 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruneFuse: Efficient Data Selection via Weight Pruning and Network Fusion
Mar 27, 2026Efficient data selection is crucial for enhancing the training efficiency of deep neural networks and minimizing annotation requirements. Traditional methods often face high computational costs, limiting their scalability and practical use. We introduce PruneFuse, a novel strategy that leverages pruned networks for data selection and later fuses them with the original network to optimize training. PruneFuse operates in two stages: First, it applies structured pruning to create a smaller pruned network that, due to its structural coherence with the original network, is well-suited for the data selection task. This small network is then trained and selects the most informative samples from the dataset. Second, the trained pruned network is seamlessly fused with the original network. This integration leverages the insights gained during the training of the pruned network to facilitate the learning process of the fused network while leaving room for the network to discover more robust solutions. Extensive experimentation on various datasets demonstrates that PruneFuse significantly reduces computational costs for data selection, achieves better performance than baselines, and accelerates the overall training process.
* Published in TMLR (Featured Certification). arXiv admin note: substantial text overlap with arXiv:2501.01118
Pruning-based Data Selection and Network Fusion for Efficient Deep Learning
Jan 02, 2025



Efficient data selection is essential for improving the training efficiency of deep neural networks and reducing the associated annotation costs. However, traditional methods tend to be computationally expensive, limiting their scalability and real-world applicability. We introduce PruneFuse, a novel method that combines pruning and network fusion to enhance data selection and accelerate network training. In PruneFuse, the original dense network is pruned to generate a smaller surrogate model that efficiently selects the most informative samples from the dataset. Once this iterative data selection selects sufficient samples, the insights learned from the pruned model are seamlessly integrated with the dense model through network fusion, providing an optimized initialization that accelerates training. Extensive experimentation on various datasets demonstrates that PruneFuse significantly reduces computational costs for data selection, achieves better performance than baselines, and accelerates the overall training process.
Consistency-Guided Temperature Scaling Using Style and Content Information for Out-of-Domain Calibration
Feb 22, 2024



Research interests in the robustness of deep neural networks against domain shifts have been rapidly increasing in recent years. Most existing works, however, focus on improving the accuracy of the model, not the calibration performance which is another important requirement for trustworthy AI systems. Temperature scaling (TS), an accuracy-preserving post-hoc calibration method, has been proven to be effective in in-domain settings, but not in out-of-domain (OOD) due to the difficulty in obtaining a validation set for the unseen domain beforehand. In this paper, we propose consistency-guided temperature scaling (CTS), a new temperature scaling strategy that can significantly enhance the OOD calibration performance by providing mutual supervision among data samples in the source domains. Motivated by our observation that over-confidence stemming from inconsistent sample predictions is the main obstacle to OOD calibration, we propose to guide the scaling process by taking consistencies into account in terms of two different aspects -- style and content -- which are the key components that can well-represent data samples in multi-domain settings. Experimental results demonstrate that our proposed strategy outperforms existing works, achieving superior OOD calibration performance on various datasets. This can be accomplished by employing only the source domains without compromising accuracy, making our scheme directly applicable to various trustworthy AI systems.
EvoFed: Leveraging Evolutionary Strategies for Communication-Efficient Federated Learning
Nov 13, 2023



Federated Learning (FL) is a decentralized machine learning paradigm that enables collaborative model training across dispersed nodes without having to force individual nodes to share data. However, its broad adoption is hindered by the high communication costs of transmitting a large number of model parameters. This paper presents EvoFed, a novel approach that integrates Evolutionary Strategies (ES) with FL to address these challenges. EvoFed employs a concept of 'fitness-based information sharing', deviating significantly from the conventional model-based FL. Rather than exchanging the actual updated model parameters, each node transmits a distance-based similarity measure between the locally updated model and each member of the noise-perturbed model population. Each node, as well as the server, generates an identical population set of perturbed models in a completely synchronized fashion using the same random seeds. With properly chosen noise variance and population size, perturbed models can be combined to closely reflect the actual model updated using the local dataset, allowing the transmitted similarity measures (or fitness values) to carry nearly the complete information about the model parameters. As the population size is typically much smaller than the number of model parameters, the savings in communication load is large. The server aggregates these fitness values and is able to update the global model. This global fitness vector is then disseminated back to the nodes, each of which applies the same update to be synchronized to the global model. Our analysis shows that EvoFed converges, and our experimental results validate that at the cost of increased local processing loads, EvoFed achieves performance comparable to FedAvg while reducing overall communication requirements drastically in various practical settings.
StableFDG: Style and Attention Based Learning for Federated Domain Generalization
Nov 01, 2023Traditional federated learning (FL) algorithms operate under the assumption that the data distributions at training (source domains) and testing (target domain) are the same. The fact that domain shifts often occur in practice necessitates equipping FL methods with a domain generalization (DG) capability. However, existing DG algorithms face fundamental challenges in FL setups due to the lack of samples/domains in each client's local dataset. In this paper, we propose StableFDG, a style and attention based learning strategy for accomplishing federated domain generalization, introducing two key contributions. The first is style-based learning, which enables each client to explore novel styles beyond the original source domains in its local dataset, improving domain diversity based on the proposed style sharing, shifting, and exploration strategies. Our second contribution is an attention-based feature highlighter, which captures the similarities between the features of data samples in the same class, and emphasizes the important/common characteristics to better learn the domain-invariant characteristics of each class in data-poor FL scenarios. Experimental results show that StableFDG outperforms existing baselines on various DG benchmark datasets, demonstrating its efficacy.
NEO-KD: Knowledge-Distillation-Based Adversarial Training for Robust Multi-Exit Neural Networks
Nov 01, 2023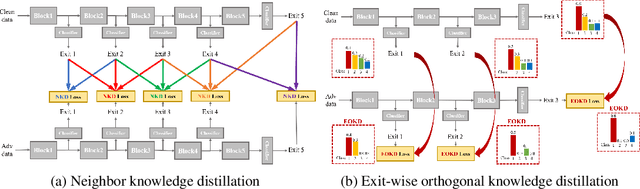
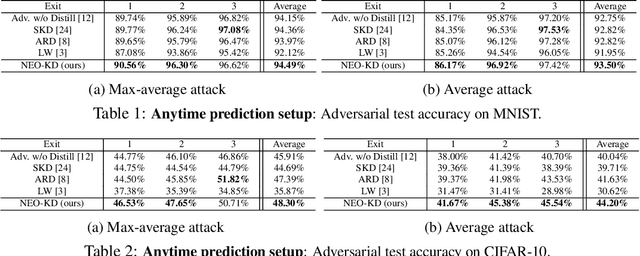
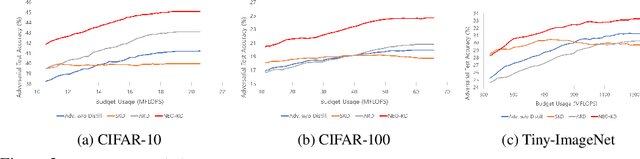
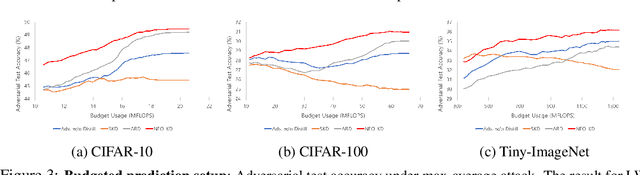
While multi-exit neural networks are regarded as a promising solution for making efficient inference via early exits, combating adversarial attacks remains a challenging problem. In multi-exit networks, due to the high dependency among different submodels, an adversarial example targeting a specific exit not only degrades the performance of the target exit but also reduces the performance of all other exits concurrently. This makes multi-exit networks highly vulnerable to simple adversarial attacks. In this paper, we propose NEO-KD, a knowledge-distillation-based adversarial training strategy that tackles this fundamental challenge based on two key contributions. NEO-KD first resorts to neighbor knowledge distillation to guide the output of the adversarial examples to tend to the ensemble outputs of neighbor exits of clean data. NEO-KD also employs exit-wise orthogonal knowledge distillation for reducing adversarial transferability across different submodels. The result is a significantly improved robustness against adversarial attacks. Experimental results on various datasets/models show that our method achieves the best adversarial accuracy with reduced computation budgets, compared to the baselines relying on existing adversarial training or knowledge distillation techniques for multi-exit networks.
Test-Time Style Shifting: Handling Arbitrary Styles in Domain Generalization
Jun 13, 2023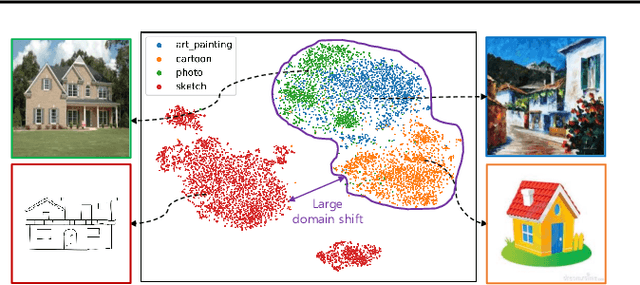

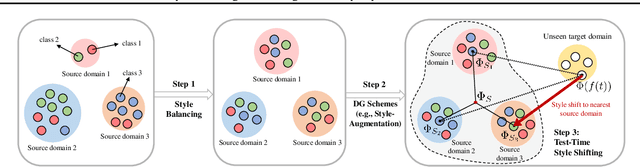
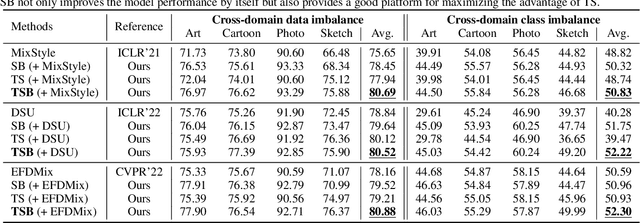
In domain generalization (DG), the target domain is unknown when the model is being trained, and the trained model should successfully work on an arbitrary (and possibly unseen) target domain during inference. This is a difficult problem, and despite active studies in recent years, it remains a great challenge. In this paper, we take a simple yet effective approach to tackle this issue. We propose test-time style shifting, which shifts the style of the test sample (that has a large style gap with the source domains) to the nearest source domain that the model is already familiar with, before making the prediction. This strategy enables the model to handle any target domains with arbitrary style statistics, without additional model update at test-time. Additionally, we propose style balancing, which provides a great platform for maximizing the advantage of test-time style shifting by handling the DG-specific imbalance issues. The proposed ideas are easy to implement and successfully work in conjunction with various other DG schemes. Experimental results on different datasets show the effectiveness of our methods.
SplitGP: Achieving Both Generalization and Personalization in Federated Learning
Dec 16, 2022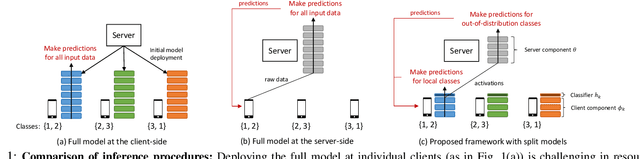
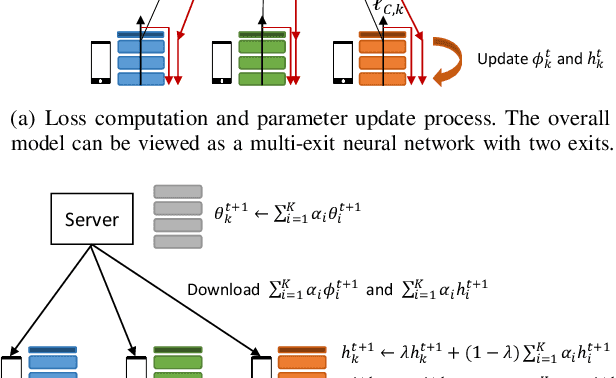
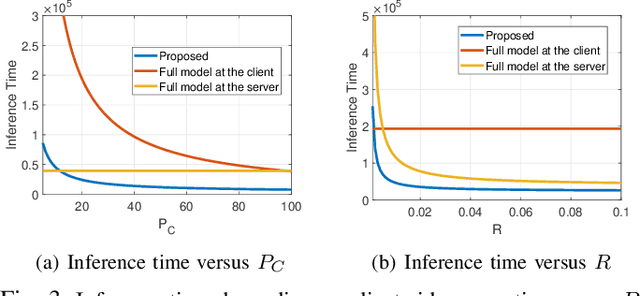
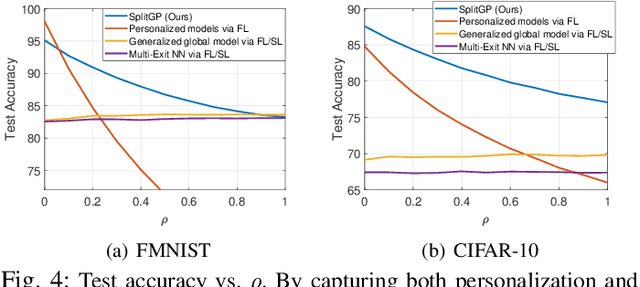
A fundamental challenge to providing edge-AI services is the need for a machine learning (ML) model that achieves personalization (i.e., to individual clients) and generalization (i.e., to unseen data) properties concurrently. Existing techniques in federated learning (FL) have encountered a steep tradeoff between these objectives and impose large computational requirements on edge devices during training and inference. In this paper, we propose SplitGP, a new split learning solution that can simultaneously capture generalization and personalization capabilities for efficient inference across resource-constrained clients (e.g., mobile/IoT devices). Our key idea is to split the full ML model into client-side and server-side components, and impose different roles to them: the client-side model is trained to have strong personalization capability optimized to each client's main task, while the server-side model is trained to have strong generalization capability for handling all clients' out-of-distribution tasks. We analytically characterize the convergence behavior of SplitGP, revealing that all client models approach stationary points asymptotically. Further, we analyze the inference time in SplitGP and provide bounds for determining model split ratios. Experimental results show that SplitGP outperforms existing baselines by wide margins in inference time and test accuracy for varying amounts of out-of-distribution samples.
Locally Supervised Learning with Periodic Global Guidance
Aug 01, 2022
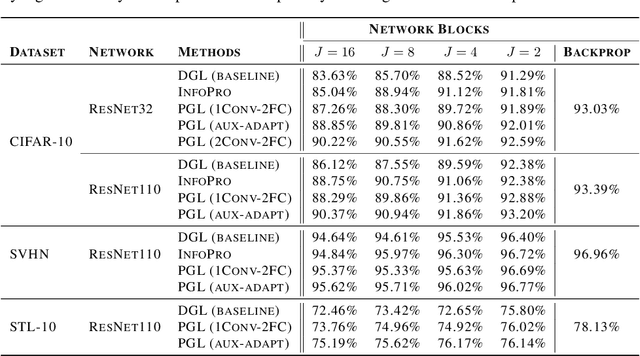
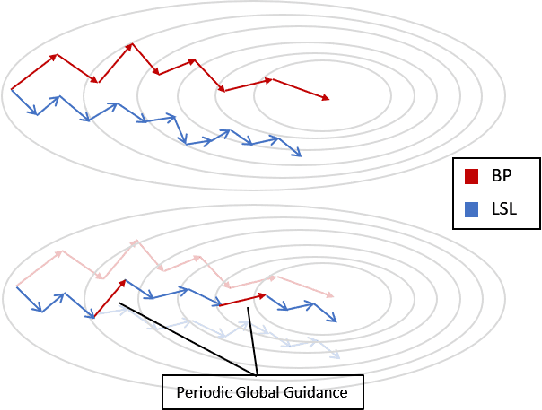

Locally supervised learning aims to train a neural network based on a local estimation of the global loss function at each decoupled module of the network. Auxiliary networks are typically appended to the modules to approximate the gradient updates based on the greedy local losses. Despite being advantageous in terms of parallelism and reduced memory consumption, this paradigm of training severely degrades the generalization performance of neural networks. In this paper, we propose Periodically Guided local Learning (PGL), which reinstates the global objective repetitively into the local-loss based training of neural networks primarily to enhance the model's generalization capability. We show that a simple periodic guidance scheme begets significant performance gains while having a low memory footprint. We conduct extensive experiments on various datasets and networks to demonstrate the effectiveness of PGL, especially in the configuration with numerous decoupled modules.
Task-Adaptive Feature Transformer with Semantic Enrichment for Few-Shot Segmentation
Feb 14, 2022
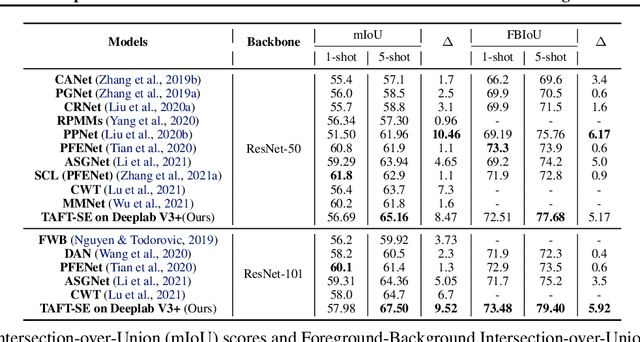

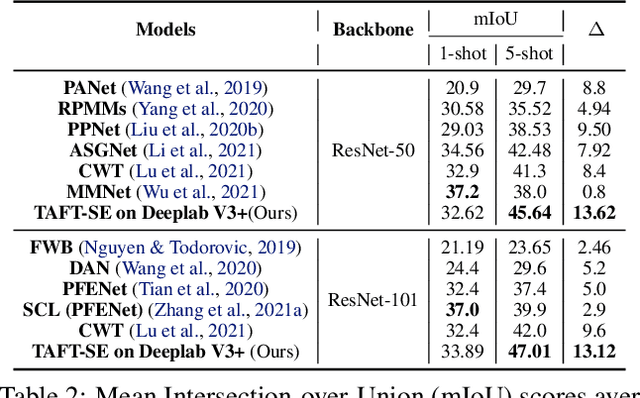
Few-shot learning allows machines to classify novel classes using only a few labeled samples. Recently, few-shot segmentation aiming at semantic segmentation on low sample data has also seen great interest. In this paper, we propose a learnable module that can be placed on top of existing segmentation networks for performing few-shot segmentation. This module, called the task-adaptive feature transformer (TAFT), linearly transforms task-specific high-level features to a set of task agnostic features well-suited to conducting few-shot segmentation. The task-conditioned feature transformation allows an effective utilization of the semantic information in novel classes to generate tight segmentation masks. We also propose a semantic enrichment (SE) module that utilizes a pixel-wise attention module for high-level feature and an auxiliary loss from an auxiliary segmentation network conducting the semantic segmentation for all training classes. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets confirm that the added modules successfully extend the capability of existing segmentators to yield highly competitive few-shot segmentation performances.