 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStroke Lesion Segmentation using Multi-Stage Cross-Scale Attention
Jan 26, 2025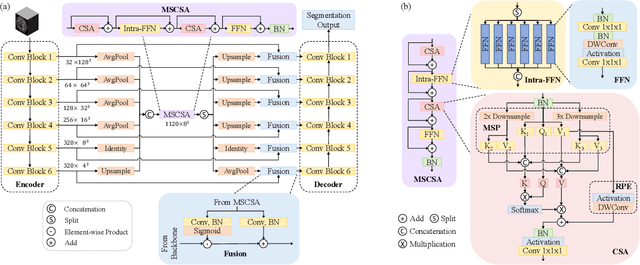
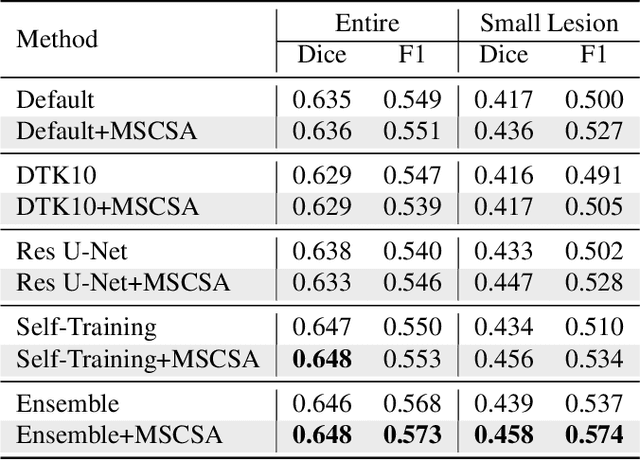
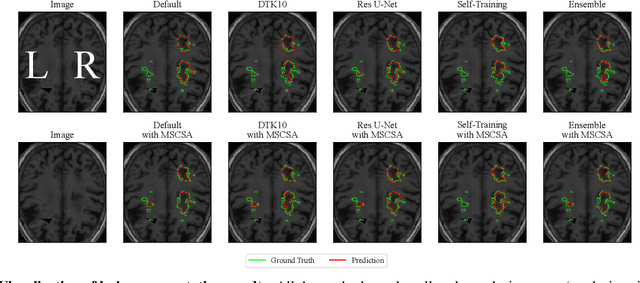
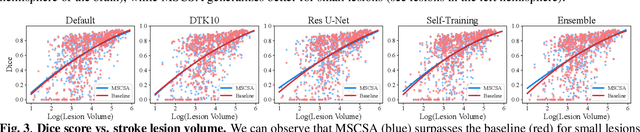
Precise characterization of stroke lesions from MRI data has immense value in prognosticating clinical and cognitive outcomes following a stroke. Manual stroke lesion segmentation is time-consuming and requires the expertise of neurologists and neuroradiologists. Often, lesions are grossly characterized for their location and overall extent using bounding boxes without specific delineation of their boundaries. While such characterization provides some clinical value, to develop a precise mechanistic understanding of the impact of lesions on post-stroke vascular contributions to cognitive impairments and dementia (VCID), the stroke lesions need to be fully segmented with accurate boundaries. This work introduces the Multi-Stage Cross-Scale Attention (MSCSA) mechanism, applied to the U-Net family, to improve the mapping between brain structural features and lesions of varying sizes. Using the Anatomical Tracings of Lesions After Stroke (ATLAS) v2.0 dataset, MSCSA outperforms all baseline methods in both Dice and F1 scores on a subset focusing on small lesions, while maintaining competitive performance across the entire dataset. Notably, the ensemble strategy incorporating MSCSA achieves the highest scores for Dice and F1 on both the full dataset and the small lesion subset. These results demonstrate the effectiveness of MSCSA in segmenting small lesions and highlight its robustness across different training schemes for large stroke lesions. Our code is available at: https://github.com/nadluru/StrokeLesSeg.
Segmenting Small Stroke Lesions with Novel Labeling Strategies
Aug 06, 2024



Deep neural networks have demonstrated exceptional efficacy in stroke lesion segmentation. However, the delineation of small lesions, critical for stroke diagnosis, remains a challenge. In this study, we propose two straightforward yet powerful approaches that can be seamlessly integrated into a variety of networks: Multi-Size Labeling (MSL) and Distance-Based Labeling (DBL), with the aim of enhancing the segmentation accuracy of small lesions. MSL divides lesion masks into various categories based on lesion volume while DBL emphasizes the lesion boundaries. Experimental evaluations on the Anatomical Tracings of Lesions After Stroke (ATLAS) v2.0 dataset showcase that an ensemble of MSL and DBL achieves consistently better or equal performance on recall (3.6% and 3.7%), F1 (2.4% and 1.5%), and Dice scores (1.3% and 0.0%) compared to the top-1 winner of the 2022 MICCAI ATLAS Challenge on both the subset only containing small lesions and the entire dataset, respectively. Notably, on the mini-lesion subset, a single MSL model surpasses the previous best ensemble strategy, with enhancements of 1.0% and 0.3% on F1 and Dice scores, respectively. Our code is available at: https://github.com/nadluru/StrokeLesSeg.
Vision Backbone Enhancement via Multi-Stage Cross-Scale Attention
Aug 14, 2023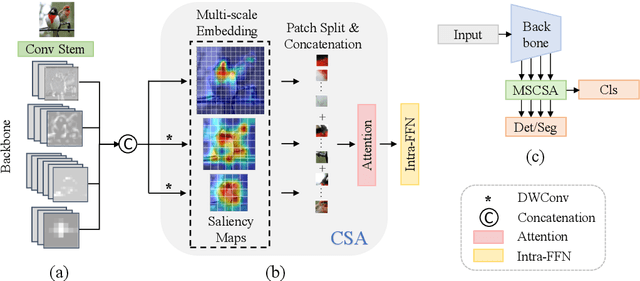



Convolutional neural networks (CNNs) and vision transformers (ViTs) have achieved remarkable success in various vision tasks. However, many architectures do not consider interactions between feature maps from different stages and scales, which may limit their performance. In this work, we propose a simple add-on attention module to overcome these limitations via multi-stage and cross-scale interactions. Specifically, the proposed Multi-Stage Cross-Scale Attention (MSCSA) module takes feature maps from different stages to enable multi-stage interactions and achieves cross-scale interactions by computing self-attention at different scales based on the multi-stage feature maps. Our experiments on several downstream tasks show that MSCSA provides a significant performance boost with modest additional FLOPs and runtime.
SimHaze: game engine simulated data for real-world dehazing
May 25, 2023Deep models have demonstrated recent success in single-image dehazing. Most prior methods consider fully supervised training and learn from paired clean and hazy images, where a hazy image is synthesized based on a clean image and its estimated depth map. This paradigm, however, can produce low-quality hazy images due to inaccurate depth estimation, resulting in poor generalization of the trained models. In this paper, we explore an alternative approach for generating paired clean-hazy images by leveraging computer graphics. Using a modern game engine, our approach renders crisp clean images and their precise depth maps, based on which high-quality hazy images can be synthesized for training dehazing models. To this end, we present SimHaze: a new synthetic haze dataset. More importantly, we show that training with SimHaze alone allows the latest dehazing models to achieve significantly better performance in comparison to previous dehazing datasets. Our dataset and code will be made publicly available.
Improved Input Reprogramming for GAN Conditioning
Feb 07, 2022

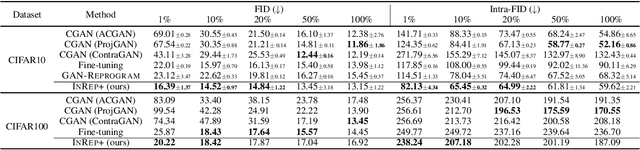
We study the GAN conditioning problem, whose goal is to convert a pretrained unconditional GAN into a conditional GAN using labeled data. We first identify and analyze three approaches to this problem -- conditional GAN training from scratch, fine-tuning, and input reprogramming. Our analysis reveals that when the amount of labeled data is small, input reprogramming performs the best. Motivated by real-world scenarios with scarce labeled data, we focus on the input reprogramming approach and carefully analyze the existing algorithm. After identifying a few critical issues of the previous input reprogramming approach, we propose a new algorithm called InRep+. Our algorithm InRep+ addresses the existing issues with the novel uses of invertible neural networks and Positive-Unlabeled (PU) learning. Via extensive experiments, we show that InRep+ outperforms all existing methods, particularly when label information is scarce, noisy, and/or imbalanced. For instance, for the task of conditioning a CIFAR10 GAN with 1% labeled data, InRep+ achieves an average Intra-FID of 76.24, whereas the second-best method achieves 114.51.
GenLabel: Mixup Relabeling using Generative Models
Jan 07, 2022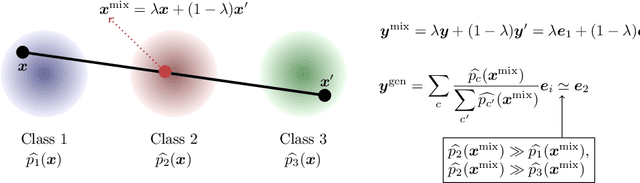

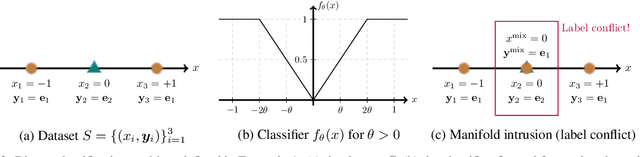

Mixup is a data augmentation method that generates new data points by mixing a pair of input data. While mixup generally improves the prediction performance, it sometimes degrades the performance. In this paper, we first identify the main causes of this phenomenon by theoretically and empirically analyzing the mixup algorithm. To resolve this, we propose GenLabel, a simple yet effective relabeling algorithm designed for mixup. In particular, GenLabel helps the mixup algorithm correctly label mixup samples by learning the class-conditional data distribution using generative models. Via extensive theoretical and empirical analysis, we show that mixup, when used together with GenLabel, can effectively resolve the aforementioned phenomenon, improving the generalization performance and the adversarial robustness.