 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Has Curvature
Feb 13, 2026Does text have an intrinsic curvature? Language is increasingly modeled in curved geometries - hyperbolic spaces for hierarchy, mixed-curvature manifolds for compositional structure - yet a basic scientific question remains unresolved: what does curvature mean for text itself, in a way that is native to language rather than an artifact of the embedding space we choose? We argue that text does indeed have curvature, and show how to detect it, define it, and use it. To this end, we propose Texture, a text-native, word-level discrete curvature signal, and make three contributions. (a) Existence: We provide empirical and theoretical certificates that semantic inference in natural corpora is non-flat, i.e. language has inherent curvature. (b) Definition: We define Texture by reconciling left- and right-context beliefs around a masked word through a Schrodinger bridge, yielding a curvature field that is positive where context focuses meaning and negative where it fans out into competing continuations. (c) Utility: Texture is actionable: it serves as a general-purpose measurement and control primitive enabling geometry without geometric training; we instantiate it on two representative tasks, improving long-context inference through curvature-guided compression and retrieval-augmented generation through curvature-guided routing. Together, our results establish a text-native curvature paradigm, making curvature measurable and practically useful.
Feedback Control for Multi-Objective Graph Self-Supervision
Feb 04, 2026Can multi-task self-supervised learning on graphs be coordinated without the usual tug-of-war between objectives? Graph self-supervised learning (SSL) offers a growing toolbox of pretext objectives: mutual information, reconstruction, contrastive learning; yet combining them reliably remains a challenge due to objective interference and training instability. Most multi-pretext pipelines use per-update mixing, forcing every parameter update to be a compromise, leading to three failure modes: Disagreement (conflict-induced negative transfer), Drift (nonstationary objective utility), and Drought (hidden starvation of underserved objectives). We argue that coordination is fundamentally a temporal allocation problem: deciding when each objective receives optimization budget, not merely how to weigh them. We introduce ControlG, a control-theoretic framework that recasts multi-objective graph SSL as feedback-controlled temporal allocation by estimating per-objective difficulty and pairwise antagonism, planning target budgets via a Pareto-aware log-hypervolume planner, and scheduling with a Proportional-Integral-Derivative (PID) controller. Across 9 datasets, ControlG consistently outperforms state-of-the-art baselines, while producing an auditable schedule that reveals which objectives drove learning.
CurvGAD: Leveraging Curvature for Enhanced Graph Anomaly Detection
Feb 12, 2025Does the intrinsic curvature of complex networks hold the key to unveiling graph anomalies that conventional approaches overlook? Reconstruction-based graph anomaly detection (GAD) methods overlook such geometric outliers, focusing only on structural and attribute-level anomalies. To this end, we propose CurvGAD - a mixed-curvature graph autoencoder that introduces the notion of curvature-based geometric anomalies. CurvGAD introduces two parallel pipelines for enhanced anomaly interpretability: (1) Curvature-equivariant geometry reconstruction, which focuses exclusively on reconstructing the edge curvatures using a mixed-curvature, Riemannian encoder and Gaussian kernel-based decoder; and (2) Curvature-invariant structure and attribute reconstruction, which decouples structural and attribute anomalies from geometric irregularities by regularizing graph curvature under discrete Ollivier-Ricci flow, thereby isolating the non-geometric anomalies. By leveraging curvature, CurvGAD refines the existing anomaly classifications and identifies new curvature-driven anomalies. Extensive experimentation over 10 real-world datasets (both homophilic and heterophilic) demonstrates an improvement of up to 6.5% over state-of-the-art GAD methods.
Public Wisdom Matters! Discourse-Aware Hyperbolic Fourier Co-Attention for Social-Text Classification
Sep 15, 2022
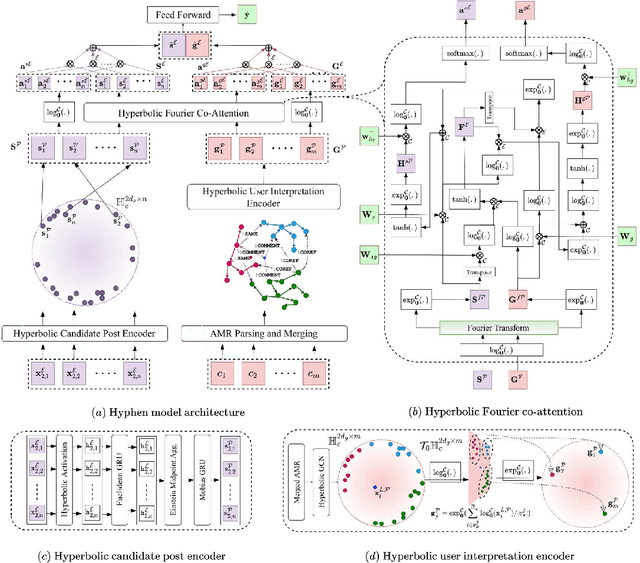
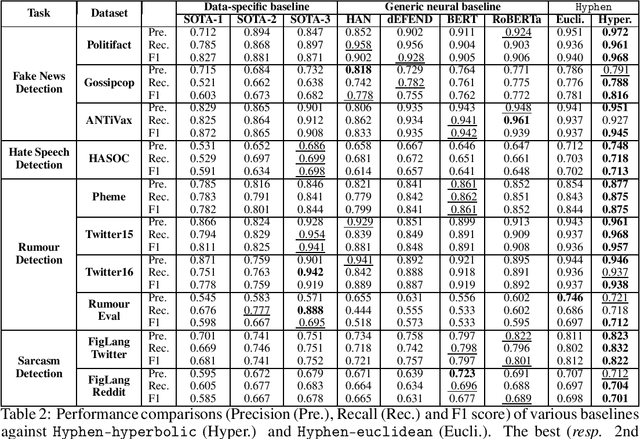
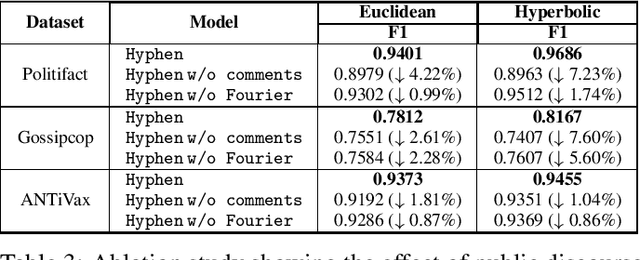
Social media has become the fulcrum of all forms of communication. Classifying social texts such as fake news, rumour, sarcasm, etc. has gained significant attention. The surface-level signals expressed by a social-text itself may not be adequate for such tasks; therefore, recent methods attempted to incorporate other intrinsic signals such as user behavior and the underlying graph structure. Oftentimes, the `public wisdom' expressed through the comments/replies to a social-text acts as a surrogate of crowd-sourced view and may provide us with complementary signals. State-of-the-art methods on social-text classification tend to ignore such a rich hierarchical signal. Here, we propose Hyphen, a discourse-aware hyperbolic spectral co-attention network. Hyphen is a fusion of hyperbolic graph representation learning with a novel Fourier co-attention mechanism in an attempt to generalise the social-text classification tasks by incorporating public discourse. We parse public discourse as an Abstract Meaning Representation (AMR) graph and use the powerful hyperbolic geometric representation to model graphs with hierarchical structure. Finally, we equip it with a novel Fourier co-attention mechanism to capture the correlation between the source post and public discourse. Extensive experiments on four different social-text classification tasks, namely detecting fake news, hate speech, rumour, and sarcasm, show that Hyphen generalises well, and achieves state-of-the-art results on ten benchmark datasets. We also employ a sentence-level fact-checked and annotated dataset to evaluate how Hyphen is capable of producing explanations as analogous evidence to the final prediction.