 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitGP: Achieving Both Generalization and Personalization in Federated Learning
Dec 16, 2022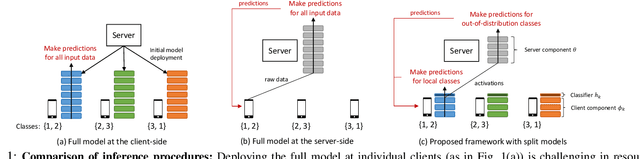
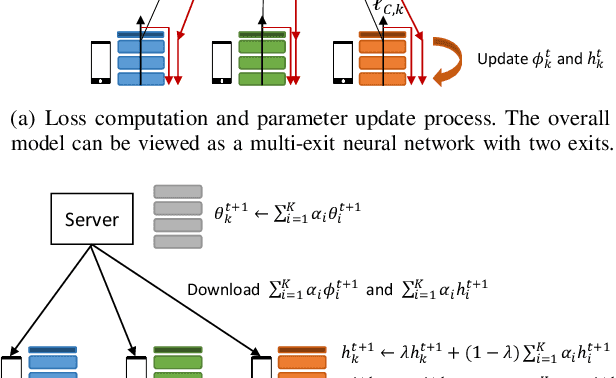
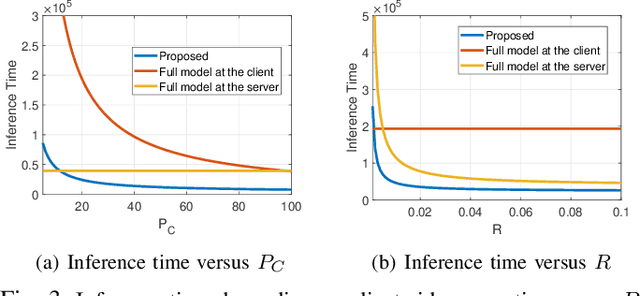
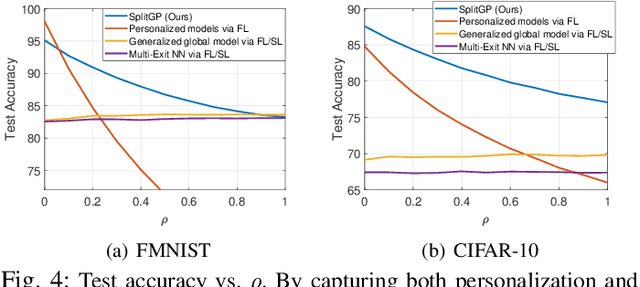
A fundamental challenge to providing edge-AI services is the need for a machine learning (ML) model that achieves personalization (i.e., to individual clients) and generalization (i.e., to unseen data) properties concurrently. Existing techniques in federated learning (FL) have encountered a steep tradeoff between these objectives and impose large computational requirements on edge devices during training and inference. In this paper, we propose SplitGP, a new split learning solution that can simultaneously capture generalization and personalization capabilities for efficient inference across resource-constrained clients (e.g., mobile/IoT devices). Our key idea is to split the full ML model into client-side and server-side components, and impose different roles to them: the client-side model is trained to have strong personalization capability optimized to each client's main task, while the server-side model is trained to have strong generalization capability for handling all clients' out-of-distribution tasks. We analytically characterize the convergence behavior of SplitGP, revealing that all client models approach stationary points asymptotically. Further, we analyze the inference time in SplitGP and provide bounds for determining model split ratios. Experimental results show that SplitGP outperforms existing baselines by wide margins in inference time and test accuracy for varying amounts of out-of-distribution samples.
XtarNet: Learning to Extract Task-Adaptive Representation for Incremental Few-Shot Learning
Mar 19, 2020
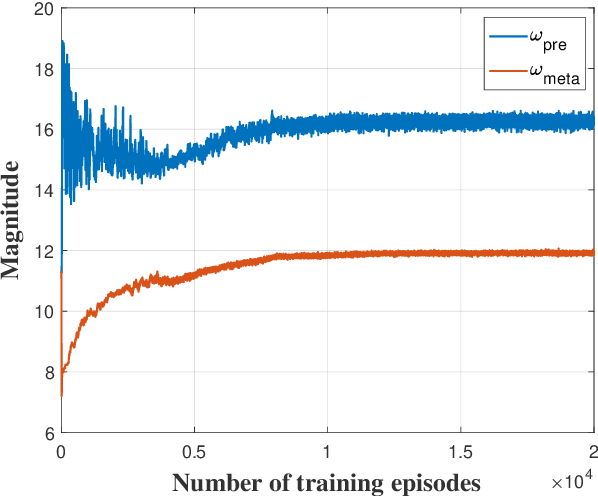

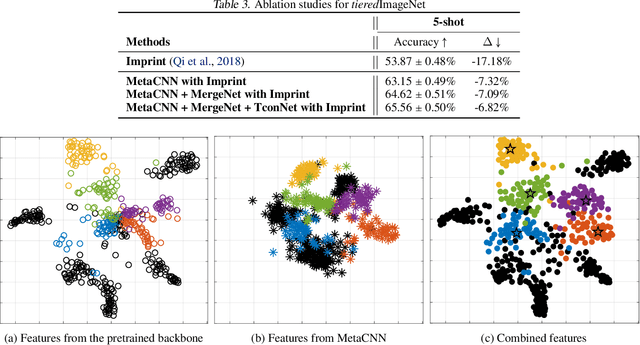
Learning novel concepts while preserving prior knowledge is a long-standing challenge in machine learning. The challenge gets greater when a novel task is given with only a few labeled examples, a problem known as incremental few-shot learning. We propose XtarNet, which learns to extract task-adaptive representation (TAR) for facilitating incremental few-shot learning. The method utilizes a backbone network pretrained on a set of base categories while also employing additional modules that are meta-trained across episodes. Given a new task, the novel feature extracted from the meta-trained modules is mixed with the base feature obtained from the pretrained model. The process of combining two different features provides TAR and is also controlled by meta-trained modules. The TAR contains effective information for classifying both novel and base categories. The base and novel classifiers quickly adapt to a given task by utilizing the TAR. Experiments on standard image datasets indicate that XtarNet achieves state-of-the-art incremental few-shot learning performance. The concept of TAR can also be used in conjunction with existing incremental few-shot learning methods; extensive simulation results in fact show that applying TAR enhances the known methods significantly.