. (2018) proposed a meta-algorithm that captures beam-aware training algorithms and suggests new ones, but unfortunately did not provide empirical results. In this paper, we begin an empirical investigation: we train the supertagging model of Vaswani et al. (2016) and a simpler model with instantiations of the meta-algorithm. We explore the influence of various design choices and make recommendations for choosing them. We observe that beam-aware training improves performance for both models, with large improvements for the simpler model which must effectively manage uncertainty during decoding. Our results suggest that a model must be learned with search to maximize its effectiveness.
Conditional Learning of Fair Representations
Oct 16, 2019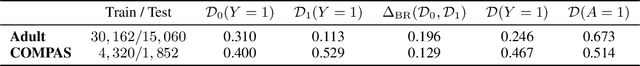

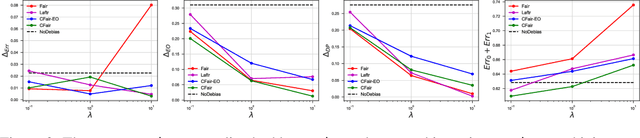

We propose a novel algorithm for learning fair representations that can simultaneously mitigate two notions of disparity among different demographic subgroups. Two key components underpinning the design of our algorithm are balanced error rate and conditional alignment of representations. We show how these two components contribute to ensuring accuracy parity and equalized false-positive and false-negative rates across groups without impacting demographic parity. Furthermore, we also demonstrate both in theory and on two real-world experiments that the proposed algorithm leads to a better utility-fairness trade-off on balanced datasets compared with existing algorithms on learning fair representations.
Learning Neural Networks with Adaptive Regularization
Jul 14, 2019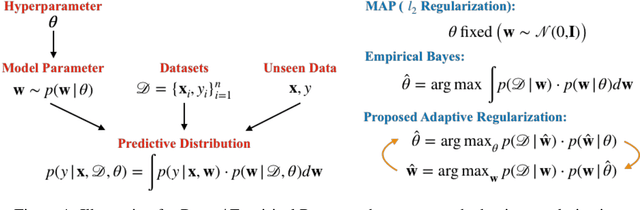
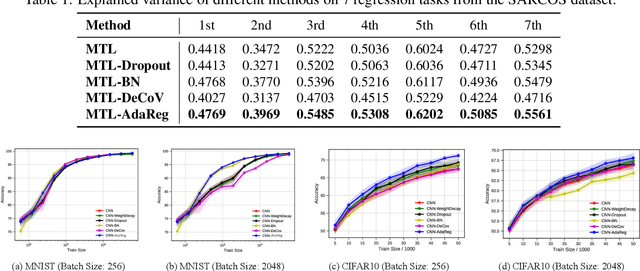
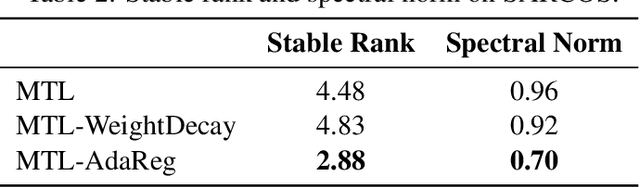
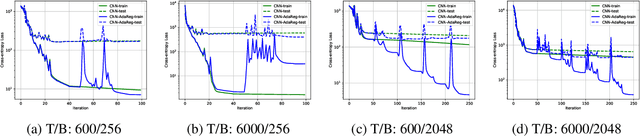
Feed-forward neural networks can be understood as a combination of an intermediate representation and a linear hypothesis. While most previous works aim to diversify the representations, we explore the complementary direction by performing an adaptive and data-dependent regularization motivated by the empirical Bayes method. Specifically, we propose to construct a matrix-variate normal prior (on weights) whose covariance matrix has a Kronecker product structure. This structure is designed to capture the correlations in neurons through backpropagation. Under the assumption of this Kronecker factorization, the prior encourages neurons to borrow statistical strength from one another. Hence, it leads to an adaptive and data-dependent regularization when training networks on small datasets. To optimize the model, we present an efficient block coordinate descent algorithm with analytical solutions. Empirically, we demonstrate that the proposed method helps networks converge to local optima with smaller stable ranks and spectral norms. These properties suggest better generalizations and we present empirical results to support this expectation. We also verify the effectiveness of the approach on multiclass classification and multitask regression problems with various network structures.