 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-DOG: Training-Free Multi-View Multi-Object Association in Dense Scenes Without Visual Feature via Connected δ-Overlap Graphs
Jul 18, 2025



Multi-view multi-object association is a fundamental step in 3D reconstruction pipelines, enabling consistent grouping of object instances across multiple camera views. Existing methods often rely on appearance features or geometric constraints such as epipolar consistency. However, these approaches can fail when objects are visually indistinguishable or observations are corrupted by noise. We propose C-DOG, a training-free framework that serves as an intermediate module bridging object detection (or pose estimation) and 3D reconstruction, without relying on visual features. It combines connected delta-overlap graph modeling with epipolar geometry to robustly associate detections across views. Each 2D observation is represented as a graph node, with edges weighted by epipolar consistency. A delta-neighbor-overlap clustering step identifies strongly consistent groups while tolerating noise and partial connectivity. To further improve robustness, we incorporate Interquartile Range (IQR)-based filtering and a 3D back-projection error criterion to eliminate inconsistent observations. Extensive experiments on synthetic benchmarks demonstrate that C-DOG outperforms geometry-based baselines and remains robust under challenging conditions, including high object density, without visual features, and limited camera overlap, making it well-suited for scalable 3D reconstruction in real-world scenarios.
Sampling Strategies for Efficient Training of Deep Learning Object Detection Algorithms
May 23, 2025



Two sampling strategies are investigated to enhance efficiency in training a deep learning object detection model. These sampling strategies are employed under the assumption of Lipschitz continuity of deep learning models. The first strategy is uniform sampling which seeks to obtain samples evenly yet randomly through the state space of the object dynamics. The second strategy of frame difference sampling is developed to explore the temporal redundancy among successive frames in a video. Experiment result indicates that these proposed sampling strategies provide a dataset that yields good training performance while requiring relatively few manually labelled samples.
EasyVis2: A Real Time Multi-view 3D Visualization for Laparoscopic Surgery Training Enhanced by a Deep Neural Network YOLOv8-Pose
Dec 21, 2024



EasyVis2 is a system designed for hands-free, real-time 3D visualization during laparoscopic surgery. It incorporates a surgical trocar equipped with a set of micro-cameras, which are inserted into the body cavity to provide an expanded field of view and a 3D perspective of the surgical procedure. A sophisticated deep neural network algorithm, YOLOv8-Pose, is tailored to estimate the position and orientation of surgical instruments in each individual camera view. Subsequently, 3D surgical tool pose estimation is performed using associated 2D key points across multiple views. This enables the rendering of a 3D surface model of the surgical tools overlaid on the observed background scene for real-time visualization. In this study, we explain the process of developing a training dataset for new surgical tools to customize YoLOv8-Pose while minimizing labeling efforts. Extensive experiments were conducted to compare EasyVis2 with the original EasyVis, revealing that, with the same number of cameras, the new system improves 3D reconstruction accuracy and reduces computation time. Additionally, experiments with 3D rendering on real animal tissue visually demonstrated the distance between surgical tools and tissues by displaying virtual side views, indicating potential applications in real surgeries in the future.
From Prototypes to General Distributions: An Efficient Curriculum for Masked Image Modeling
Nov 16, 2024Masked Image Modeling (MIM) has emerged as a powerful self-supervised learning paradigm for visual representation learning, enabling models to acquire rich visual representations by predicting masked portions of images from their visible regions. While this approach has shown promising results, we hypothesize that its effectiveness may be limited by optimization challenges during early training stages, where models are expected to learn complex image distributions from partial observations before developing basic visual processing capabilities. To address this limitation, we propose a prototype-driven curriculum leagrning framework that structures the learning process to progress from prototypical examples to more complex variations in the dataset. Our approach introduces a temperature-based annealing scheme that gradually expands the training distribution, enabling more stable and efficient learning trajectories. Through extensive experiments on ImageNet-1K, we demonstrate that our curriculum learning strategy significantly improves both training efficiency and representation quality while requiring substantially fewer training epochs compared to standard Masked Auto-Encoding. Our findings suggest that carefully controlling the order of training examples plays a crucial role in self-supervised visual learning, providing a practical solution to the early-stage optimization challenges in MIM.
A Wearable Gait Monitoring System for 17 Gait Parameters Based on Computer Vision
Nov 16, 2024



We developed a shoe-mounted gait monitoring system capable of tracking up to 17 gait parameters, including gait length, step time, stride velocity, and others. The system employs a stereo camera mounted on one shoe to track a marker placed on the opposite shoe, enabling the estimation of spatial gait parameters. Additionally, a Force Sensitive Resistor (FSR) affixed to the heel of the shoe, combined with a custom-designed algorithm, is utilized to measure temporal gait parameters. Through testing on multiple participants and comparison with the gait mat, the proposed gait monitoring system exhibited notable performance, with the accuracy of all measured gait parameters exceeding 93.61%. The system also demonstrated a low drift of 4.89% during long-distance walking. A gait identification task conducted on participants using a trained Transformer model achieved 95.7% accuracy on the dataset collected by the proposed system, demonstrating that our hardware has the potential to collect long-sequence gait data suitable for integration with current Large Language Models (LLMs). The system is cost-effective, user-friendly, and well-suited for real-life measurements.
Patch Ranking: Efficient CLIP by Learning to Rank Local Patches
Sep 22, 2024Contrastive image-text pre-trained models such as CLIP have shown remarkable adaptability to downstream tasks. However, they face challenges due to the high computational requirements of the Vision Transformer (ViT) backbone. Current strategies to boost ViT efficiency focus on pruning patch tokens but fall short in addressing the multimodal nature of CLIP and identifying the optimal subset of tokens for maximum performance. To address this, we propose greedy search methods to establish a "Golden Ranking" and introduce a lightweight predictor specifically trained to approximate this Ranking. To compensate for any performance degradation resulting from token pruning, we incorporate learnable visual tokens that aid in restoring and potentially enhancing the model's performance. Our work presents a comprehensive and systematic investigation of pruning tokens within the ViT backbone of CLIP models. Through our framework, we successfully reduced 40% of patch tokens in CLIP's ViT while only suffering a minimal average accuracy loss of 0.3 across seven datasets. Our study lays the groundwork for building more computationally efficient multimodal models without sacrificing their performance, addressing a key challenge in the application of advanced vision-language models.
Block Pruning for Enhanced Efficiency in Convolutional Neural Networks
Jan 14, 2024This paper presents a novel approach to network pruning, targeting block pruning in deep neural networks for edge computing environments. Our method diverges from traditional techniques that utilize proxy metrics, instead employing a direct block removal strategy to assess the impact on classification accuracy. This hands-on approach allows for an accurate evaluation of each block's importance. We conducted extensive experiments on CIFAR-10, CIFAR-100, and ImageNet datasets using ResNet architectures. Our results demonstrate the efficacy of our method, particularly on large-scale datasets like ImageNet with ResNet50, where it excelled in reducing model size while retaining high accuracy, even when pruning a significant portion of the network. The findings underscore our method's capability in maintaining an optimal balance between model size and performance, especially in resource-constrained edge computing scenarios.
Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?
Jul 22, 2023



Vision-language models such as CLIP learn a generic text-image embedding from large-scale training data. A vision-language model can be adapted to a new classification task through few-shot prompt tuning. We find that such a prompt tuning process is highly robust to label noises. This intrigues us to study the key reasons contributing to the robustness of the prompt tuning paradigm. We conducted extensive experiments to explore this property and find the key factors are: 1) the fixed classname tokens provide a strong regularization to the optimization of the model, reducing gradients induced by the noisy samples; 2) the powerful pre-trained image-text embedding that is learned from diverse and generic web data provides strong prior knowledge for image classification. Further, we demonstrate that noisy zero-shot predictions from CLIP can be used to tune its own prompt, significantly enhancing prediction accuracy in the unsupervised setting. The code is available at https://github.com/CEWu/PTNL.
Live American Sign Language Letter Classification with Convolutional Neural Networks
May 26, 2023
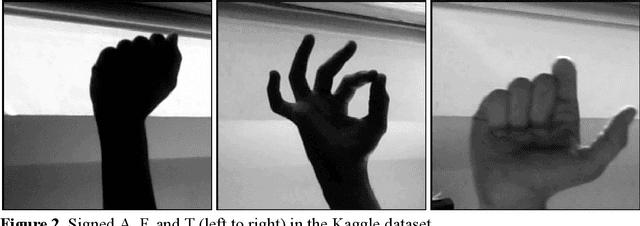

This project is centered around building a neural network that is able to recognize ASL letters in images, particularly within the scope of a live video feed. Initial testing results came up short of expectations when both the convolutional network and VGG16 transfer learning approaches failed to generalize in settings of different backgrounds. The use of a pre-trained hand joint detection model was then adopted with the produced joint locations being fed into a fully-connected neural network. The results of this approach exceeded those of prior methods and generalized well to a live video feed application.
SimHaze: game engine simulated data for real-world dehazing
May 25, 2023Deep models have demonstrated recent success in single-image dehazing. Most prior methods consider fully supervised training and learn from paired clean and hazy images, where a hazy image is synthesized based on a clean image and its estimated depth map. This paradigm, however, can produce low-quality hazy images due to inaccurate depth estimation, resulting in poor generalization of the trained models. In this paper, we explore an alternative approach for generating paired clean-hazy images by leveraging computer graphics. Using a modern game engine, our approach renders crisp clean images and their precise depth maps, based on which high-quality hazy images can be synthesized for training dehazing models. To this end, we present SimHaze: a new synthetic haze dataset. More importantly, we show that training with SimHaze alone allows the latest dehazing models to achieve significantly better performance in comparison to previous dehazing datasets. Our dataset and code will be made publicly available.