 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Scheduling Self-attention Mechanism: Generalization and Optimization
Paper and Code
Dec 02, 2020

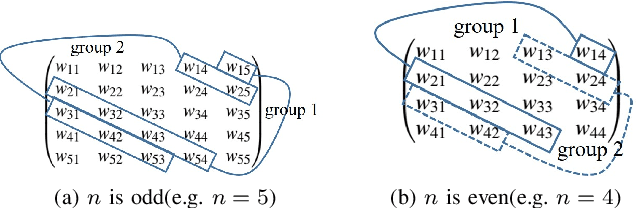
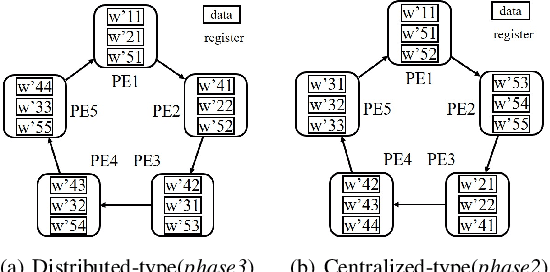
Over the past few years, self-attention is shining in the field of deep learning, especially in the domain of natural language processing(NLP). Its impressive effectiveness, along with ubiquitous implementations, have aroused our interest in efficiently scheduling the data-flow of corresponding computations onto architectures with many computing units to realize parallel computing. In this paper, based on the theory of self-attention mechanism and state-of-the-art realization of self-attention in language models, we propose a general scheduling algorithm, which is derived from the optimum scheduling for small instances solved by a satisfiability checking(SAT) solver, to parallelize typical computations of self-attention. Strategies for further optimization on skipping redundant computations are put forward as well, with which reductions of almost 25% and 50% of the original computations are respectively achieved for two widely-adopted application schemes of self-attention. With the proposed optimization adopted, we have correspondingly come up with another two scheduling algorithms. The proposed algorithms are applicable regardless of problem sizes, as long as the number of input vectors is divisible to the number of computing units available in the architecture. Due to the complexity of proving the correctness of the algorithms mathematically for general cases, we have conducted experiments to reveal their validity, together with the superior quality of the solutions provided by which, by solving SAT problems for particular instances.