 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic IR Drop Prediction with Attention U-Net and Saliency-Based Explainability
Aug 06, 2024There has been significant recent progress to reduce the computational effort of static IR drop analysis using neural networks, and modeling as an image-to-image translation task. A crucial issue is the lack of sufficient data from real industry designs to train these networks. Additionally, there is no methodology to explain a high-drop pixel in a predicted IR drop image to its specific root-causes. In this work, we first propose a U-Net neural network model with attention gates which is specifically tailored to achieve fast and accurate image-based static IR drop prediction. Attention gates allow selective emphasis on relevant parts of the input data without supervision which is desired because of the often sparse nature of the IR drop map. We propose a two-phase training process which utilizes a mix of artificially-generated data and a limited number of points from real designs. The results are, on-average, 18% (53%) better in MAE and 14% (113%) in F1 score compared to the winner of the ICCAD 2023 contest (and U-Net only) when tested on real designs. Second, we propose a fast method using saliency maps which can explain a predicted IR drop in terms of specific input pixels contributing the most to a drop. In our experiments, we show the number of high IR drop pixels can be reduced on-average by 18% by mimicking upsize of a tiny portion of PDN's resistive edges.
Block Pruning for Enhanced Efficiency in Convolutional Neural Networks
Jan 14, 2024This paper presents a novel approach to network pruning, targeting block pruning in deep neural networks for edge computing environments. Our method diverges from traditional techniques that utilize proxy metrics, instead employing a direct block removal strategy to assess the impact on classification accuracy. This hands-on approach allows for an accurate evaluation of each block's importance. We conducted extensive experiments on CIFAR-10, CIFAR-100, and ImageNet datasets using ResNet architectures. Our results demonstrate the efficacy of our method, particularly on large-scale datasets like ImageNet with ResNet50, where it excelled in reducing model size while retaining high accuracy, even when pruning a significant portion of the network. The findings underscore our method's capability in maintaining an optimal balance between model size and performance, especially in resource-constrained edge computing scenarios.
Logic Synthesis Meets Machine Learning: Trading Exactness for Generalization
Dec 15, 2020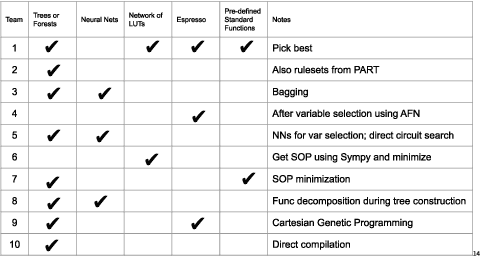
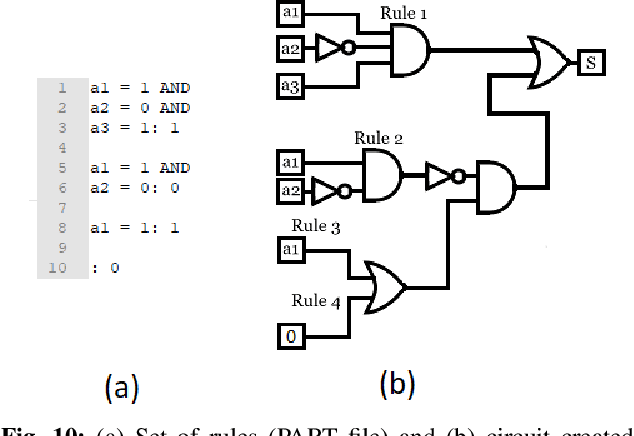
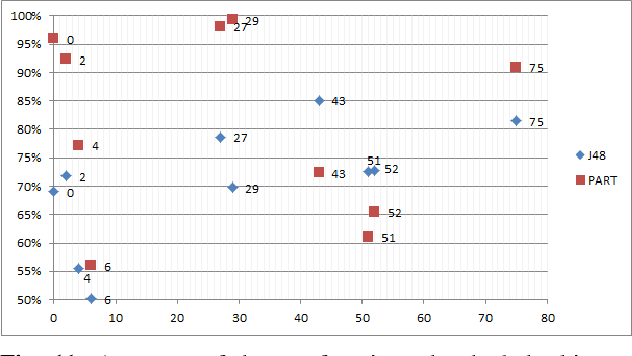
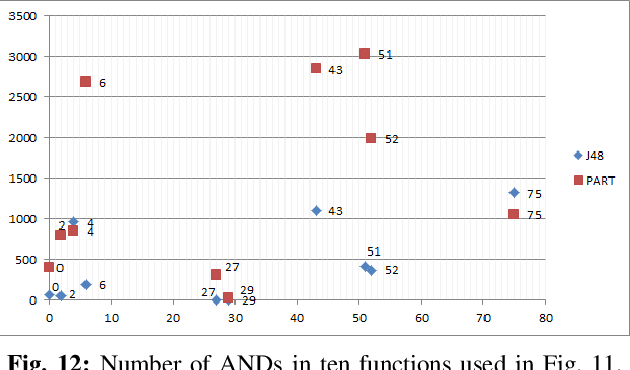
Logic synthesis is a fundamental step in hardware design whose goal is to find structural representations of Boolean functions while minimizing delay and area. If the function is completely-specified, the implementation accurately represents the function. If the function is incompletely-specified, the implementation has to be true only on the care set. While most of the algorithms in logic synthesis rely on SAT and Boolean methods to exactly implement the care set, we investigate learning in logic synthesis, attempting to trade exactness for generalization. This work is directly related to machine learning where the care set is the training set and the implementation is expected to generalize on a validation set. We present learning incompletely-specified functions based on the results of a competition conducted at IWLS 2020. The goal of the competition was to implement 100 functions given by a set of care minterms for training, while testing the implementation using a set of validation minterms sampled from the same function. We make this benchmark suite available and offer a detailed comparative analysis of the different approaches to learning
Efficient Inference of CNNs via Channel Pruning
Aug 08, 2019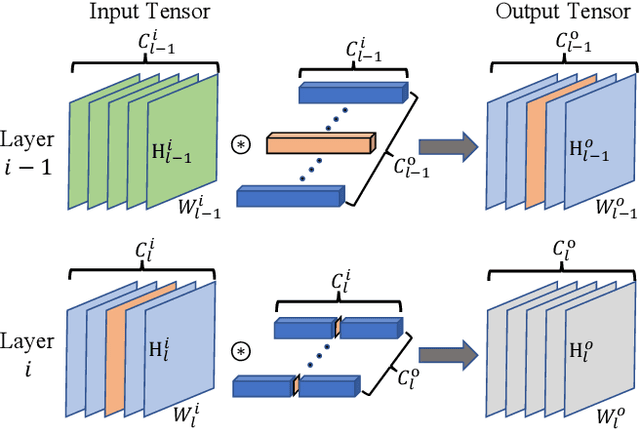
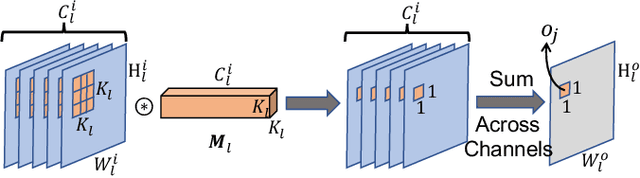

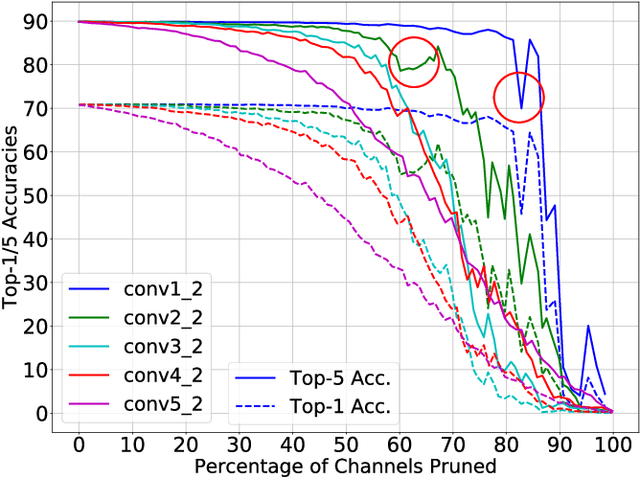
The deployment of Convolutional Neural Networks (CNNs) on resource constrained platforms such as mobile devices and embedded systems has been greatly hindered by their high implementation cost, and thus motivated a lot research interest in compressing and accelerating trained CNN models. Among various techniques proposed in literature, structured pruning, especially channel pruning, has gain a lot focus due to 1) its superior performance in memory, computation, and energy reduction; and 2) it is friendly to existing hardware and software libraries. In this paper, we investigate the intermediate results of convolutional layers and present a novel pivoted QR factorization based channel pruning technique that can prune any specified number of input channels of any layer. We also explore more pruning opportunities in ResNet-like architectures by applying two tweaks to our technique. Experiment results on VGG-16 and ResNet-50 models with ImageNet ILSVRC 2012 dataset are very impressive with 4.29X and 2.84X computation reduction while only sacrificing about 1.40\% top-5 accuracy. Compared to many prior works, the pruned models produced by our technique require up to 47.7\% less computation while still achieve higher accuracies.
Design Rule Violation Hotspot Prediction Based on Neural Network Ensembles
Nov 09, 2018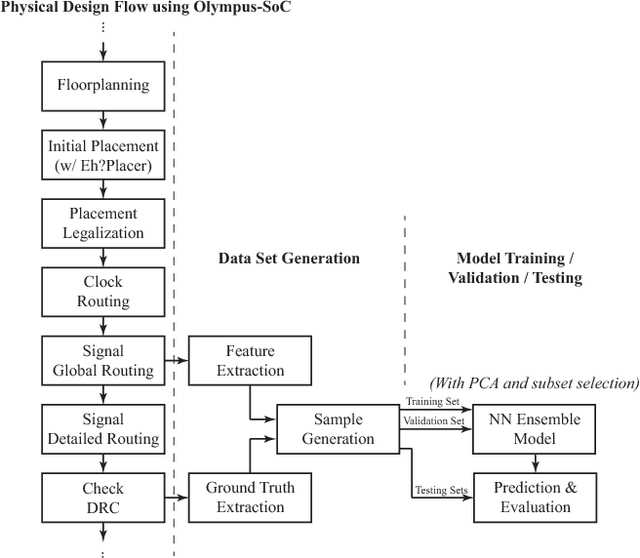
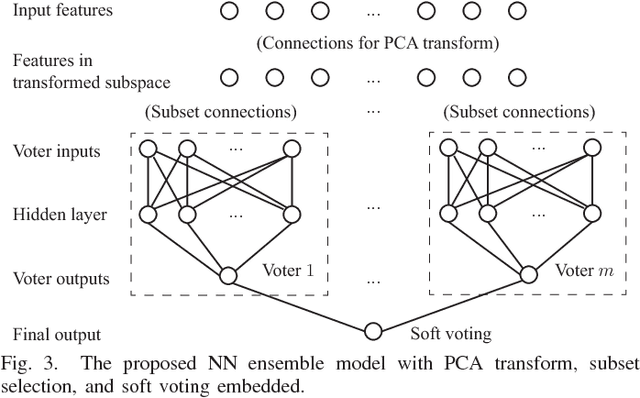
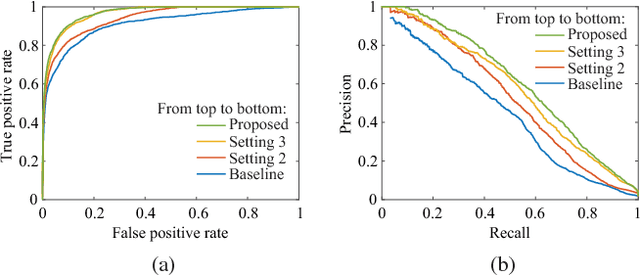
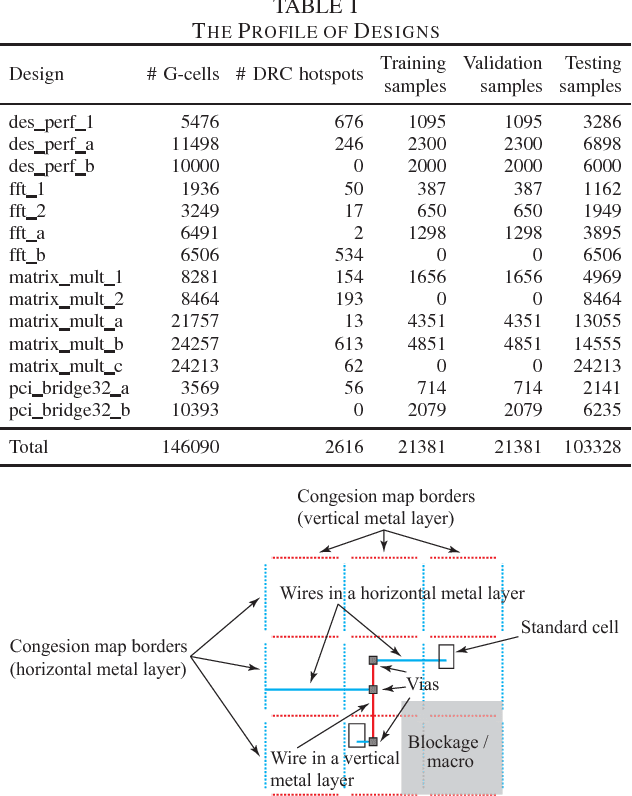
Design rule check is a critical step in the physical design of integrated circuits to ensure manufacturability. However, it can be done only after a time-consuming detailed routing procedure, which adds drastically to the time of design iterations. With advanced technology nodes, the outcomes of global routing and detailed routing become less correlated, which adds to the difficulty of predicting design rule violations from earlier stages. In this paper, a framework based on neural network ensembles is proposed to predict design rule violation hotspots using information from placement and global routing. A soft voting structure and a PCA-based subset selection scheme are developed on top of a baseline neural network from a recent work. Experimental results show that the proposed architecture achieves significant improvement in model performance compared to the baseline case. For half of test cases, the performance is even better than random forest, a commonly-used ensemble learning model.
A Mixture of Expert Approach for Low-Cost Customization of Deep Neural Networks
Oct 31, 2018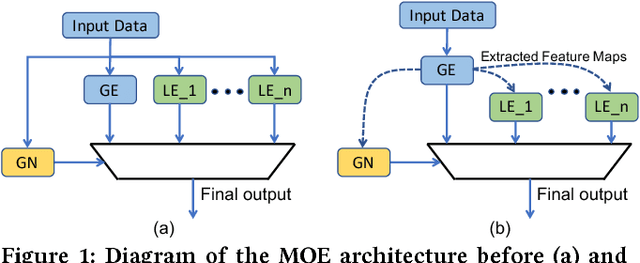
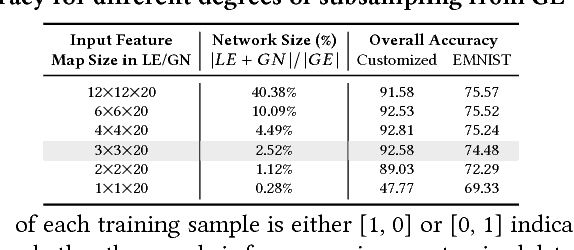
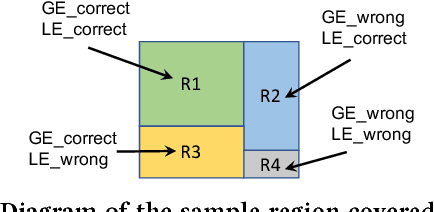
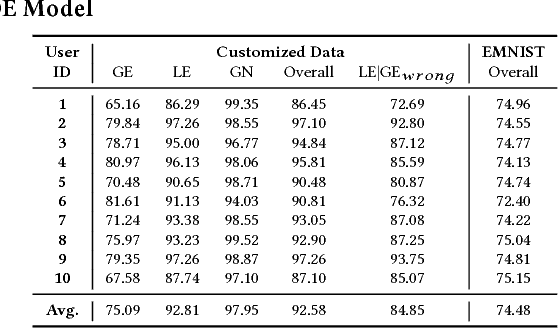
The ability to customize a trained Deep Neural Network (DNN) locally using user-specific data may greatly enhance user experiences, reduce development costs, and protect user's privacy. In this work, we propose to incorporate a novel Mixture of Experts (MOE) approach to accomplish this goal. This architecture comprises of a Global Expert (GE), a Local Expert (LE) and a Gating Network (GN). The GE is a trained DNN developed on a large training dataset representative of many potential users. After deployment on an embedded edge device, GE will be subject to customized, user-specific data (e.g., accent in speech) and its performance may suffer. This problem may be alleviated by training a local DNN (the local expert, LE) on a small size customized training data to correct the errors made by GE. A gating network then will be trained to determine whether an incoming data should be handled by GE or LE. Since the customized dataset is in general very small, the cost of training LE and GN would be much lower than that of re-training of GE. The training of LE and GN thus can be performed at local device, properly protecting the privacy of customized training data. In this work, we developed a prototype MOE architecture for handwritten alphanumeric character recognition task. We use EMNIST as the generic dataset, LeNet5 as GE, and handwritings of 10 users as the customized dataset. We show that with the LE and GN, the classification accuracy is significantly enhanced over the customized dataset with almost no degradation of accuracy over the generic dataset. In terms of energy and network size, the overhead of LE and GN is around 2.5% compared to those of GE.