 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabFlex: Scaling Tabular Learning to Millions with Linear Attention
Jun 05, 2025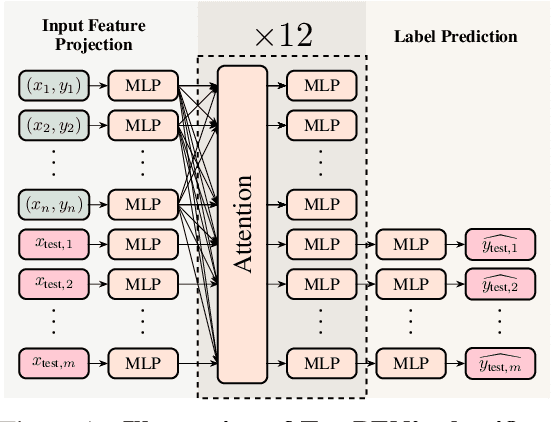
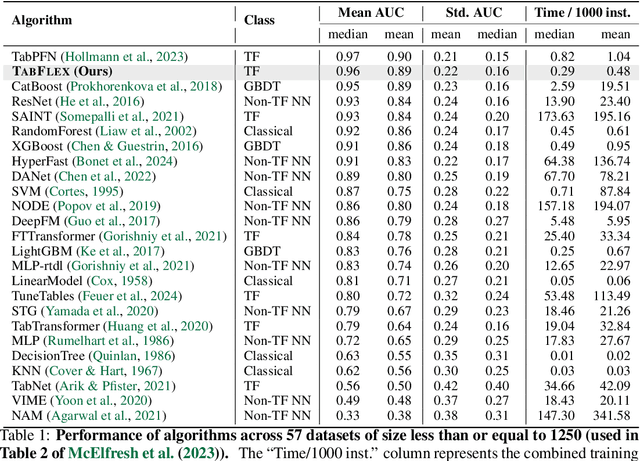
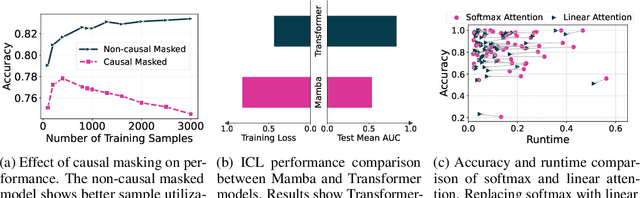
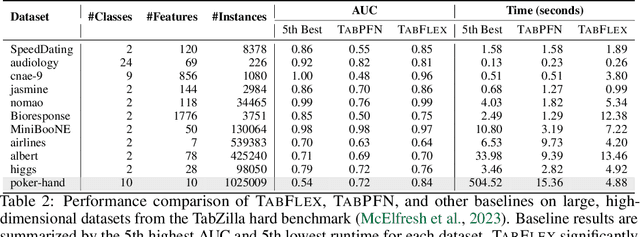
Leveraging the in-context learning (ICL) capability of Large Language Models (LLMs) for tabular classification has gained significant attention for its training-free adaptability across diverse datasets. Recent advancements, like TabPFN, excel in small-scale tabular datasets but struggle to scale for large and complex datasets. Our work enhances the efficiency and scalability of TabPFN for larger datasets by incorporating linear attention mechanisms as a scalable alternative to complexity-quadratic self-attention. Our model, TabFlex, efficiently handles tabular datasets with thousands of features and hundreds of classes, scaling seamlessly to millions of samples. For instance, TabFlex processes the poker-hand dataset with over a million samples in just 5 seconds. Our extensive evaluations demonstrate that TabFlex can achieve over a 2x speedup compared to TabPFN and a 1.5x speedup over XGBoost, outperforming 25 tested baselines in terms of efficiency across a diverse range of datasets. Furthermore, TabFlex remains highly effective on large-scale datasets, delivering strong performance with significantly reduced computational costs, especially when combined with data-efficient techniques such as dimensionality reduction and data sampling.
SuoiAI: Building a Dataset for Aquatic Invertebrates in Vietnam
Apr 21, 2025
Understanding and monitoring aquatic biodiversity is critical for ecological health and conservation efforts. This paper proposes SuoiAI, an end-to-end pipeline for building a dataset of aquatic invertebrates in Vietnam and employing machine learning (ML) techniques for species classification. We outline the methods for data collection, annotation, and model training, focusing on reducing annotation effort through semi-supervised learning and leveraging state-of-the-art object detection and classification models. Our approach aims to overcome challenges such as data scarcity, fine-grained classification, and deployment in diverse environmental conditions.
Investigating Training Strategies and Model Robustness of Low-Rank Adaptation for Language Modeling in Speech Recognition
Jan 19, 2024The use of low-rank adaptation (LoRA) with frozen pretrained language models (PLMs) has become increasing popular as a mainstream, resource-efficient modeling approach for memory-constrained hardware. In this study, we first explore how to enhance model performance by introducing various LoRA training strategies, achieving relative word error rate reductions of 3.50\% on the public Librispeech dataset and of 3.67\% on an internal dataset in the messaging domain. To further characterize the stability of LoRA-based second-pass speech recognition models, we examine robustness against input perturbations. These perturbations are rooted in homophone replacements and a novel metric called N-best Perturbation-based Rescoring Robustness (NPRR), both designed to measure the relative degradation in the performance of rescoring models. Our experimental results indicate that while advanced variants of LoRA, such as dynamic rank-allocated LoRA, lead to performance degradation in $1$-best perturbation, they alleviate the degradation in $N$-best perturbation. This finding is in comparison to fully-tuned models and vanilla LoRA tuning baselines, suggesting that a comprehensive selection is needed when using LoRA-based adaptation for compute-cost savings and robust language modeling.
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023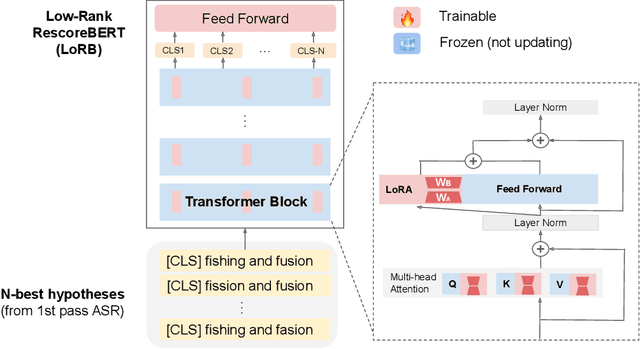
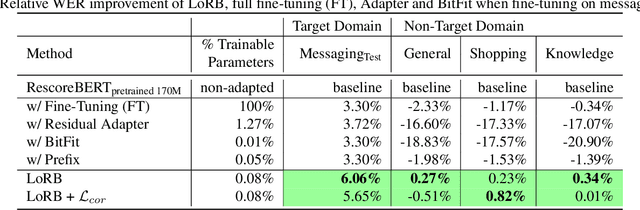
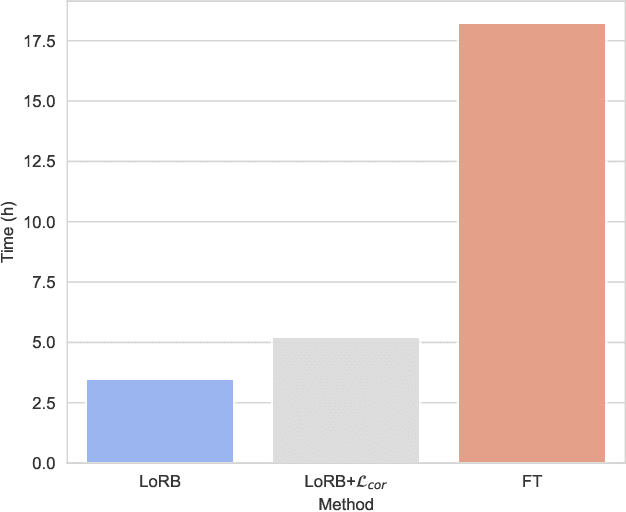
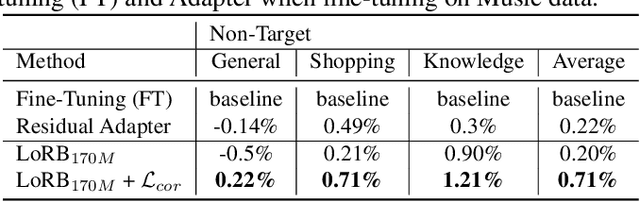
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
Large Language Models of Code Fail at Completing Code with Potential Bugs
Jun 06, 2023Large language models of code (Code-LLMs) have recently brought tremendous advances to code completion, a fundamental feature of programming assistance and code intelligence. However, most existing works ignore the possible presence of bugs in the code context for generation, which are inevitable in software development. Therefore, we introduce and study the buggy-code completion problem, inspired by the realistic scenario of real-time code suggestion where the code context contains potential bugs -- anti-patterns that can become bugs in the completed program. To systematically study the task, we introduce two datasets: one with synthetic bugs derived from semantics-altering operator changes (buggy-HumanEval) and one with realistic bugs derived from user submissions to coding problems (buggy-FixEval). We find that the presence of potential bugs significantly degrades the generation performance of the high-performing Code-LLMs. For instance, the passing rates of CodeGen-2B-mono on test cases of buggy-HumanEval drop more than 50% given a single potential bug in the context. Finally, we investigate several post-hoc methods for mitigating the adverse effect of potential bugs and find that there remains a large gap in post-mitigation performance.
LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
Jun 15, 2022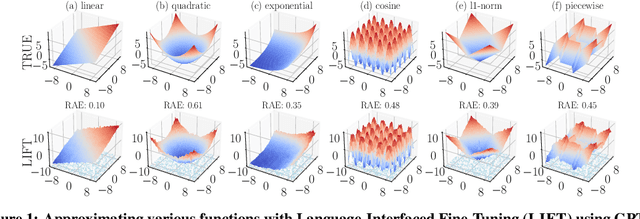
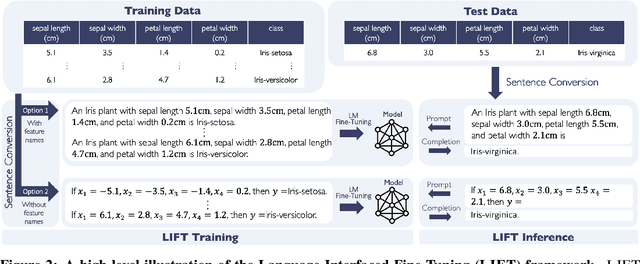

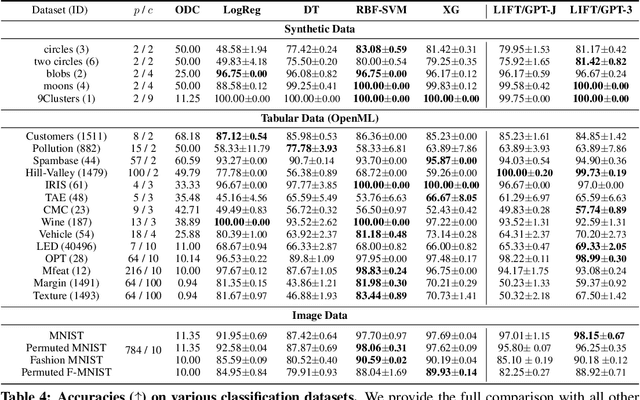
Fine-tuning pretrained language models (LMs) without making any architectural changes has become a norm for learning various language downstream tasks. However, for non-language downstream tasks, a common practice is to employ task-specific designs for input, output layers, and loss functions. For instance, it is possible to fine-tune an LM into an MNIST classifier by replacing the word embedding layer with an image patch embedding layer, the word token output layer with a 10-way output layer, and the word prediction loss with a 10-way classification loss, respectively. A natural question arises: can LM fine-tuning solve non-language downstream tasks without changing the model architecture or loss function? To answer this, we propose Language-Interfaced Fine-Tuning (LIFT) and study its efficacy and limitations by conducting an extensive empirical study on a suite of non-language classification and regression tasks. LIFT does not make any changes to the model architecture or loss function, and it solely relies on the natural language interface, enabling "no-code machine learning with LMs." We find that LIFT performs relatively well across a wide range of low-dimensional classification and regression tasks, matching the performances of the best baselines in many cases, especially for the classification tasks. We report the experimental results on the fundamental properties of LIFT, including its inductive bias, sample efficiency, ability to extrapolate, robustness to outliers and label noise, and generalization. We also analyze a few properties/techniques specific to LIFT, e.g., context-aware learning via appropriate prompting, quantification of predictive uncertainty, and two-stage fine-tuning. Our code is available at https://github.com/UW-Madison-Lee-Lab/LanguageInterfacedFineTuning.
Utilizing Language-Image Pretraining for Efficient and Robust Bilingual Word Alignment
May 23, 2022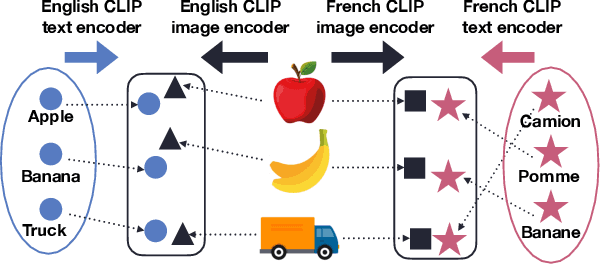
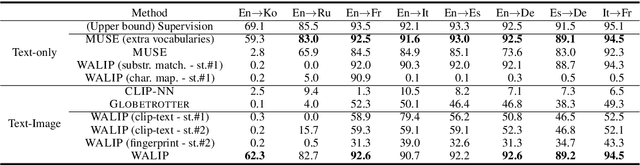

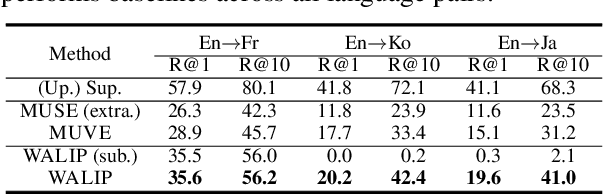
Word translation without parallel corpora has become feasible, rivaling the performance of supervised methods. Recent findings have shown that the accuracy and robustness of unsupervised word translation (UWT) can be improved by making use of visual observations, which are universal representations across languages. In this work, we investigate the potential of using not only visual observations but also pretrained language-image models for enabling a more efficient and robust UWT. Specifically, we develop a novel UWT method dubbed Word Alignment using Language-Image Pretraining (WALIP), which leverages visual observations via the shared embedding space of images and texts provided by CLIP models (Radford et al., 2021). WALIP has a two-step procedure. First, we retrieve word pairs with high confidences of similarity, computed using our proposed image-based fingerprints, which define the initial pivot for the word alignment. Second, we apply our robust Procrustes algorithm to estimate the linear mapping between two embedding spaces, which iteratively corrects and refines the estimated alignment. Our extensive experiments show that WALIP improves upon the state-of-the-art performance of bilingual word alignment for a few language pairs across different word embeddings and displays great robustness to the dissimilarity of language pairs or training corpora for two word embeddings.
Improved Input Reprogramming for GAN Conditioning
Feb 07, 2022

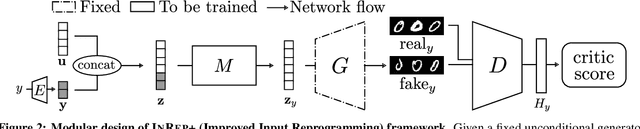
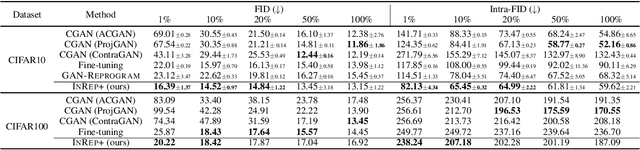
We study the GAN conditioning problem, whose goal is to convert a pretrained unconditional GAN into a conditional GAN using labeled data. We first identify and analyze three approaches to this problem -- conditional GAN training from scratch, fine-tuning, and input reprogramming. Our analysis reveals that when the amount of labeled data is small, input reprogramming performs the best. Motivated by real-world scenarios with scarce labeled data, we focus on the input reprogramming approach and carefully analyze the existing algorithm. After identifying a few critical issues of the previous input reprogramming approach, we propose a new algorithm called InRep+. Our algorithm InRep+ addresses the existing issues with the novel uses of invertible neural networks and Positive-Unlabeled (PU) learning. Via extensive experiments, we show that InRep+ outperforms all existing methods, particularly when label information is scarce, noisy, and/or imbalanced. For instance, for the task of conditioning a CIFAR10 GAN with 1% labeled data, InRep+ achieves an average Intra-FID of 76.24, whereas the second-best method achieves 114.51.
Coded-InvNet for Resilient Prediction Serving Systems
Jun 24, 2021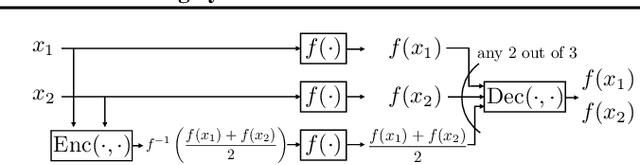

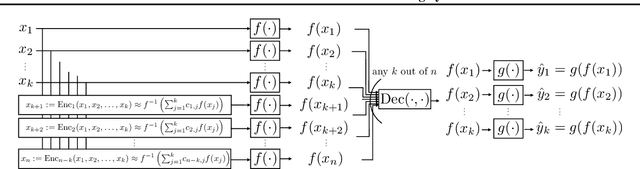

Inspired by a new coded computation algorithm for invertible functions, we propose Coded-InvNet a new approach to design resilient prediction serving systems that can gracefully handle stragglers or node failures. Coded-InvNet leverages recent findings in the deep learning literature such as invertible neural networks, Manifold Mixup, and domain translation algorithms, identifying interesting research directions that span across machine learning and systems. Our experimental results show that Coded-InvNet can outperform existing approaches, especially when the compute resource overhead is as low as 10%. For instance, without knowing which of the ten workers is going to fail, our algorithm can design a backup task so that it can correctly recover the missing prediction result with an accuracy of 85.9%, significantly outperforming the previous SOTA by 32.5%.
Constrained Deep Learning using Conditional Gradient and Applications in Computer Vision
Mar 17, 2018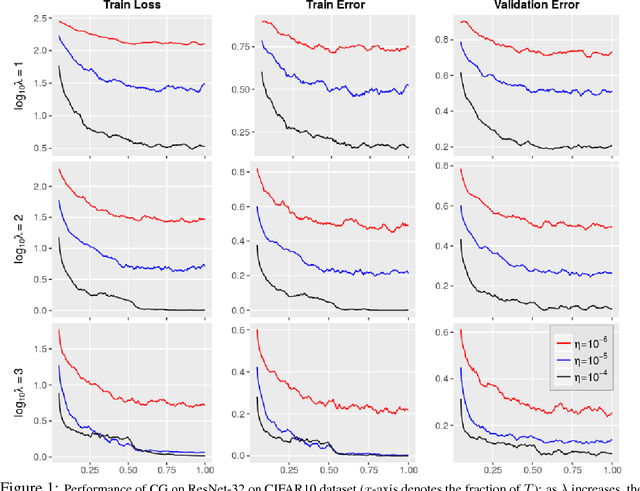
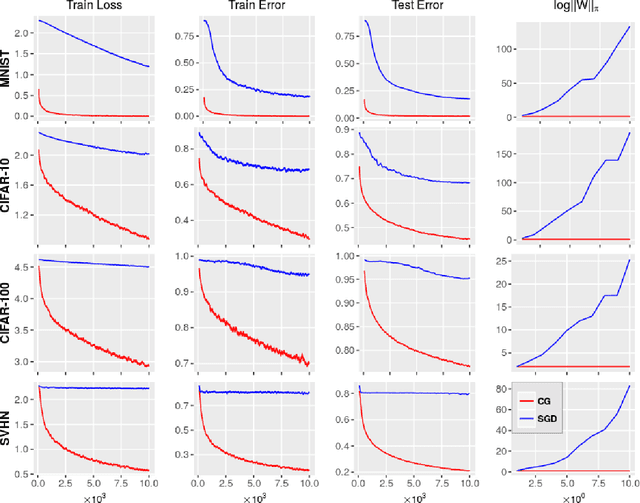
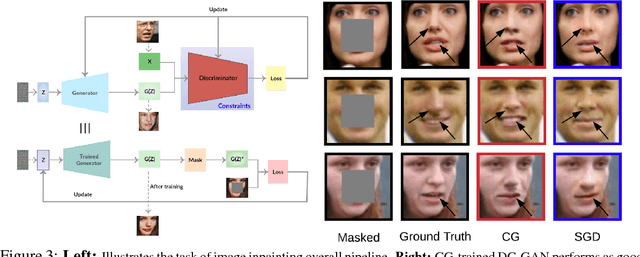
A number of results have recently demonstrated the benefits of incorporating various constraints when training deep architectures in vision and machine learning. The advantages range from guarantees for statistical generalization to better accuracy to compression. But support for general constraints within widely used libraries remains scarce and their broader deployment within many applications that can benefit from them remains under-explored. Part of the reason is that Stochastic gradient descent (SGD), the workhorse for training deep neural networks, does not natively deal with constraints with global scope very well. In this paper, we revisit a classical first order scheme from numerical optimization, Conditional Gradients (CG), that has, thus far had limited applicability in training deep models. We show via rigorous analysis how various constraints can be naturally handled by modifications of this algorithm. We provide convergence guarantees and show a suite of immediate benefits that are possible -- from training ResNets with fewer layers but better accuracy simply by substituting in our version of CG to faster training of GANs with 50% fewer epochs in image inpainting applications to provably better generalization guarantees using efficiently implementable forms of recently proposed regularizers.