 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of A Low-Latency and Parallelizable SVD Dataflow Architecture on FPGA
Nov 18, 2025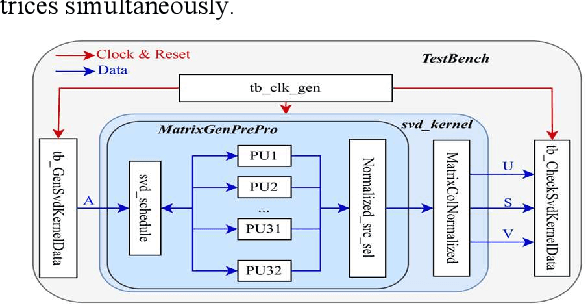
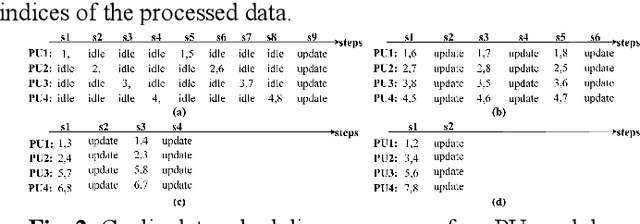
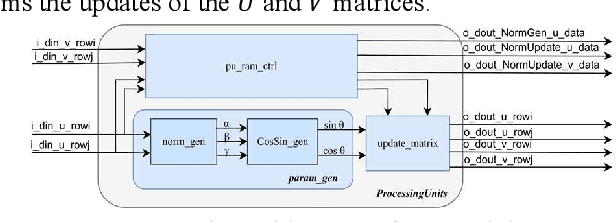
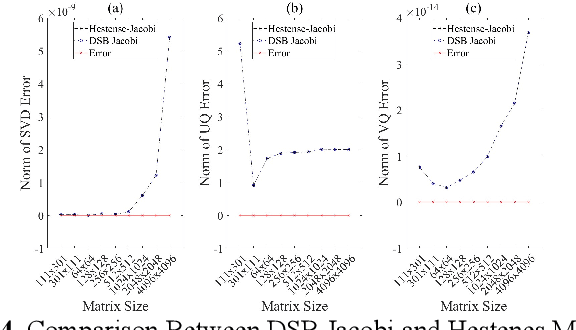
Singular value decomposition (SVD) is widely used for dimensionality reduction and noise suppression, and it plays a pivotal role in numerous scientific and engineering applications. As the dimensions of the matrix grow rapidly, the computational cost increases significantly, posing a serious challenge to the efficiency of data analysis and signal processing systems,especially in time-sensitive scenarios with large-scale datasets. Although various dedicated hardware architectures have been proposed to accelerate the computation of intensive SVD, many of these designs suffer from limited scalability and high consumption of on-chip memory resources. Moreover, they typically overlook the computational and data transfer challenges associated with SVD, enabling them unsuitable for real-time processing of large-scale data stream matrices in embedded systems. In this express, we propose a Data Stream-Based SVD processing algorithm (DSB Jacobi), which significantly reduces on-chip BRAM usage while improving computational speed, offering a practical solution for real-time SVD computation of large-scale data streams. Compared with previous works, our experimental results indicate that the proposed method reduces on-chip RAM consumption by 41.5 percent and improves computational efficiency by 23 times.
C-DOG: Training-Free Multi-View Multi-Object Association in Dense Scenes Without Visual Feature via Connected δ-Overlap Graphs
Jul 18, 2025



Multi-view multi-object association is a fundamental step in 3D reconstruction pipelines, enabling consistent grouping of object instances across multiple camera views. Existing methods often rely on appearance features or geometric constraints such as epipolar consistency. However, these approaches can fail when objects are visually indistinguishable or observations are corrupted by noise. We propose C-DOG, a training-free framework that serves as an intermediate module bridging object detection (or pose estimation) and 3D reconstruction, without relying on visual features. It combines connected delta-overlap graph modeling with epipolar geometry to robustly associate detections across views. Each 2D observation is represented as a graph node, with edges weighted by epipolar consistency. A delta-neighbor-overlap clustering step identifies strongly consistent groups while tolerating noise and partial connectivity. To further improve robustness, we incorporate Interquartile Range (IQR)-based filtering and a 3D back-projection error criterion to eliminate inconsistent observations. Extensive experiments on synthetic benchmarks demonstrate that C-DOG outperforms geometry-based baselines and remains robust under challenging conditions, including high object density, without visual features, and limited camera overlap, making it well-suited for scalable 3D reconstruction in real-world scenarios.
CSASN: A Multitask Attention-Based Framework for Heterogeneous Thyroid Carcinoma Classification in Ultrasound Images
May 04, 2025Heterogeneous morphological features and data imbalance pose significant challenges in rare thyroid carcinoma classification using ultrasound imaging. To address this issue, we propose a novel multitask learning framework, Channel-Spatial Attention Synergy Network (CSASN), which integrates a dual-branch feature extractor - combining EfficientNet for local spatial encoding and ViT for global semantic modeling, with a cascaded channel-spatial attention refinement module. A residual multiscale classifier and dynamically weighted loss function further enhance classification stability and accuracy. Trained on a multicenter dataset comprising more than 2000 patients from four clinical institutions, our framework leverages a residual multiscale classifier and dynamically weighted loss function to enhance classification stability and accuracy. Extensive ablation studies demonstrate that each module contributes significantly to model performance, particularly in recognizing rare subtypes such as FTC and MTC carcinomas. Experimental results show that CSASN outperforms existing single-stream CNN or Transformer-based models, achieving a superior balance between precision and recall under class-imbalanced conditions. This framework provides a promising strategy for AI-assisted thyroid cancer diagnosis.
Detection of Disease on Nasal Breath Sound by New Lightweight Architecture: Using COVID-19 as An Example
Apr 01, 2025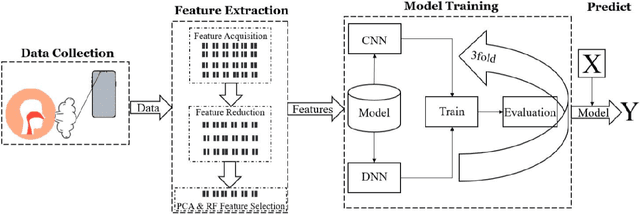



Background. Infectious diseases, particularly COVID-19, continue to be a significant global health issue. Although many countries have reduced or stopped large-scale testing measures, the detection of such diseases remains a propriety. Objective. This study aims to develop a novel, lightweight deep neural network for efficient, accurate, and cost-effective detection of COVID-19 using a nasal breathing audio data collected via smartphones. Methodology. Nasal breathing audio from 128 patients diagnosed with the Omicron variant was collected. Mel-Frequency Cepstral Coefficients (MFCCs), a widely used feature in speech and sound analysis, were employed for extracting important characteristics from the audio signals. Additional feature selection was performed using Random Forest (RF) and Principal Component Analysis (PCA) for dimensionality reduction. A Dense-ReLU-Dropout model was trained with K-fold cross-validation (K=3), and performance metrics like accuracy, precision, recall, and F1-score were used to evaluate the model. Results. The proposed model achieved 97% accuracy in detecting COVID-19 from nasal breathing sounds, outperforming state-of-the-art methods such as those by [23] and [13]. Our Dense-ReLU-Dropout model, using RF and PCA for feature selection, achieves high accuracy with greater computational efficiency compared to existing methods that require more complex models or larger datasets. Conclusion. The findings suggest that the proposed method holds significant potential for clinical implementation, advancing smartphone-based diagnostics in infectious diseases. The Dense-ReLU-Dropout model, combined with innovative feature processing techniques, offers a promising approach for efficient and accurate COVID-19 detection, showcasing the capabilities of mobile device-based diagnostics
EasyVis2: A Real Time Multi-view 3D Visualization for Laparoscopic Surgery Training Enhanced by a Deep Neural Network YOLOv8-Pose
Dec 21, 2024



EasyVis2 is a system designed for hands-free, real-time 3D visualization during laparoscopic surgery. It incorporates a surgical trocar equipped with a set of micro-cameras, which are inserted into the body cavity to provide an expanded field of view and a 3D perspective of the surgical procedure. A sophisticated deep neural network algorithm, YOLOv8-Pose, is tailored to estimate the position and orientation of surgical instruments in each individual camera view. Subsequently, 3D surgical tool pose estimation is performed using associated 2D key points across multiple views. This enables the rendering of a 3D surface model of the surgical tools overlaid on the observed background scene for real-time visualization. In this study, we explain the process of developing a training dataset for new surgical tools to customize YoLOv8-Pose while minimizing labeling efforts. Extensive experiments were conducted to compare EasyVis2 with the original EasyVis, revealing that, with the same number of cameras, the new system improves 3D reconstruction accuracy and reduces computation time. Additionally, experiments with 3D rendering on real animal tissue visually demonstrated the distance between surgical tools and tissues by displaying virtual side views, indicating potential applications in real surgeries in the future.
A Semi-Supervised Approach with Error Reflection for Echocardiography Segmentation
Dec 01, 2024



Segmenting internal structure from echocardiography is essential for the diagnosis and treatment of various heart diseases. Semi-supervised learning shows its ability in alleviating annotations scarcity. While existing semi-supervised methods have been successful in image segmentation across various medical imaging modalities, few have attempted to design methods specifically addressing the challenges posed by the poor contrast, blurred edge details and noise of echocardiography. These characteristics pose challenges to the generation of high-quality pseudo-labels in semi-supervised segmentation based on Mean Teacher. Inspired by human reflection on erroneous practices, we devise an error reflection strategy for echocardiography semi-supervised segmentation architecture. The process triggers the model to reflect on inaccuracies in unlabeled image segmentation, thereby enhancing the robustness of pseudo-label generation. Specifically, the strategy is divided into two steps. The first step is called reconstruction reflection. The network is tasked with reconstructing authentic proxy images from the semantic masks of unlabeled images and their auxiliary sketches, while maximizing the structural similarity between the original inputs and the proxies. The second step is called guidance correction. Reconstruction error maps decouple unreliable segmentation regions. Then, reliable data that are more likely to occur near high-density areas are leveraged to guide the optimization of unreliable data potentially located around decision boundaries. Additionally, we introduce an effective data augmentation strategy, termed as multi-scale mixing up strategy, to minimize the empirical distribution gap between labeled and unlabeled images and perceive diverse scales of cardiac anatomical structures. Extensive experiments demonstrate the competitiveness of the proposed method.
A Wearable Gait Monitoring System for 17 Gait Parameters Based on Computer Vision
Nov 16, 2024



We developed a shoe-mounted gait monitoring system capable of tracking up to 17 gait parameters, including gait length, step time, stride velocity, and others. The system employs a stereo camera mounted on one shoe to track a marker placed on the opposite shoe, enabling the estimation of spatial gait parameters. Additionally, a Force Sensitive Resistor (FSR) affixed to the heel of the shoe, combined with a custom-designed algorithm, is utilized to measure temporal gait parameters. Through testing on multiple participants and comparison with the gait mat, the proposed gait monitoring system exhibited notable performance, with the accuracy of all measured gait parameters exceeding 93.61%. The system also demonstrated a low drift of 4.89% during long-distance walking. A gait identification task conducted on participants using a trained Transformer model achieved 95.7% accuracy on the dataset collected by the proposed system, demonstrating that our hardware has the potential to collect long-sequence gait data suitable for integration with current Large Language Models (LLMs). The system is cost-effective, user-friendly, and well-suited for real-life measurements.
Distance Guided Generative Adversarial Network for Explainable Binary Classifications
Dec 29, 2023Despite the potential benefits of data augmentation for mitigating the data insufficiency, traditional augmentation methods primarily rely on the prior intra-domain knowledge. On the other hand, advanced generative adversarial networks (GANs) generate inter-domain samples with limited variety. These previous methods make limited contributions to describing the decision boundaries for binary classification. In this paper, we propose a distance guided GAN (DisGAN) which controls the variation degrees of generated samples in the hyperplane space. Specifically, we instantiate the idea of DisGAN by combining two ways. The first way is vertical distance GAN (VerDisGAN) where the inter-domain generation is conditioned on the vertical distances. The second way is horizontal distance GAN (HorDisGAN) where the intra-domain generation is conditioned on the horizontal distances. Furthermore, VerDisGAN can produce the class-specific regions by mapping the source images to the hyperplane. Experimental results show that DisGAN consistently outperforms the GAN-based augmentation methods with explainable binary classification. The proposed method can apply to different classification architectures and has potential to extend to multi-class classification.
Atrial Septal Defect Detection in Children Based on Ultrasound Video Using Multiple Instances Learning
Jun 06, 2023

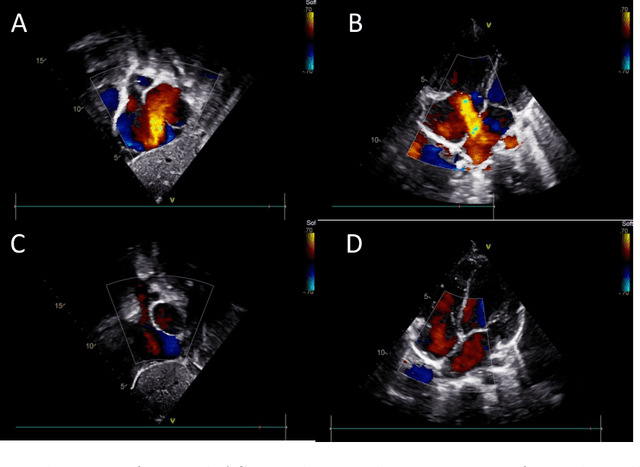
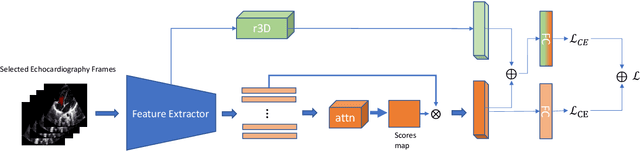
Purpose: Congenital heart defect (CHD) is the most common birth defect. Thoracic echocardiography (TTE) can provide sufficient cardiac structure information, evaluate hemodynamics and cardiac function, and is an effective method for atrial septal defect (ASD) examination. This paper aims to study a deep learning method based on cardiac ultrasound video to assist in ASD diagnosis. Materials and methods: We select two standard views of the atrial septum (subAS) and low parasternal four-compartment view (LPS4C) as the two views to identify ASD. We enlist data from 300 children patients as part of a double-blind experiment for five-fold cross-validation to verify the performance of our model. In addition, data from 30 children patients (15 positives and 15 negatives) are collected for clinician testing and compared to our model test results (these 30 samples do not participate in model training). We propose an echocardiography video-based atrial septal defect diagnosis system. In our model, we present a block random selection, maximal agreement decision and frame sampling strategy for training and testing respectively, resNet18 and r3D networks are used to extract the frame features and aggregate them to build a rich video-level representation. Results: We validate our model using our private dataset by five-cross validation. For ASD detection, we achieve 89.33 AUC, 84.95 accuracy, 85.70 sensitivity, 81.51 specificity and 81.99 F1 score. Conclusion: The proposed model is multiple instances learning-based deep learning model for video atrial septal defect detection which effectively improves ASD detection accuracy when compared to the performances of previous networks and clinical doctors.