 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidelines for Designing AI Technologies to Support Adult Learning
May 06, 2026AI-powered educational technologies have demonstrated measurable benefits for learners, but their design and evaluation have largely centered on K-12 contexts. As a result, many AI-supported learning systems remain poorly aligned with the needs, constraints, and goals of adult learners. To better understand how AI systems function in adult education, this paper examines the deployment of several AI learning technologies developed within a multidisciplinary, national research institute in the United States focused on adult learning and online education. Drawing on longitudinal deployment data, we conducted a reflexive thematic analysis to identify recurring challenges and design considerations across systems. These insights were synthesized into a set of 19 design guidelines intended to inform future AI-supported adult learning technologies. We demonstrate the utility of these guidelines through a heuristic evaluation of the deployed systems. Lastly, we present a guideline exploration tool that aids in the ideation of technologies by connecting the guidelines to stakeholder statements surfaced in the analysis process.
Post-training quantization of vision encoders needs prefixing registers
Oct 06, 2025



Transformer-based vision encoders -- such as CLIP -- are central to multimodal intelligence, powering applications from autonomous web agents to robotic control. Since these applications often demand real-time processing of massive visual data, reducing the inference cost of vision encoders is critical. Post-training quantization offers a practical path, but remains challenging even at 8-bit precision due to massive-scale activations (i.e., outliers). In this work, we propose $\textit{RegCache}$, a training-free algorithm to mitigate outliers in vision encoders, enabling quantization with significantly smaller accuracy drops. The proposed RegCache introduces outlier-prone yet semantically meaningless prefix tokens to the target vision encoder, which prevents other tokens from having outliers. Notably, we observe that outliers in vision encoders behave differently from those in language models, motivating two technical innovations: middle-layer prefixing and token deletion. Experiments show that our method consistently improves the accuracy of quantized models across both text-supervised and self-supervised vision encoders.
Transparent Networks for Multivariate Time Series
Oct 14, 2024Transparent models, which are machine learning models that produce inherently interpretable predictions, are receiving significant attention in high-stakes domains. However, despite much real-world data being collected as time series, there is a lack of studies on transparent time series models. To address this gap, we propose a novel transparent neural network model for time series called Generalized Additive Time Series Model (GATSM). GATSM consists of two parts: 1) independent feature networks to learn feature representations, and 2) a transparent temporal module to learn temporal patterns across different time steps using the feature representations. This structure allows GATSM to effectively capture temporal patterns and handle dynamic-length time series while preserving transparency. Empirical experiments show that GATSM significantly outperforms existing generalized additive models and achieves comparable performance to black-box time series models, such as recurrent neural networks and Transformer. In addition, we demonstrate that GATSM finds interesting patterns in time series. The source code is available at https://github.com/gim4855744/GATSM.
Accelerated MR Cholangiopancreatography with Deep Learning-based Reconstruction
May 06, 2024This study accelerates MR cholangiopancreatography (MRCP) acquisitions using deep learning-based (DL) reconstruction at 3T and 0.55T. Thirty healthy volunteers underwent conventional two-fold MRCP scans at field strengths of 3T or 0.55T. We trained a variational network (VN) using retrospectively six-fold undersampled data obtained at 3T. We then evaluated our method against standard techniques such as parallel imaging (PI) and compressed sensing (CS), focusing on peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) as metrics. Furthermore, considering acquiring fully-sampled MRCP is impractical, we added a self-supervised DL reconstruction (SSDU) to the evaluating group. We also tested our method in a prospective accelerated scenario to reflect real-world clinical applications and evaluated its adaptability to MRCP at 0.55T. Our method demonstrated a remarkable reduction of average acquisition time from 599/542 to 255/180 seconds for MRCP at 3T/0.55T. In both retrospective and prospective undersampling scenarios, the PSNR and SSIM of VN were higher than those of PI, CS, and SSDU. At the same time, VN preserved the image quality of undersampled data, i.e., sharpness and the visibility of hepatobiliary ducts. In addition, VN also produced high quality reconstructions at 0.55T resulting in the highest PSNR and SSIM. In summary, VN trained for highly accelerated MRCP allows to reduce the acquisition time by a factor of 2.4/3.0 at 3T/0.55T while maintaining the image quality of the conventional acquisition.
StableFDG: Style and Attention Based Learning for Federated Domain Generalization
Nov 01, 2023Traditional federated learning (FL) algorithms operate under the assumption that the data distributions at training (source domains) and testing (target domain) are the same. The fact that domain shifts often occur in practice necessitates equipping FL methods with a domain generalization (DG) capability. However, existing DG algorithms face fundamental challenges in FL setups due to the lack of samples/domains in each client's local dataset. In this paper, we propose StableFDG, a style and attention based learning strategy for accomplishing federated domain generalization, introducing two key contributions. The first is style-based learning, which enables each client to explore novel styles beyond the original source domains in its local dataset, improving domain diversity based on the proposed style sharing, shifting, and exploration strategies. Our second contribution is an attention-based feature highlighter, which captures the similarities between the features of data samples in the same class, and emphasizes the important/common characteristics to better learn the domain-invariant characteristics of each class in data-poor FL scenarios. Experimental results show that StableFDG outperforms existing baselines on various DG benchmark datasets, demonstrating its efficacy.
Higher-order Neural Additive Models: An Interpretable Machine Learning Model with Feature Interactions
Sep 30, 2022

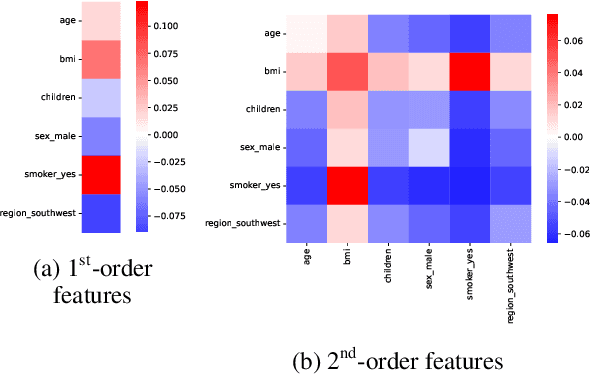

Black-box models, such as deep neural networks, exhibit superior predictive performances, but understanding their behavior is notoriously difficult. Many explainable artificial intelligence methods have been proposed to reveal the decision-making processes of black box models. However, their applications in high-stakes domains remain limited. Recently proposed neural additive models (NAM) have achieved state-of-the-art interpretable machine learning. NAM can provide straightforward interpretations with slight performance sacrifices compared with multi-layer perceptron. However, NAM can only model 1$^{\text{st}}$-order feature interactions; thus, it cannot capture the co-relationships between input features. To overcome this problem, we propose a novel interpretable machine learning method called higher-order neural additive models (HONAM) and a feature interaction method for high interpretability. HONAM can model arbitrary orders of feature interactions. Therefore, it can provide the high predictive performance and interpretability that high-stakes domains need. In addition, we propose a novel hidden unit to effectively learn sharp-shape functions. We conducted experiments using various real-world datasets to examine the effectiveness of HONAM. Furthermore, we demonstrate that HONAM can achieve fair AI with a slight performance sacrifice. The source code for HONAM is publicly available.
Explicit Feature Interaction-aware Graph Neural Networks
Apr 07, 2022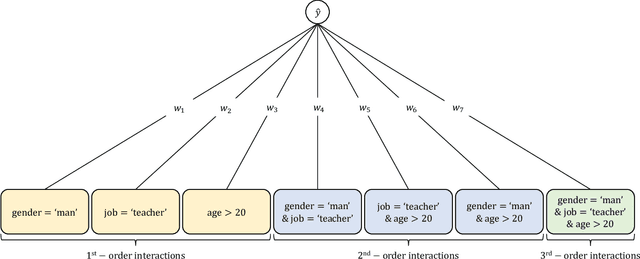


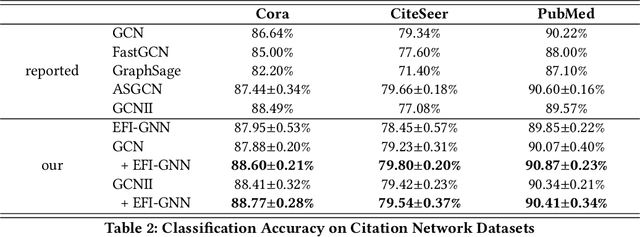
Graph neural networks are powerful methods to handle graph-structured data. However, existing graph neural networks only learn higher-order feature interactions implicitly. Thus, they cannot capture information that occurred in low-order feature interactions. To overcome this problem, we propose Explicit Feature Interaction-aware Graph Neural Network (EFI-GNN), which explicitly learns arbitrary-order feature interactions. EFI-GNN can jointly learn with any other graph neural network. We demonstrate that the joint learning method always enhances performance on the various node classification tasks. Furthermore, since EFI-GNN is inherently a linear model, we can interpret the prediction result of EFI-GNN. With the computation rule, we can obtain an any-order feature's effect on the decision. By that, we visualize the effects of the first-order and second-order features as a form of a heatmap.
Comparing Feedback Linearization and Adaptive Backstepping Control for Airborne Orientation of Agile Ground Robots using Wheel Reaction Torque
Sep 23, 2020
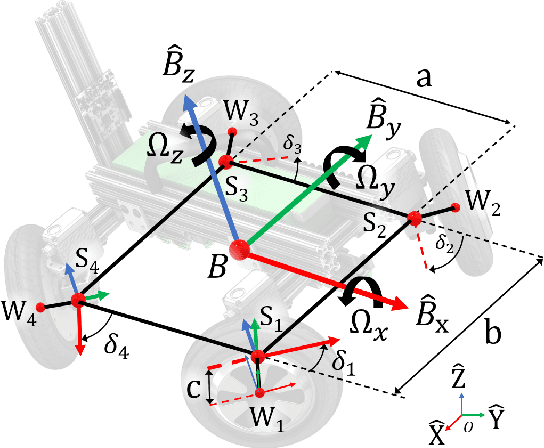
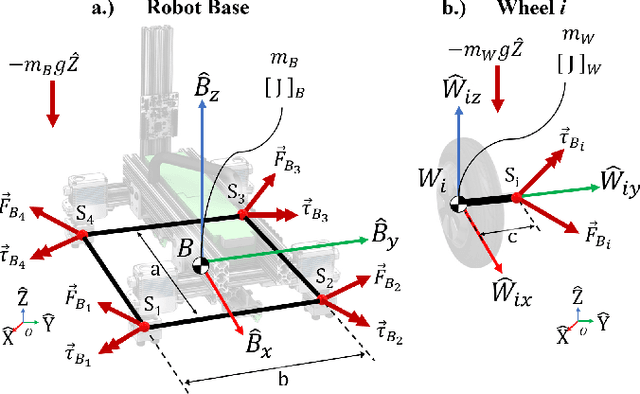
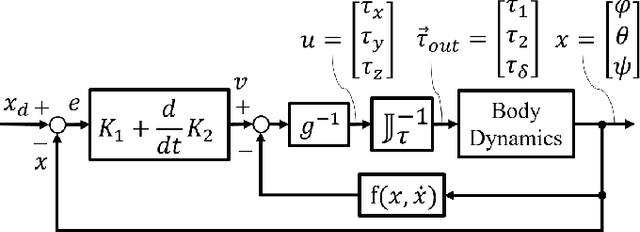
In this paper, two nonlinear methods for stabilizing the orientation of a Four-Wheel Independent Drive and Steering (4WIDS) robot while in the air are analyzed, implemented in simulation, and compared. AGRO (the Agile Ground Robot) is a 4WIDS inspection robot that can be deployed into unsafe environments by being thrown, and can use the reaction torque from its four wheels to command its orientation while in the air. Prior work has demonstrated on a hardware prototype that simple PD control with hand-tuned gains is sufficient, but hardly optimal, to stabilize the orientation in under 500ms. The goal of this work is to decrease the stabilization time and reject disturbances using nonlinear control methods. A model-based Feedback Linearization (FL) was added to compensate for the nonlinear Coriolis terms. However, with external disturbances, model uncertainty and sensor noise, the FL controller does not guarantee stability. As an alternative, a second controller was developed using backstepping methods with an adaptive compensator for external disturbances, model uncertainty, and sensor offset. The controller was designed using Lyapunov analysis. A simulation was written using the full nonlinear dynamics of AGRO in an isotropic steering configuration in which control authority over its pitch and roll are equalized. The PD+FL control method was compared to the backstepping control method using the same initial conditions in simulation. Both the backstepping controller and the PD+FL controller stabilized the system within 250 milliseconds. The adaptive backstepping controller was also able to achieve this performance with the adaptation law enabled and compensating for offset noisy sinusoidal disturbances.