 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Synthesis Meets Machine Learning: Trading Exactness for Generalization
Dec 15, 2020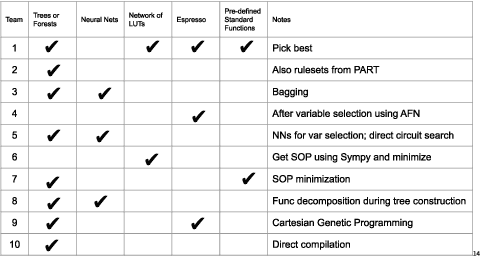
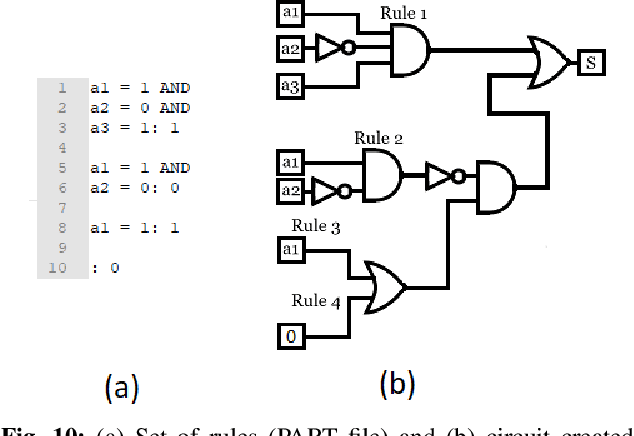
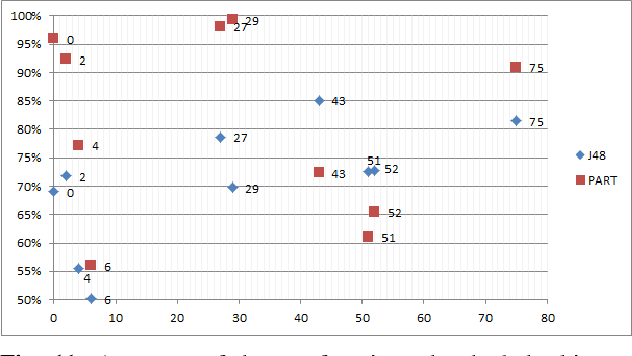
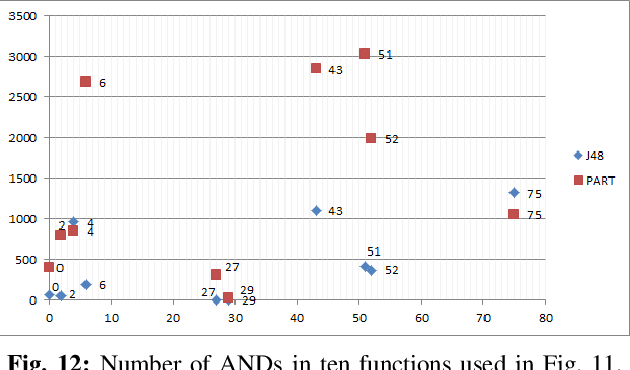
Logic synthesis is a fundamental step in hardware design whose goal is to find structural representations of Boolean functions while minimizing delay and area. If the function is completely-specified, the implementation accurately represents the function. If the function is incompletely-specified, the implementation has to be true only on the care set. While most of the algorithms in logic synthesis rely on SAT and Boolean methods to exactly implement the care set, we investigate learning in logic synthesis, attempting to trade exactness for generalization. This work is directly related to machine learning where the care set is the training set and the implementation is expected to generalize on a validation set. We present learning incompletely-specified functions based on the results of a competition conducted at IWLS 2020. The goal of the competition was to implement 100 functions given by a set of care minterms for training, while testing the implementation using a set of validation minterms sampled from the same function. We make this benchmark suite available and offer a detailed comparative analysis of the different approaches to learning
Parallel Scheduling Self-attention Mechanism: Generalization and Optimization
Dec 02, 2020

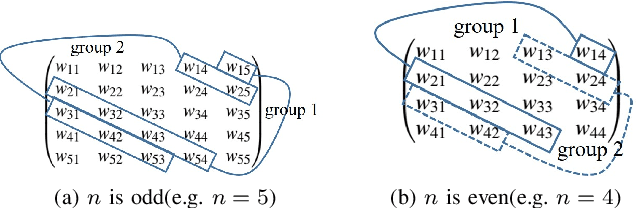
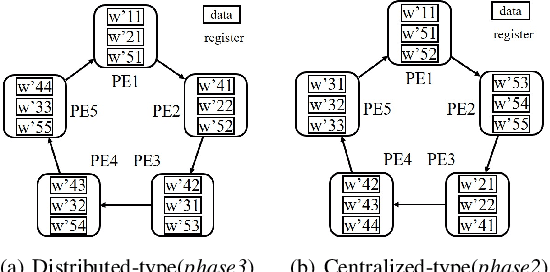
Over the past few years, self-attention is shining in the field of deep learning, especially in the domain of natural language processing(NLP). Its impressive effectiveness, along with ubiquitous implementations, have aroused our interest in efficiently scheduling the data-flow of corresponding computations onto architectures with many computing units to realize parallel computing. In this paper, based on the theory of self-attention mechanism and state-of-the-art realization of self-attention in language models, we propose a general scheduling algorithm, which is derived from the optimum scheduling for small instances solved by a satisfiability checking(SAT) solver, to parallelize typical computations of self-attention. Strategies for further optimization on skipping redundant computations are put forward as well, with which reductions of almost 25% and 50% of the original computations are respectively achieved for two widely-adopted application schemes of self-attention. With the proposed optimization adopted, we have correspondingly come up with another two scheduling algorithms. The proposed algorithms are applicable regardless of problem sizes, as long as the number of input vectors is divisible to the number of computing units available in the architecture. Due to the complexity of proving the correctness of the algorithms mathematically for general cases, we have conducted experiments to reveal their validity, together with the superior quality of the solutions provided by which, by solving SAT problems for particular instances.