 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Inference of CNNs via Channel Pruning
Paper and Code
Aug 08, 2019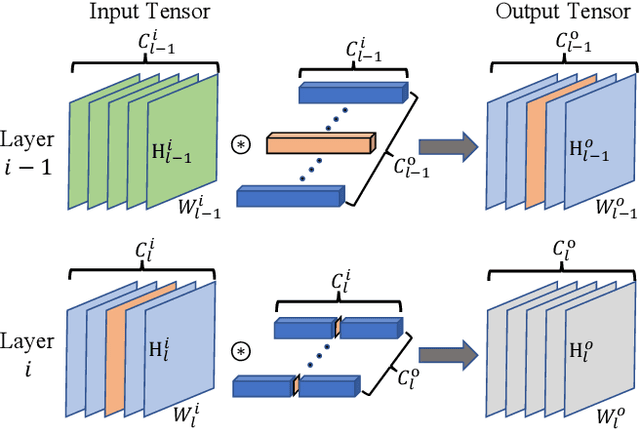
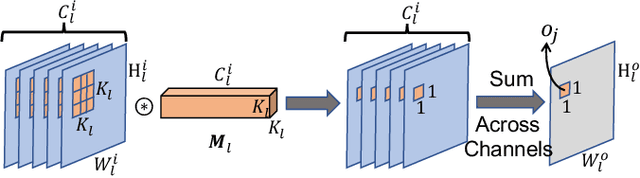

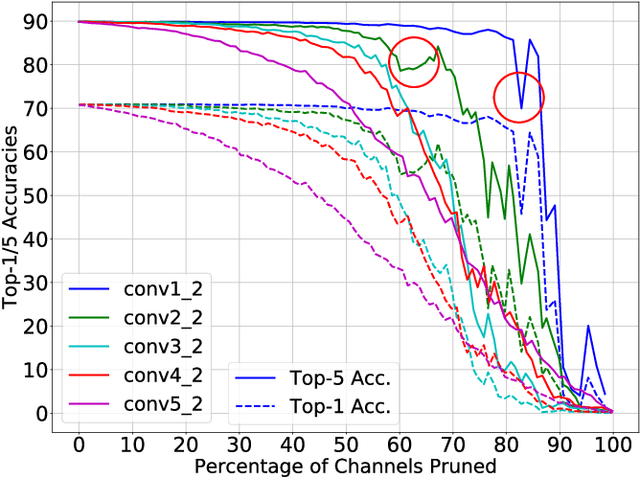
The deployment of Convolutional Neural Networks (CNNs) on resource constrained platforms such as mobile devices and embedded systems has been greatly hindered by their high implementation cost, and thus motivated a lot research interest in compressing and accelerating trained CNN models. Among various techniques proposed in literature, structured pruning, especially channel pruning, has gain a lot focus due to 1) its superior performance in memory, computation, and energy reduction; and 2) it is friendly to existing hardware and software libraries. In this paper, we investigate the intermediate results of convolutional layers and present a novel pivoted QR factorization based channel pruning technique that can prune any specified number of input channels of any layer. We also explore more pruning opportunities in ResNet-like architectures by applying two tweaks to our technique. Experiment results on VGG-16 and ResNet-50 models with ImageNet ILSVRC 2012 dataset are very impressive with 4.29X and 2.84X computation reduction while only sacrificing about 1.40\% top-5 accuracy. Compared to many prior works, the pruned models produced by our technique require up to 47.7\% less computation while still achieve higher accuracies.