 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Multimodal Fusion for Time Series: Auxiliary Modalities Need Constrained Fusion
Mar 23, 2026Recent advances in multimodal learning have motivated the integration of auxiliary modalities such as text or vision into time series (TS) forecasting. However, most existing methods provide limited gains, often improving performance only in specific datasets or relying on architecture-specific designs that limit generalization. In this paper, we show that multimodal models with naive fusion strategies (e.g., simple addition or concatenation) often underperform unimodal TS models, which we attribute to the uncontrolled integration of auxiliary modalities which may introduce irrelevant information. Motivated by this observation, we explore various constrained fusion methods designed to control such integration and find that they consistently outperform naive fusion methods. Furthermore, we propose Controlled Fusion Adapter (CFA), a simple plug-in method that enables controlled cross-modal interactions without modifying the TS backbone, integrating only relevant textual information aligned with TS dynamics. CFA employs low-rank adapters to filter irrelevant textual information before fusing it into temporal representations. We conduct over 20K experiments across various datasets and TS/text models, demonstrating the effectiveness of the constrained fusion methods including CFA. Code is publicly available at: https://github.com/seunghan96/cfa/.
Cross-RAG: Zero-Shot Retrieval-Augmented Time Series Forecasting via Cross-Attention
Mar 16, 2026Recent advances in time series foundation models (TSFMs) demonstrate strong expressive capacity through large-scale pretraining across diverse time series domains. Zero-shot time series forecasting with TSFMs, however, exhibits limited generalization to unseen datasets, which retrieval-augmented forecasting addresses by leveraging an external knowledge base. Existing approaches rely on a fixed number of retrieved samples that may introduce irrelevant information. To this end, we propose Cross-RAG, a zero-shot retrieval-augmented forecasting framework that selectively attends to query-relevant retrieved samples. Cross-RAG models input-level relevance between the query and retrieved samples via query-retrieval cross-attention, while jointly incorporating information from the query and retrieved samples. Extensive experiments demonstrate that Cross-RAG consistently improves zero-shot forecasting performance across various TSFMs and RAG methods, and additional analyses confirm its effectiveness across diverse retrieval scenarios. Code is available at https://github.com/seunghan96/cross-rag/.
FinTexTS: Financial Text-Paired Time-Series Dataset via Semantic-Based and Multi-Level Pairing
Mar 03, 2026The financial domain involves a variety of important time-series problems. Recently, time-series analysis methods that jointly leverage textual and numerical information have gained increasing attention. Accordingly, numerous efforts have been made to construct text-paired time-series datasets in the financial domain. However, financial markets are characterized by complex interdependencies, in which a company's stock price is influenced not only by company-specific events but also by events in other companies and broader macroeconomic factors. Existing approaches that pair text with financial time-series data based on simple keyword matching often fail to capture such complex relationships. To address this limitation, we propose a semantic-based and multi-level pairing framework. Specifically, we extract company-specific context for the target company from SEC filings and apply an embedding-based matching mechanism to retrieve semantically relevant news articles based on this context. Furthermore, we classify news articles into four levels (macro-level, sector-level, related company-level, and target-company level) using large language models (LLMs), enabling multi-level pairing of news articles with the target company. Applying this framework to publicly-available news datasets, we construct \textbf{FinTexTS}, a new large-scale text-paired stock price dataset. Experimental results on \textbf{FinTexTS} demonstrate the effectiveness of our semantic-based and multi-level pairing strategy in stock price forecasting. In addition to publicly-available news underlying \textbf{FinTexTS}, we show that applying our method to proprietary yet carefully curated news sources leads to higher-quality paired data and improved stock price forecasting performance.
Adaptive Information Routing for Multimodal Time Series Forecasting
Dec 23, 2025Time series forecasting is a critical task for artificial intelligence with numerous real-world applications. Traditional approaches primarily rely on historical time series data to predict the future values. However, in practical scenarios, this is often insufficient for accurate predictions due to the limited information available. To address this challenge, multimodal time series forecasting methods which incorporate additional data modalities, mainly text data, alongside time series data have been explored. In this work, we introduce the Adaptive Information Routing (AIR) framework, a novel approach for multimodal time series forecasting. Unlike existing methods that treat text data on par with time series data as interchangeable auxiliary features for forecasting, AIR leverages text information to dynamically guide the time series model by controlling how and to what extent multivariate time series information should be combined. We also present a text-refinement pipeline that employs a large language model to convert raw text data into a form suitable for multimodal forecasting, and we introduce a benchmark that facilitates multimodal forecasting experiments based on this pipeline. Experiment results with the real world market data such as crude oil price and exchange rates demonstrate that AIR effectively modulates the behavior of the time series model using textual inputs, significantly enhancing forecasting accuracy in various time series forecasting tasks.
Task-Adaptive Feature Transformer with Semantic Enrichment for Few-Shot Segmentation
Feb 14, 2022
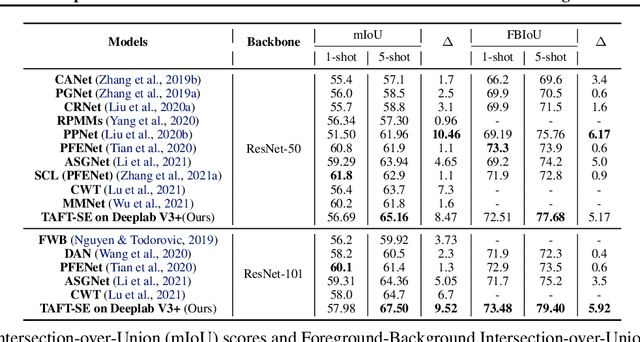

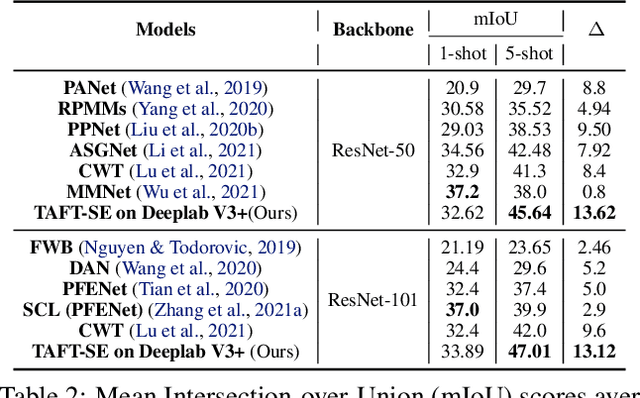
Few-shot learning allows machines to classify novel classes using only a few labeled samples. Recently, few-shot segmentation aiming at semantic segmentation on low sample data has also seen great interest. In this paper, we propose a learnable module that can be placed on top of existing segmentation networks for performing few-shot segmentation. This module, called the task-adaptive feature transformer (TAFT), linearly transforms task-specific high-level features to a set of task agnostic features well-suited to conducting few-shot segmentation. The task-conditioned feature transformation allows an effective utilization of the semantic information in novel classes to generate tight segmentation masks. We also propose a semantic enrichment (SE) module that utilizes a pixel-wise attention module for high-level feature and an auxiliary loss from an auxiliary segmentation network conducting the semantic segmentation for all training classes. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets confirm that the added modules successfully extend the capability of existing segmentators to yield highly competitive few-shot segmentation performances.
Task-Adaptive Feature Transformer for Few-Shot Segmentation
Oct 22, 2020
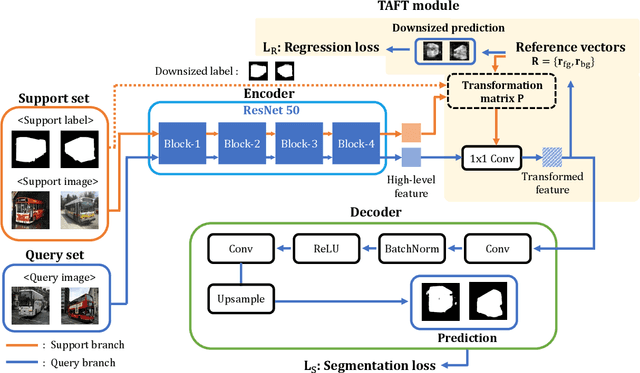
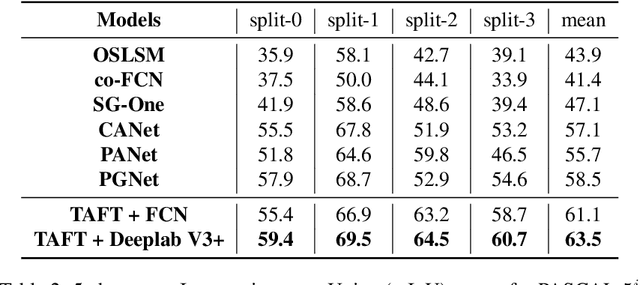
Few-shot learning allows machines to classify novel classes using only a few labeled samples. Recently, few-shot segmentation aiming at semantic segmentation on low sample data has also seen great interest. In this paper, we propose a learnable module for few-shot segmentation, the task-adaptive feature transformer (TAFT). TAFT linearly transforms task-specific high-level features to a set of task-agnostic features well-suited to the segmentation job. Using this task-conditioned feature transformation, the model is shown to effectively utilize the semantic information in novel classes to generate tight segmentation masks. The proposed TAFT module can be easily plugged into existing semantic segmentation algorithms to achieve few-shot segmentation capability with only a few added parameters. We combine TAFT with Deeplab V3+, a well-known segmentation architecture; experiments on the PASCAL-$5^i$ dataset confirm that this combination successfully adds few-shot learning capability to the segmentation algorithm, achieving the state-of-the-art few-shot segmentation performance in some key representative cases.
XtarNet: Learning to Extract Task-Adaptive Representation for Incremental Few-Shot Learning
Mar 19, 2020
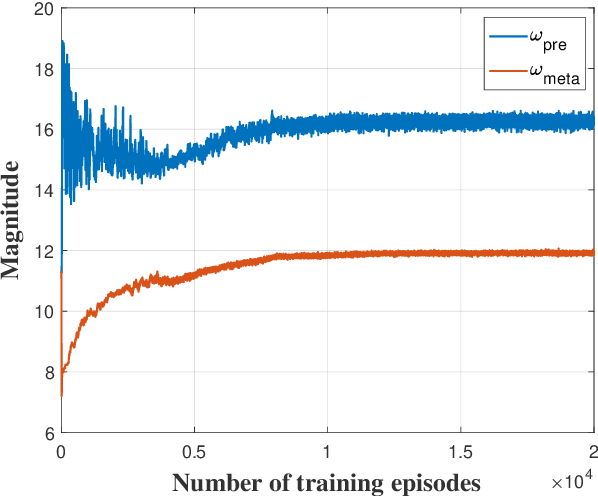

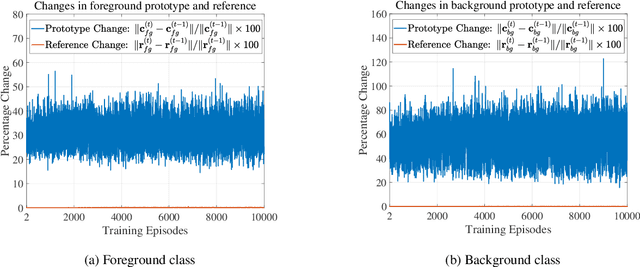
Learning novel concepts while preserving prior knowledge is a long-standing challenge in machine learning. The challenge gets greater when a novel task is given with only a few labeled examples, a problem known as incremental few-shot learning. We propose XtarNet, which learns to extract task-adaptive representation (TAR) for facilitating incremental few-shot learning. The method utilizes a backbone network pretrained on a set of base categories while also employing additional modules that are meta-trained across episodes. Given a new task, the novel feature extracted from the meta-trained modules is mixed with the base feature obtained from the pretrained model. The process of combining two different features provides TAR and is also controlled by meta-trained modules. The TAR contains effective information for classifying both novel and base categories. The base and novel classifiers quickly adapt to a given task by utilizing the TAR. Experiments on standard image datasets indicate that XtarNet achieves state-of-the-art incremental few-shot learning performance. The concept of TAR can also be used in conjunction with existing incremental few-shot learning methods; extensive simulation results in fact show that applying TAR enhances the known methods significantly.
CAFENet: Class-Agnostic Few-Shot Edge Detection Network
Mar 18, 2020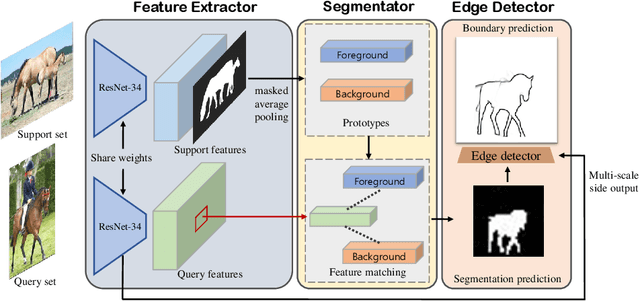
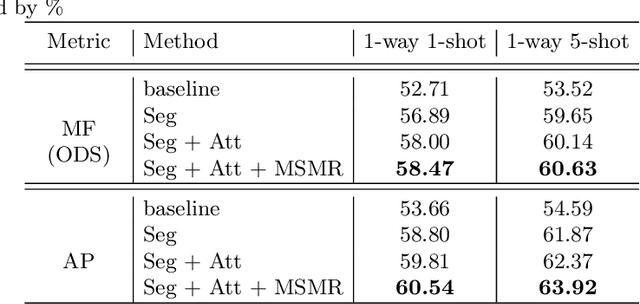

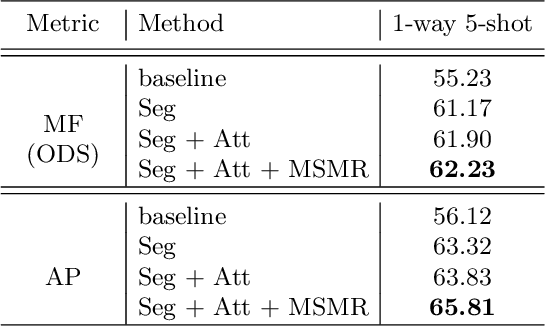
We tackle a novel few-shot learning challenge, which we call few-shot semantic edge detection, aiming to localize crisp boundaries of novel categories using only a few labeled samples. We also present a Class-Agnostic Few-shot Edge detection Network (CAFENet) based on meta-learning strategy. CAFENet employs a semantic segmentation module in small-scale to compensate for lack of semantic information in edge labels. The predicted segmentation mask is used to generate an attention map to highlight the target object region, and make the decoder module concentrate on that region. We also propose a new regularization method based on multi-split matching. In meta-training, the metric-learning problem with high-dimensional vectors are divided into small subproblems with low-dimensional sub-vectors. Since there is no existing dataset for few-shot semantic edge detection, we construct two new datasets, FSE-1000 and SBD-$5^i$, and evaluate the performance of the proposed CAFENet on them. Extensive simulation results confirm the performance merits of the techniques adopted in CAFENet.
Task-Adaptive Clustering for Semi-Supervised Few-Shot Classification
Mar 18, 2020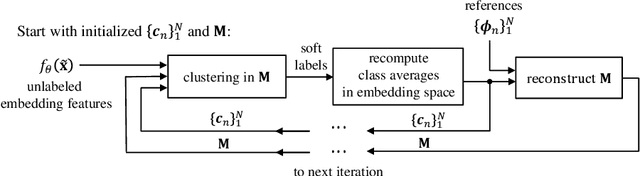
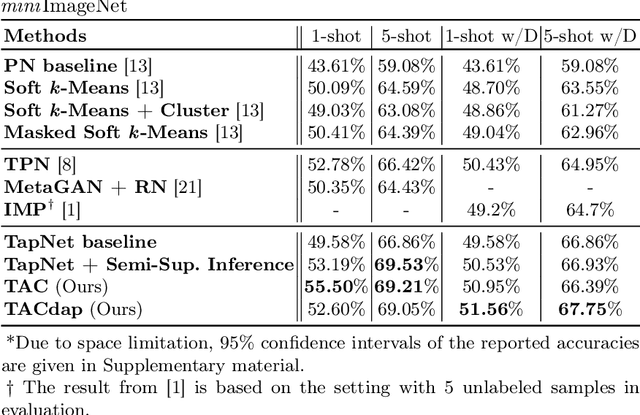
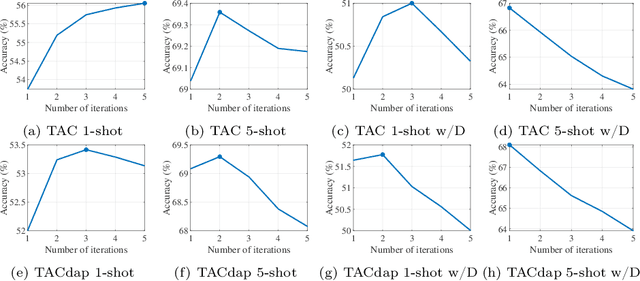
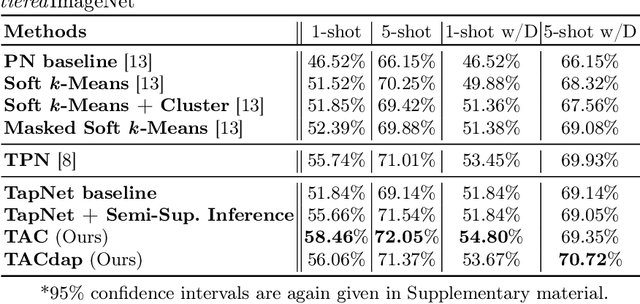
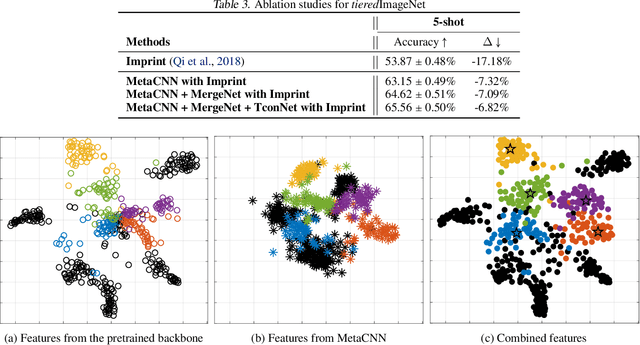
Few-shot learning aims to handle previously unseen tasks using only a small amount of new training data. In preparing (or meta-training) a few-shot learner, however, massive labeled data are necessary. In the real world, unfortunately, labeled data are expensive and/or scarce. In this work, we propose a few-shot learner that can work well under the semi-supervised setting where a large portion of training data is unlabeled. Our method employs explicit task-conditioning in which unlabeled sample clustering for the current task takes place in a new projection space different from the embedding feature space. The conditioned clustering space is linearly constructed so as to quickly close the gap between the class centroids for the current task and the independent per-class reference vectors meta-trained across tasks. In a more general setting, our method introduces a concept of controlling the degree of task-conditioning for meta-learning: the amount of task-conditioning varies with the number of repetitive updates for the clustering space. Extensive simulation results based on the miniImageNet and tieredImageNet datasets show state-of-the-art semi-supervised few-shot classification performance of the proposed method. Simulation results also indicate that the proposed task-adaptive clustering shows graceful degradation with a growing number of distractor samples, i.e., unlabeled sample images coming from outside the candidate classes.
TapNet: Neural Network Augmented with Task-Adaptive Projection for Few-Shot Learning
May 16, 2019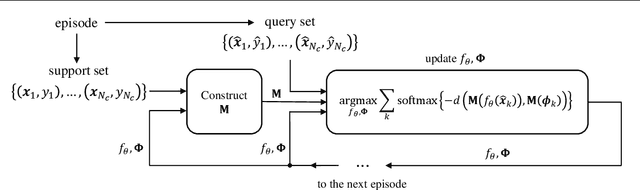
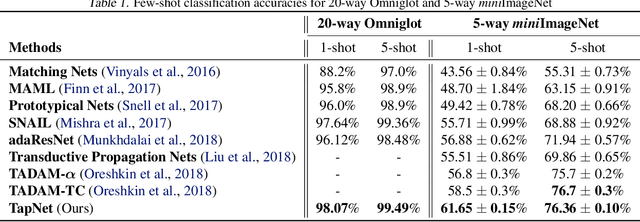

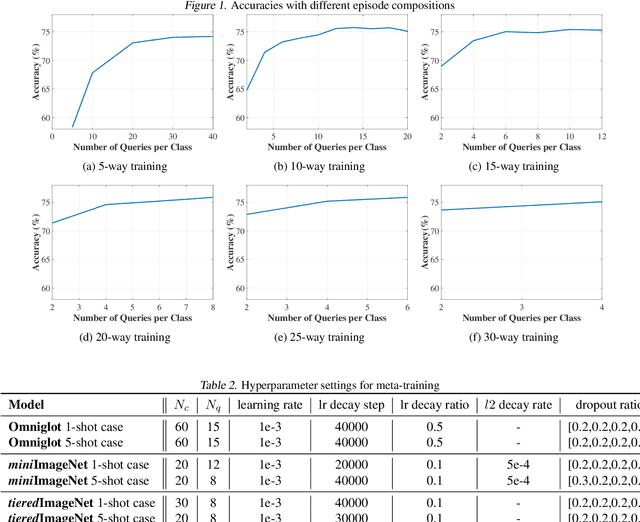
Handling previously unseen tasks after given only a few training examples continues to be a tough challenge in machine learning. We propose TapNets, neural networks augmented with task-adaptive projection for improved few-shot learning. Here, employing a meta-learning strategy with episode-based training, a network and a set of per-class reference vectors are learned across widely varying tasks. At the same time, for every episode, features in the embedding space are linearly projected into a new space as a form of quick task-specific conditioning. The training loss is obtained based on a distance metric between the query and the reference vectors in the projection space. Excellent generalization results in this way. When tested on the Omniglot, miniImageNet and tieredImageNet datasets, we obtain state of the art classification accuracies under various few-shot scenarios.