 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models of Code Fail at Completing Code with Potential Bugs
Jun 06, 2023



Large language models of code (Code-LLMs) have recently brought tremendous advances to code completion, a fundamental feature of programming assistance and code intelligence. However, most existing works ignore the possible presence of bugs in the code context for generation, which are inevitable in software development. Therefore, we introduce and study the buggy-code completion problem, inspired by the realistic scenario of real-time code suggestion where the code context contains potential bugs -- anti-patterns that can become bugs in the completed program. To systematically study the task, we introduce two datasets: one with synthetic bugs derived from semantics-altering operator changes (buggy-HumanEval) and one with realistic bugs derived from user submissions to coding problems (buggy-FixEval). We find that the presence of potential bugs significantly degrades the generation performance of the high-performing Code-LLMs. For instance, the passing rates of CodeGen-2B-mono on test cases of buggy-HumanEval drop more than 50% given a single potential bug in the context. Finally, we investigate several post-hoc methods for mitigating the adverse effect of potential bugs and find that there remains a large gap in post-mitigation performance.
Leveraging Pretrained Models for Automatic Summarization of Doctor-Patient Conversations
Sep 24, 2021

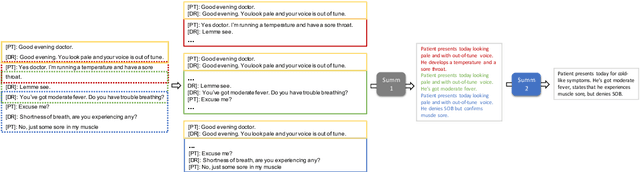
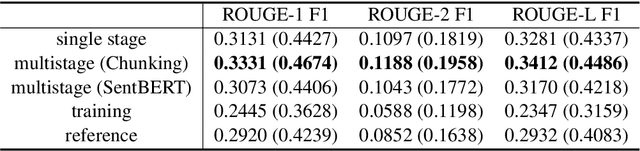
Fine-tuning pretrained models for automatically summarizing doctor-patient conversation transcripts presents many challenges: limited training data, significant domain shift, long and noisy transcripts, and high target summary variability. In this paper, we explore the feasibility of using pretrained transformer models for automatically summarizing doctor-patient conversations directly from transcripts. We show that fluent and adequate summaries can be generated with limited training data by fine-tuning BART on a specially constructed dataset. The resulting models greatly surpass the performance of an average human annotator and the quality of previous published work for the task. We evaluate multiple methods for handling long conversations, comparing them to the obvious baseline of truncating the conversation to fit the pretrained model length limit. We introduce a multistage approach that tackles the task by learning two fine-tuned models: one for summarizing conversation chunks into partial summaries, followed by one for rewriting the collection of partial summaries into a complete summary. Using a carefully chosen fine-tuning dataset, this method is shown to be effective at handling longer conversations, improving the quality of generated summaries. We conduct both an automatic evaluation (through ROUGE and two concept-based metrics focusing on medical findings) and a human evaluation (through qualitative examples from literature, assessing hallucination, generalization, fluency, and general quality of the generated summaries).
COCO Denoiser: Using Co-Coercivity for Variance Reduction in Stochastic Convex Optimization
Sep 07, 2021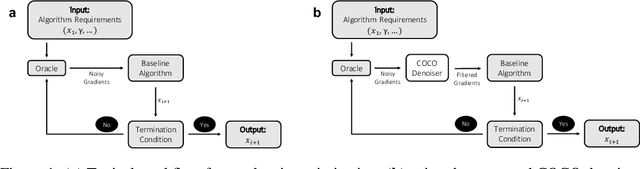
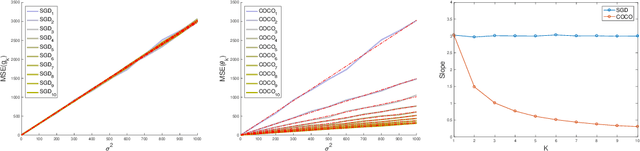
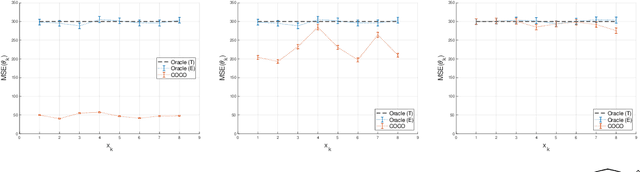
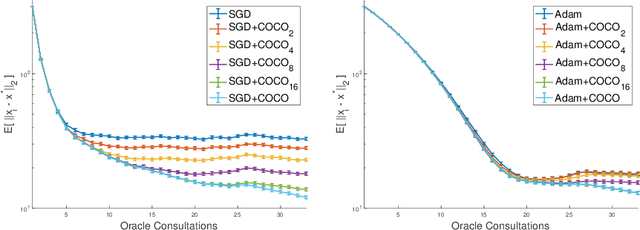
First-order methods for stochastic optimization have undeniable relevance, in part due to their pivotal role in machine learning. Variance reduction for these algorithms has become an important research topic. In contrast to common approaches, which rarely leverage global models of the objective function, we exploit convexity and L-smoothness to improve the noisy estimates outputted by the stochastic gradient oracle. Our method, named COCO denoiser, is the joint maximum likelihood estimator of multiple function gradients from their noisy observations, subject to co-coercivity constraints between them. The resulting estimate is the solution of a convex Quadratically Constrained Quadratic Problem. Although this problem is expensive to solve by interior point methods, we exploit its structure to apply an accelerated first-order algorithm, the Fast Dual Proximal Gradient method. Besides analytically characterizing the proposed estimator, we show empirically that increasing the number and proximity of the queried points leads to better gradient estimates. We also apply COCO in stochastic settings by plugging it in existing algorithms, such as SGD, Adam or STRSAGA, outperforming their vanilla versions, even in scenarios where our modelling assumptions are mismatched.
An Empirical Investigation of Beam-Aware Training in Supertagging
Oct 10, 2020
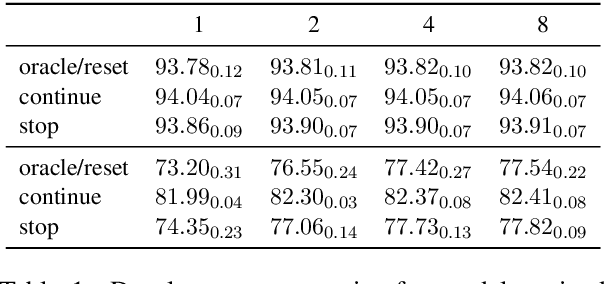
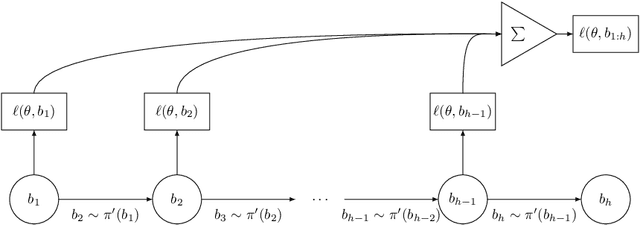
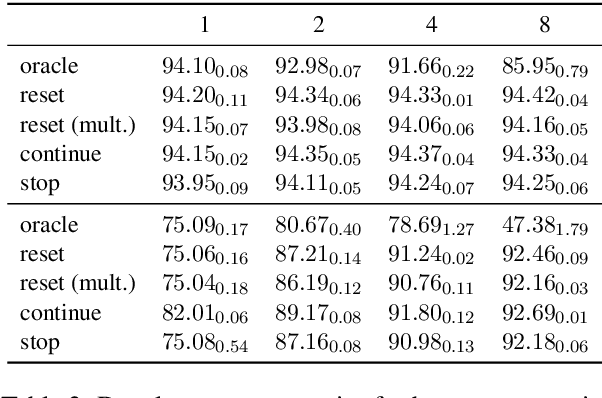
Structured prediction is often approached by training a locally normalized model with maximum likelihood and decoding approximately with beam search. This approach leads to mismatches as, during training, the model is not exposed to its mistakes and does not use beam search. Beam-aware training aims to address these problems, but unfortunately, it is not yet widely used due to a lack of understanding about how it impacts performance, when it is most useful, and whether it is stable. Recently, Negrinho et al. (2018) proposed a meta-algorithm that captures beam-aware training algorithms and suggests new ones, but unfortunately did not provide empirical results. In this paper, we begin an empirical investigation: we train the supertagging model of Vaswani et al. (2016) and a simpler model with instantiations of the meta-algorithm. We explore the influence of various design choices and make recommendations for choosing them. We observe that beam-aware training improves performance for both models, with large improvements for the simpler model which must effectively manage uncertainty during decoding. Our results suggest that a model must be learned with search to maximize its effectiveness.
Seeing without Looking: Contextual Rescoring of Object Detections for AP Maximization
Dec 27, 2019
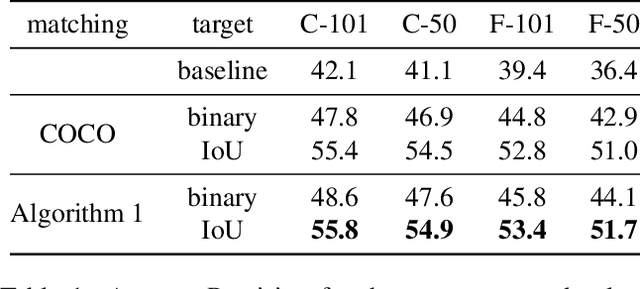
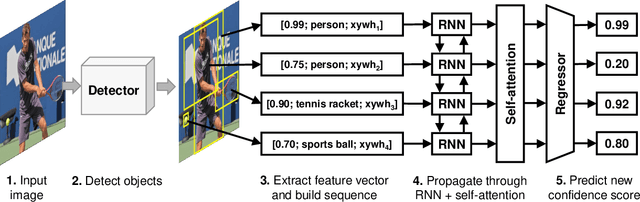
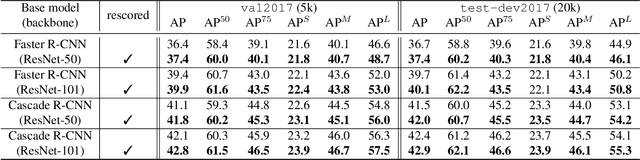
The majority of current object detectors lack context: class predictions are made independently from other detections. We propose to incorporate context in object detection by post-processing the output of an arbitrary detector to rescore the confidences of its detections. Rescoring is done by conditioning on contextual information from the entire set of detections: their confidences, predicted classes, and positions. We show that AP can be improved by simply reassigning the detection confidence values such that true positives that survive longer (i.e., those with the correct class and large IoU) are scored higher than false positives or detections with small IoU. In this setting, we use a bidirectional RNN with attention for contextual rescoring and introduce a training target that uses the IoU with ground truth to maximize AP for the given set of detections. The fact that our approach does not require access to visual features makes it computationally inexpensive and agnostic to the detection architecture. In spite of this simplicity, our model consistently improves AP over strong pre-trained baselines (Cascade R-CNN and Faster R-CNN with several backbones), particularly by reducing the confidence of duplicate detections (a learned form of non-maximum suppression) and removing out-of-context objects by conditioning on the confidences, classes, positions, and sizes of the co-occurrent detections (e.g., a high-confidence detection of bird makes a detection of sports ball less likely).
Towards modular and programmable architecture search
Sep 30, 2019
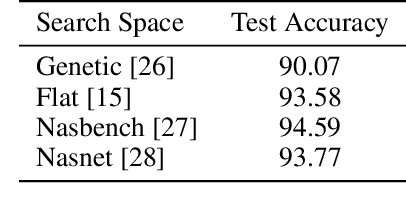

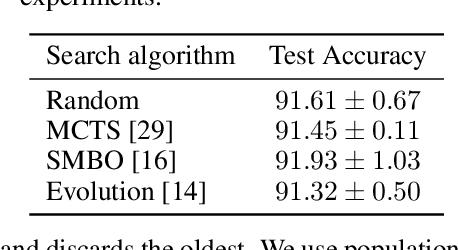
Neural architecture search methods are able to find high performance deep learning architectures with minimal effort from an expert. However, current systems focus on specific use-cases (e.g. convolutional image classifiers and recurrent language models), making them unsuitable for general use-cases that an expert might wish to write. Hyperparameter optimization systems are general-purpose but lack the constructs needed for easy application to architecture search. In this work, we propose a formal language for encoding search spaces over general computational graphs. The language constructs allow us to write modular, composable, and reusable search space encodings and to reason about search space design. We use our language to encode search spaces from the architecture search literature. The language allows us to decouple the implementations of the search space and the search algorithm, allowing us to expose search spaces to search algorithms through a consistent interface. Our experiments show the ease with which we can experiment with different combinations of search spaces and search algorithms without having to implement each combination from scratch. We release an implementation of our language with this paper.
Learning Beam Search Policies via Imitation Learning
Nov 01, 2018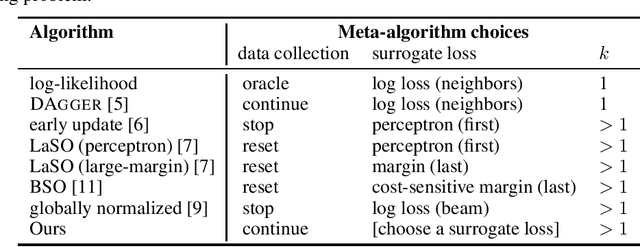
Beam search is widely used for approximate decoding in structured prediction problems. Models often use a beam at test time but ignore its existence at train time, and therefore do not explicitly learn how to use the beam. We develop an unifying meta-algorithm for learning beam search policies using imitation learning. In our setting, the beam is part of the model, and not just an artifact of approximate decoding. Our meta-algorithm captures existing learning algorithms and suggests new ones. It also lets us show novel no-regret guarantees for learning beam search policies.
DeepArchitect: Automatically Designing and Training Deep Architectures
Apr 28, 2017
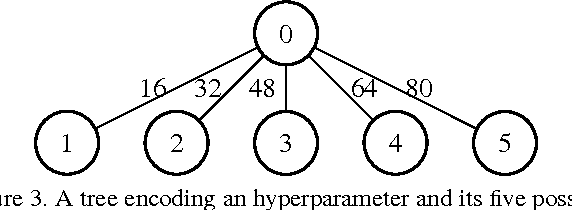
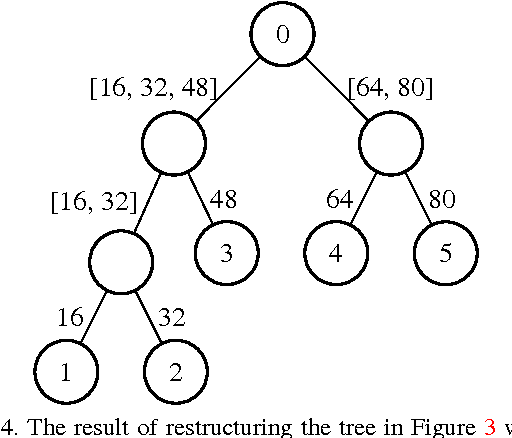
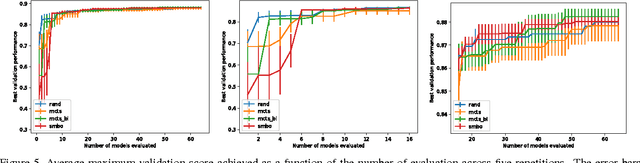
In deep learning, performance is strongly affected by the choice of architecture and hyperparameters. While there has been extensive work on automatic hyperparameter optimization for simple spaces, complex spaces such as the space of deep architectures remain largely unexplored. As a result, the choice of architecture is done manually by the human expert through a slow trial and error process guided mainly by intuition. In this paper we describe a framework for automatically designing and training deep models. We propose an extensible and modular language that allows the human expert to compactly represent complex search spaces over architectures and their hyperparameters. The resulting search spaces are tree-structured and therefore easy to traverse. Models can be automatically compiled to computational graphs once values for all hyperparameters have been chosen. We can leverage the structure of the search space to introduce different model search algorithms, such as random search, Monte Carlo tree search (MCTS), and sequential model-based optimization (SMBO). We present experiments comparing the different algorithms on CIFAR-10 and show that MCTS and SMBO outperform random search. In addition, these experiments show that our framework can be used effectively for model discovery, as it is possible to describe expressive search spaces and discover competitive models without much effort from the human expert. Code for our framework and experiments has been made publicly available.