 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Investigation of Beam-Aware Training in Supertagging
Paper and Code

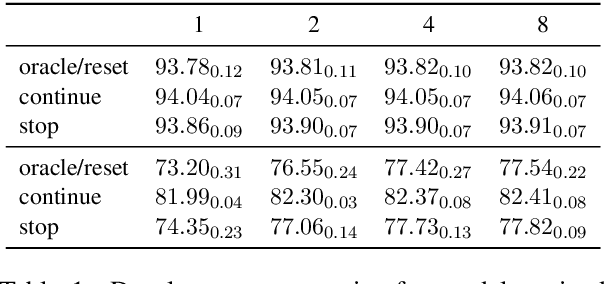
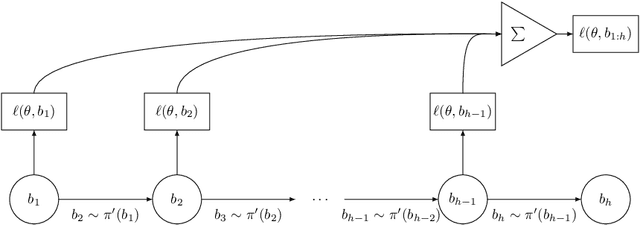
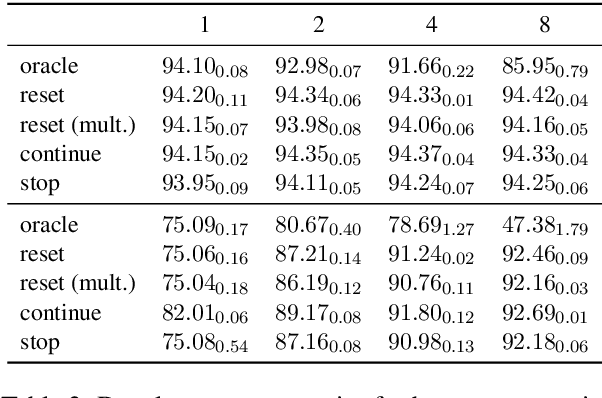
Structured prediction is often approached by training a locally normalized model with maximum likelihood and decoding approximately with beam search. This approach leads to mismatches as, during training, the model is not exposed to its mistakes and does not use beam search. Beam-aware training aims to address these problems, but unfortunately, it is not yet widely used due to a lack of understanding about how it impacts performance, when it is most useful, and whether it is stable. Recently, Negrinho et al. (2018) proposed a meta-algorithm that captures beam-aware training algorithms and suggests new ones, but unfortunately did not provide empirical results. In this paper, we begin an empirical investigation: we train the supertagging model of Vaswani et al. (2016) and a simpler model with instantiations of the meta-algorithm. We explore the influence of various design choices and make recommendations for choosing them. We observe that beam-aware training improves performance for both models, with large improvements for the simpler model which must effectively manage uncertainty during decoding. Our results suggest that a model must be learned with search to maximize its effectiveness.