 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flat Minima Perspective on Understanding Augmentations and Model Robustness
May 30, 2025Model robustness indicates a model's capability to generalize well on unforeseen distributional shifts, including data corruption, adversarial attacks, and domain shifts. Data augmentation is one of the prevalent and effective ways to enhance robustness. Despite the great success of augmentations in different fields, a general theoretical understanding of their efficacy in improving model robustness is lacking. We offer a unified theoretical framework to clarify how augmentations can enhance model robustness through the lens of loss surface flatness and PAC generalization bound. Our work diverges from prior studies in that our analysis i) broadly encompasses much of the existing augmentation methods, and ii) is not limited to specific types of distribution shifts like adversarial attacks. We confirm our theories through simulations on the existing common corruption and adversarial robustness benchmarks based on the CIFAR and ImageNet datasets, as well as domain generalization benchmarks including PACS and OfficeHome.
Understanding Flatness in Generative Models: Its Role and Benefits
Mar 14, 2025Flat minima, known to enhance generalization and robustness in supervised learning, remain largely unexplored in generative models. In this work, we systematically investigate the role of loss surface flatness in generative models, both theoretically and empirically, with a particular focus on diffusion models. We establish a theoretical claim that flatter minima improve robustness against perturbations in target prior distributions, leading to benefits such as reduced exposure bias -- where errors in noise estimation accumulate over iterations -- and significantly improved resilience to model quantization, preserving generative performance even under strong quantization constraints. We further observe that Sharpness-Aware Minimization (SAM), which explicitly controls the degree of flatness, effectively enhances flatness in diffusion models, whereas other well-known methods such as Stochastic Weight Averaging (SWA) and Exponential Moving Average (EMA), which promote flatness indirectly via ensembling, are less effective. Through extensive experiments on CIFAR-10, LSUN Tower, and FFHQ, we demonstrate that flat minima in diffusion models indeed improves not only generative performance but also robustness.
Benchmarking Federated Learning for Semantic Datasets: Federated Scene Graph Generation
Dec 11, 2024Federated learning (FL) has recently garnered attention as a data-decentralized training framework that enables the learning of deep models from locally distributed samples while keeping data privacy. Built upon the framework, immense efforts have been made to establish FL benchmarks, which provide rigorous evaluation settings that control data heterogeneity across clients. Prior efforts have mainly focused on handling relatively simple classification tasks, where each sample is annotated with a one-hot label, such as MNIST, CIFAR, LEAF benchmark, etc. However, little attention has been paid to demonstrating an FL benchmark that handles complicated semantics, where each sample encompasses diverse semantic information from multiple labels, such as Panoptic Scene Graph Generation (PSG) with objects, subjects, and relations between them. Because the existing benchmark is designed to distribute data in a narrow view of a single semantic, e.g., a one-hot label, managing the complicated semantic heterogeneity across clients when formalizing FL benchmarks is non-trivial. In this paper, we propose a benchmark process to establish an FL benchmark with controllable semantic heterogeneity across clients: two key steps are i) data clustering with semantics and ii) data distributing via controllable semantic heterogeneity across clients. As a proof of concept, we first construct a federated PSG benchmark, demonstrating the efficacy of the existing PSG methods in an FL setting with controllable semantic heterogeneity of scene graphs. We also present the effectiveness of our benchmark by applying robust federated learning algorithms to data heterogeneity to show increased performance. Our code is available at https://github.com/Seung-B/FL-PSG.
XB-MAML: Learning Expandable Basis Parameters for Effective Meta-Learning with Wide Task Coverage
Mar 11, 2024Meta-learning, which pursues an effective initialization model, has emerged as a promising approach to handling unseen tasks. However, a limitation remains to be evident when a meta-learner tries to encompass a wide range of task distribution, e.g., learning across distinctive datasets or domains. Recently, a group of works has attempted to employ multiple model initializations to cover widely-ranging tasks, but they are limited in adaptively expanding initializations. We introduce XB-MAML, which learns expandable basis parameters, where they are linearly combined to form an effective initialization to a given task. XB-MAML observes the discrepancy between the vector space spanned by the basis and fine-tuned parameters to decide whether to expand the basis. Our method surpasses the existing works in the multi-domain meta-learning benchmarks and opens up new chances of meta-learning for obtaining the diverse inductive bias that can be combined to stretch toward the effective initialization for diverse unseen tasks.
POEM: Polarization of Embeddings for Domain-Invariant Representations
May 22, 2023Handling out-of-distribution samples is a long-lasting challenge for deep visual models. In particular, domain generalization (DG) is one of the most relevant tasks that aims to train a model with a generalization capability on novel domains. Most existing DG approaches share the same philosophy to minimize the discrepancy between domains by finding the domain-invariant representations. On the contrary, our proposed method called POEM acquires a strong DG capability by learning domain-invariant and domain-specific representations and polarizing them. Specifically, POEM cotrains category-classifying and domain-classifying embeddings while regularizing them to be orthogonal via minimizing the cosine-similarity between their features, i.e., the polarization of embeddings. The clear separation of embeddings suppresses domain-specific features in the domain-invariant embeddings. The concept of POEM shows a unique direction to enhance the domain robustness of representations that brings considerable and consistent performance gains when combined with existing DG methods. Extensive simulation results in popular DG benchmarks with the PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet datasets show that POEM indeed facilitates the category-classifying embedding to be more domain-invariant.
Task-Adaptive Feature Transformer with Semantic Enrichment for Few-Shot Segmentation
Feb 14, 2022
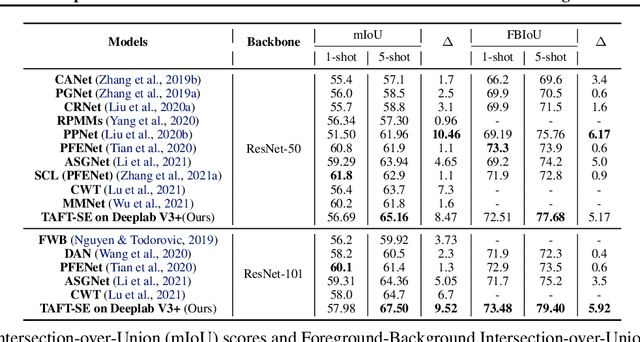

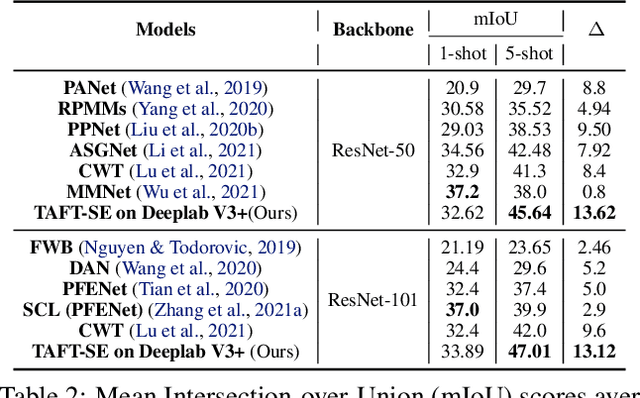
Few-shot learning allows machines to classify novel classes using only a few labeled samples. Recently, few-shot segmentation aiming at semantic segmentation on low sample data has also seen great interest. In this paper, we propose a learnable module that can be placed on top of existing segmentation networks for performing few-shot segmentation. This module, called the task-adaptive feature transformer (TAFT), linearly transforms task-specific high-level features to a set of task agnostic features well-suited to conducting few-shot segmentation. The task-conditioned feature transformation allows an effective utilization of the semantic information in novel classes to generate tight segmentation masks. We also propose a semantic enrichment (SE) module that utilizes a pixel-wise attention module for high-level feature and an auxiliary loss from an auxiliary segmentation network conducting the semantic segmentation for all training classes. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets confirm that the added modules successfully extend the capability of existing segmentators to yield highly competitive few-shot segmentation performances.
XtarNet: Learning to Extract Task-Adaptive Representation for Incremental Few-Shot Learning
Mar 19, 2020
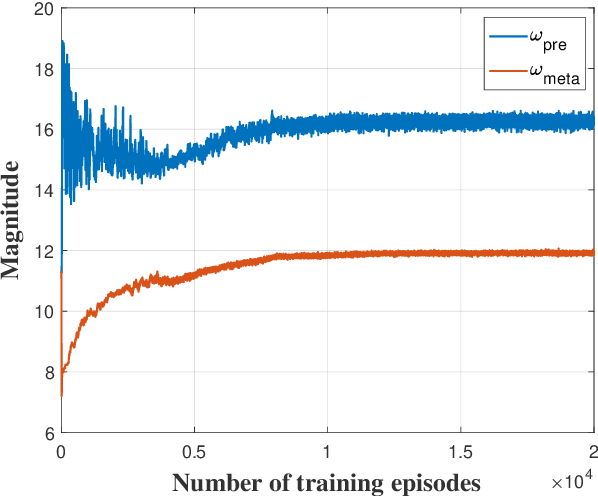

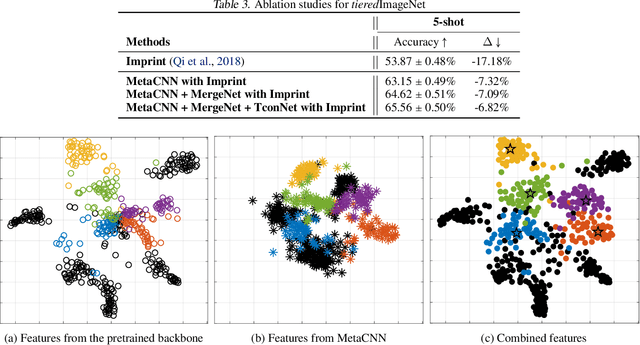
Learning novel concepts while preserving prior knowledge is a long-standing challenge in machine learning. The challenge gets greater when a novel task is given with only a few labeled examples, a problem known as incremental few-shot learning. We propose XtarNet, which learns to extract task-adaptive representation (TAR) for facilitating incremental few-shot learning. The method utilizes a backbone network pretrained on a set of base categories while also employing additional modules that are meta-trained across episodes. Given a new task, the novel feature extracted from the meta-trained modules is mixed with the base feature obtained from the pretrained model. The process of combining two different features provides TAR and is also controlled by meta-trained modules. The TAR contains effective information for classifying both novel and base categories. The base and novel classifiers quickly adapt to a given task by utilizing the TAR. Experiments on standard image datasets indicate that XtarNet achieves state-of-the-art incremental few-shot learning performance. The concept of TAR can also be used in conjunction with existing incremental few-shot learning methods; extensive simulation results in fact show that applying TAR enhances the known methods significantly.
Task-Adaptive Clustering for Semi-Supervised Few-Shot Classification
Mar 18, 2020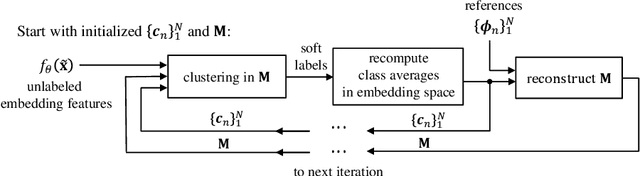
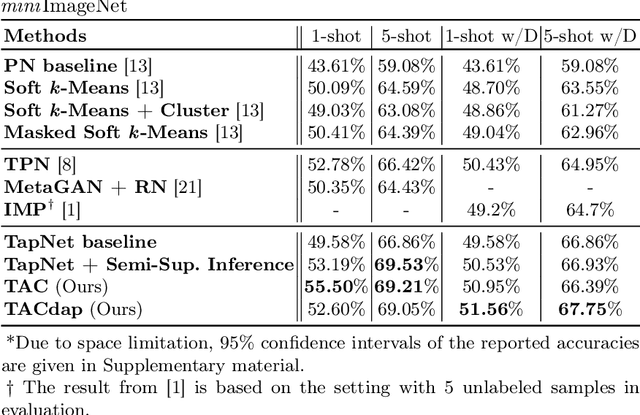
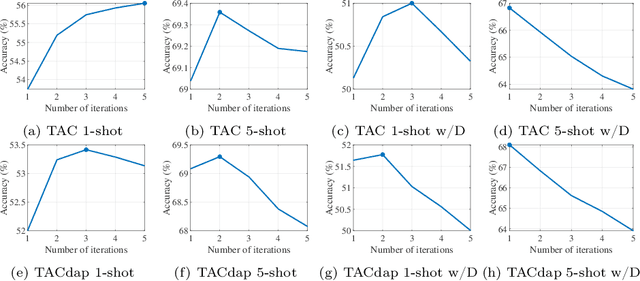
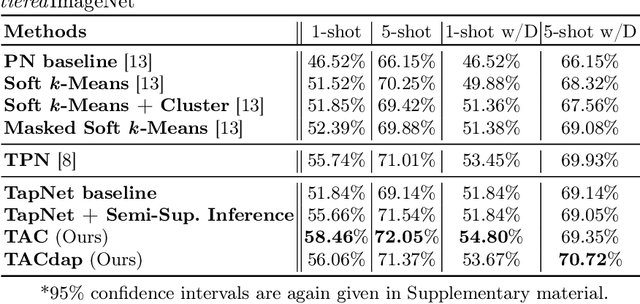
Few-shot learning aims to handle previously unseen tasks using only a small amount of new training data. In preparing (or meta-training) a few-shot learner, however, massive labeled data are necessary. In the real world, unfortunately, labeled data are expensive and/or scarce. In this work, we propose a few-shot learner that can work well under the semi-supervised setting where a large portion of training data is unlabeled. Our method employs explicit task-conditioning in which unlabeled sample clustering for the current task takes place in a new projection space different from the embedding feature space. The conditioned clustering space is linearly constructed so as to quickly close the gap between the class centroids for the current task and the independent per-class reference vectors meta-trained across tasks. In a more general setting, our method introduces a concept of controlling the degree of task-conditioning for meta-learning: the amount of task-conditioning varies with the number of repetitive updates for the clustering space. Extensive simulation results based on the miniImageNet and tieredImageNet datasets show state-of-the-art semi-supervised few-shot classification performance of the proposed method. Simulation results also indicate that the proposed task-adaptive clustering shows graceful degradation with a growing number of distractor samples, i.e., unlabeled sample images coming from outside the candidate classes.
TapNet: Neural Network Augmented with Task-Adaptive Projection for Few-Shot Learning
May 16, 2019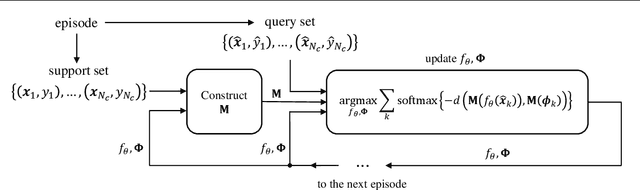
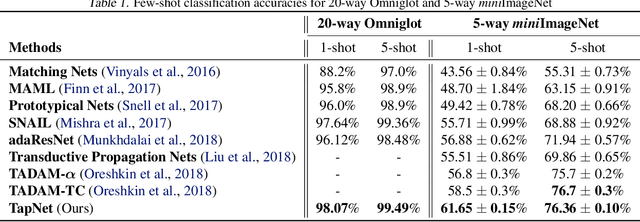

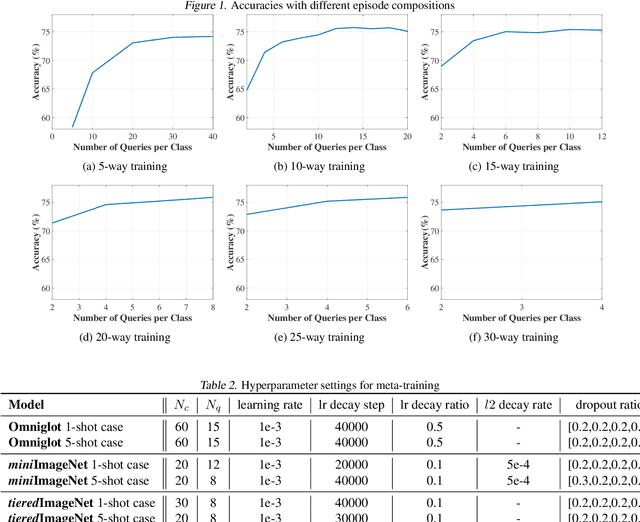
Handling previously unseen tasks after given only a few training examples continues to be a tough challenge in machine learning. We propose TapNets, neural networks augmented with task-adaptive projection for improved few-shot learning. Here, employing a meta-learning strategy with episode-based training, a network and a set of per-class reference vectors are learned across widely varying tasks. At the same time, for every episode, features in the embedding space are linearly projected into a new space as a form of quick task-specific conditioning. The training loss is obtained based on a distance metric between the query and the reference vectors in the projection space. Excellent generalization results in this way. When tested on the Omniglot, miniImageNet and tieredImageNet datasets, we obtain state of the art classification accuracies under various few-shot scenarios.
Meta Learner with Linear Nulling
Aug 07, 2018
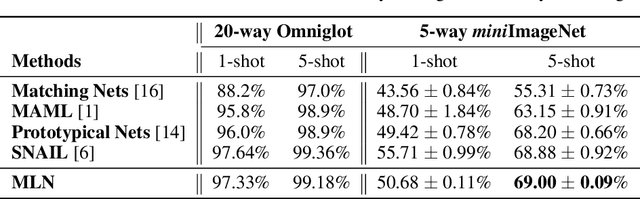
We propose a meta learning algorithm utilizing a linear transformer that carries out null-space projection of neural network outputs. The main idea is to construct a classification space such that the error signals during few-shot training are zero-forced on that space. The final decision on a test sample is obtained utilizing a null-space-projected distance measure between the network output and label-dependent weights that have been trained in the initial meta learning phase. Our meta learner achieves the best or near-best accuracies among known methods in few-shot image classification tasks with Omniglot and miniImageNet. In particular, our method shows stronger relative performance by significant margins as the classification task becomes more complicated.