 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency-Guided Temperature Scaling Using Style and Content Information for Out-of-Domain Calibration
Feb 22, 2024



Research interests in the robustness of deep neural networks against domain shifts have been rapidly increasing in recent years. Most existing works, however, focus on improving the accuracy of the model, not the calibration performance which is another important requirement for trustworthy AI systems. Temperature scaling (TS), an accuracy-preserving post-hoc calibration method, has been proven to be effective in in-domain settings, but not in out-of-domain (OOD) due to the difficulty in obtaining a validation set for the unseen domain beforehand. In this paper, we propose consistency-guided temperature scaling (CTS), a new temperature scaling strategy that can significantly enhance the OOD calibration performance by providing mutual supervision among data samples in the source domains. Motivated by our observation that over-confidence stemming from inconsistent sample predictions is the main obstacle to OOD calibration, we propose to guide the scaling process by taking consistencies into account in terms of two different aspects -- style and content -- which are the key components that can well-represent data samples in multi-domain settings. Experimental results demonstrate that our proposed strategy outperforms existing works, achieving superior OOD calibration performance on various datasets. This can be accomplished by employing only the source domains without compromising accuracy, making our scheme directly applicable to various trustworthy AI systems.
NEO-KD: Knowledge-Distillation-Based Adversarial Training for Robust Multi-Exit Neural Networks
Nov 01, 2023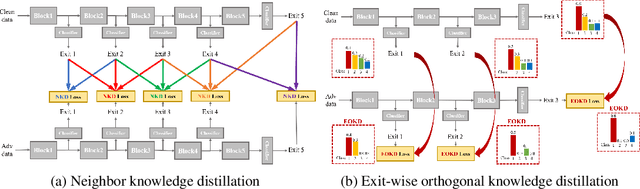
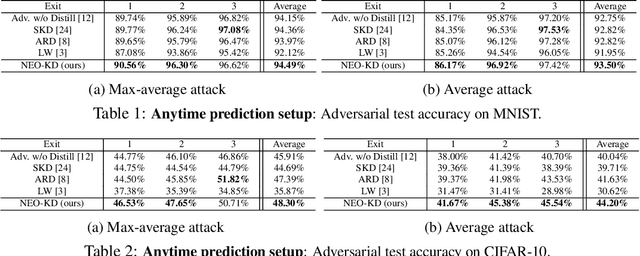
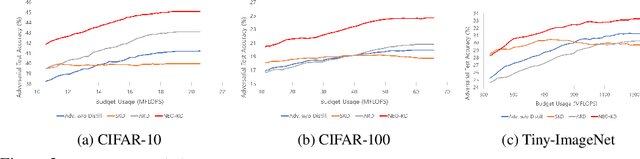
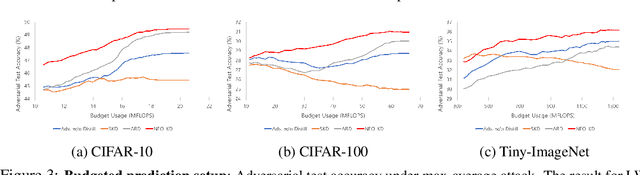
While multi-exit neural networks are regarded as a promising solution for making efficient inference via early exits, combating adversarial attacks remains a challenging problem. In multi-exit networks, due to the high dependency among different submodels, an adversarial example targeting a specific exit not only degrades the performance of the target exit but also reduces the performance of all other exits concurrently. This makes multi-exit networks highly vulnerable to simple adversarial attacks. In this paper, we propose NEO-KD, a knowledge-distillation-based adversarial training strategy that tackles this fundamental challenge based on two key contributions. NEO-KD first resorts to neighbor knowledge distillation to guide the output of the adversarial examples to tend to the ensemble outputs of neighbor exits of clean data. NEO-KD also employs exit-wise orthogonal knowledge distillation for reducing adversarial transferability across different submodels. The result is a significantly improved robustness against adversarial attacks. Experimental results on various datasets/models show that our method achieves the best adversarial accuracy with reduced computation budgets, compared to the baselines relying on existing adversarial training or knowledge distillation techniques for multi-exit networks.
StableFDG: Style and Attention Based Learning for Federated Domain Generalization
Nov 01, 2023Traditional federated learning (FL) algorithms operate under the assumption that the data distributions at training (source domains) and testing (target domain) are the same. The fact that domain shifts often occur in practice necessitates equipping FL methods with a domain generalization (DG) capability. However, existing DG algorithms face fundamental challenges in FL setups due to the lack of samples/domains in each client's local dataset. In this paper, we propose StableFDG, a style and attention based learning strategy for accomplishing federated domain generalization, introducing two key contributions. The first is style-based learning, which enables each client to explore novel styles beyond the original source domains in its local dataset, improving domain diversity based on the proposed style sharing, shifting, and exploration strategies. Our second contribution is an attention-based feature highlighter, which captures the similarities between the features of data samples in the same class, and emphasizes the important/common characteristics to better learn the domain-invariant characteristics of each class in data-poor FL scenarios. Experimental results show that StableFDG outperforms existing baselines on various DG benchmark datasets, demonstrating its efficacy.
Test-Time Style Shifting: Handling Arbitrary Styles in Domain Generalization
Jun 13, 2023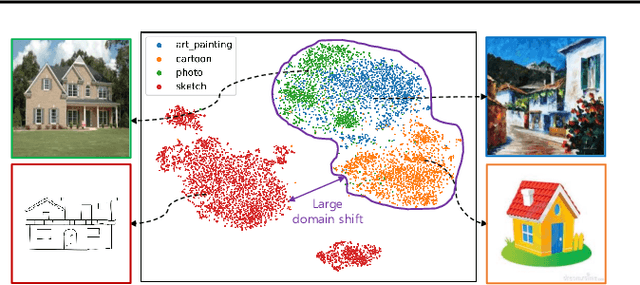

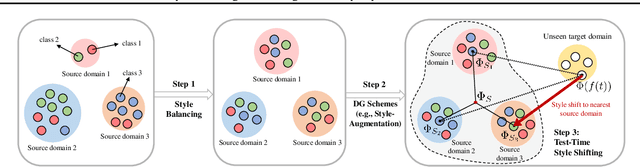
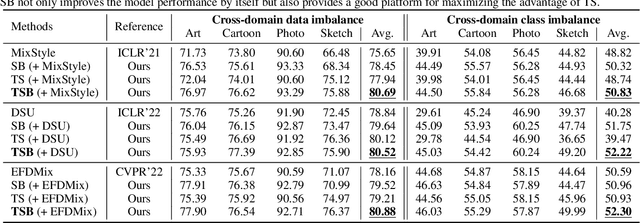
In domain generalization (DG), the target domain is unknown when the model is being trained, and the trained model should successfully work on an arbitrary (and possibly unseen) target domain during inference. This is a difficult problem, and despite active studies in recent years, it remains a great challenge. In this paper, we take a simple yet effective approach to tackle this issue. We propose test-time style shifting, which shifts the style of the test sample (that has a large style gap with the source domains) to the nearest source domain that the model is already familiar with, before making the prediction. This strategy enables the model to handle any target domains with arbitrary style statistics, without additional model update at test-time. Additionally, we propose style balancing, which provides a great platform for maximizing the advantage of test-time style shifting by handling the DG-specific imbalance issues. The proposed ideas are easy to implement and successfully work in conjunction with various other DG schemes. Experimental results on different datasets show the effectiveness of our methods.