 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruneFuse: Efficient Data Selection via Weight Pruning and Network Fusion
Mar 27, 2026Efficient data selection is crucial for enhancing the training efficiency of deep neural networks and minimizing annotation requirements. Traditional methods often face high computational costs, limiting their scalability and practical use. We introduce PruneFuse, a novel strategy that leverages pruned networks for data selection and later fuses them with the original network to optimize training. PruneFuse operates in two stages: First, it applies structured pruning to create a smaller pruned network that, due to its structural coherence with the original network, is well-suited for the data selection task. This small network is then trained and selects the most informative samples from the dataset. Second, the trained pruned network is seamlessly fused with the original network. This integration leverages the insights gained during the training of the pruned network to facilitate the learning process of the fused network while leaving room for the network to discover more robust solutions. Extensive experimentation on various datasets demonstrates that PruneFuse significantly reduces computational costs for data selection, achieves better performance than baselines, and accelerates the overall training process.
* Published in TMLR (Featured Certification). arXiv admin note: substantial text overlap with arXiv:2501.01118
Pruning-based Data Selection and Network Fusion for Efficient Deep Learning
Jan 02, 2025



Efficient data selection is essential for improving the training efficiency of deep neural networks and reducing the associated annotation costs. However, traditional methods tend to be computationally expensive, limiting their scalability and real-world applicability. We introduce PruneFuse, a novel method that combines pruning and network fusion to enhance data selection and accelerate network training. In PruneFuse, the original dense network is pruned to generate a smaller surrogate model that efficiently selects the most informative samples from the dataset. Once this iterative data selection selects sufficient samples, the insights learned from the pruned model are seamlessly integrated with the dense model through network fusion, providing an optimized initialization that accelerates training. Extensive experimentation on various datasets demonstrates that PruneFuse significantly reduces computational costs for data selection, achieves better performance than baselines, and accelerates the overall training process.
EvoFed: Leveraging Evolutionary Strategies for Communication-Efficient Federated Learning
Nov 13, 2023



Federated Learning (FL) is a decentralized machine learning paradigm that enables collaborative model training across dispersed nodes without having to force individual nodes to share data. However, its broad adoption is hindered by the high communication costs of transmitting a large number of model parameters. This paper presents EvoFed, a novel approach that integrates Evolutionary Strategies (ES) with FL to address these challenges. EvoFed employs a concept of 'fitness-based information sharing', deviating significantly from the conventional model-based FL. Rather than exchanging the actual updated model parameters, each node transmits a distance-based similarity measure between the locally updated model and each member of the noise-perturbed model population. Each node, as well as the server, generates an identical population set of perturbed models in a completely synchronized fashion using the same random seeds. With properly chosen noise variance and population size, perturbed models can be combined to closely reflect the actual model updated using the local dataset, allowing the transmitted similarity measures (or fitness values) to carry nearly the complete information about the model parameters. As the population size is typically much smaller than the number of model parameters, the savings in communication load is large. The server aggregates these fitness values and is able to update the global model. This global fitness vector is then disseminated back to the nodes, each of which applies the same update to be synchronized to the global model. Our analysis shows that EvoFed converges, and our experimental results validate that at the cost of increased local processing loads, EvoFed achieves performance comparable to FedAvg while reducing overall communication requirements drastically in various practical settings.
Locally Supervised Learning with Periodic Global Guidance
Aug 01, 2022
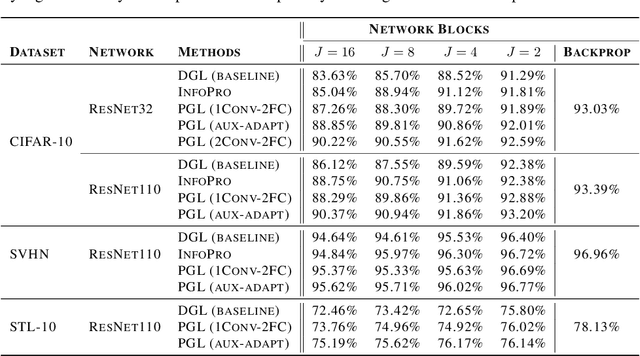
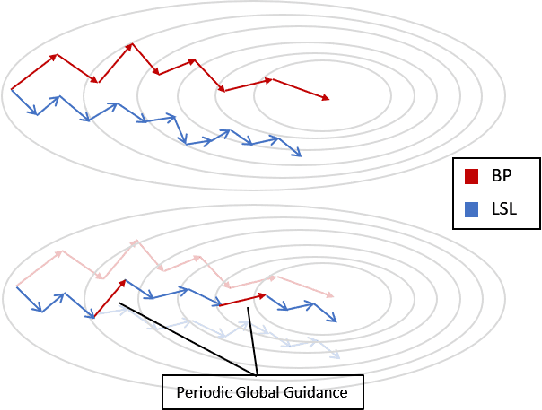

Locally supervised learning aims to train a neural network based on a local estimation of the global loss function at each decoupled module of the network. Auxiliary networks are typically appended to the modules to approximate the gradient updates based on the greedy local losses. Despite being advantageous in terms of parallelism and reduced memory consumption, this paradigm of training severely degrades the generalization performance of neural networks. In this paper, we propose Periodically Guided local Learning (PGL), which reinstates the global objective repetitively into the local-loss based training of neural networks primarily to enhance the model's generalization capability. We show that a simple periodic guidance scheme begets significant performance gains while having a low memory footprint. We conduct extensive experiments on various datasets and networks to demonstrate the effectiveness of PGL, especially in the configuration with numerous decoupled modules.