 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Minima of ReLU Neural Networks Suffer from the Curse of Dimensionality: The Neural Shattering Phenomenon
Jun 25, 2025We study the implicit bias of flatness / low (loss) curvature and its effects on generalization in two-layer overparameterized ReLU networks with multivariate inputs -- a problem well motivated by the minima stability and edge-of-stability phenomena in gradient-descent training. Existing work either requires interpolation or focuses only on univariate inputs. This paper presents new and somewhat surprising theoretical results for multivariate inputs. On two natural settings (1) generalization gap for flat solutions, and (2) mean-squared error (MSE) in nonparametric function estimation by stable minima, we prove upper and lower bounds, which establish that while flatness does imply generalization, the resulting rates of convergence necessarily deteriorate exponentially as the input dimension grows. This gives an exponential separation between the flat solutions vis-\`a-vis low-norm solutions (i.e., weight decay), which knowingly do not suffer from the curse of dimensionality. In particular, our minimax lower bound construction, based on a novel packing argument with boundary-localized ReLU neurons, reveals how flat solutions can exploit a kind of ''neural shattering'' where neurons rarely activate, but with high weight magnitudes. This leads to poor performance in high dimensions. We corroborate these theoretical findings with extensive numerical simulations. To the best of our knowledge, our analysis provides the first systematic explanation for why flat minima may fail to generalize in high dimensions.
Atrial Septal Defect Detection in Children Based on Ultrasound Video Using Multiple Instances Learning
Jun 06, 2023

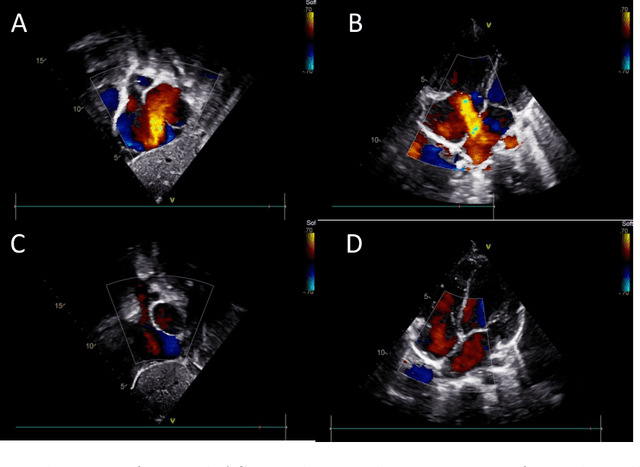
Purpose: Congenital heart defect (CHD) is the most common birth defect. Thoracic echocardiography (TTE) can provide sufficient cardiac structure information, evaluate hemodynamics and cardiac function, and is an effective method for atrial septal defect (ASD) examination. This paper aims to study a deep learning method based on cardiac ultrasound video to assist in ASD diagnosis. Materials and methods: We select two standard views of the atrial septum (subAS) and low parasternal four-compartment view (LPS4C) as the two views to identify ASD. We enlist data from 300 children patients as part of a double-blind experiment for five-fold cross-validation to verify the performance of our model. In addition, data from 30 children patients (15 positives and 15 negatives) are collected for clinician testing and compared to our model test results (these 30 samples do not participate in model training). We propose an echocardiography video-based atrial septal defect diagnosis system. In our model, we present a block random selection, maximal agreement decision and frame sampling strategy for training and testing respectively, resNet18 and r3D networks are used to extract the frame features and aggregate them to build a rich video-level representation. Results: We validate our model using our private dataset by five-cross validation. For ASD detection, we achieve 89.33 AUC, 84.95 accuracy, 85.70 sensitivity, 81.51 specificity and 81.99 F1 score. Conclusion: The proposed model is multiple instances learning-based deep learning model for video atrial septal defect detection which effectively improves ASD detection accuracy when compared to the performances of previous networks and clinical doctors.
EDMAE: An Efficient Decoupled Masked Autoencoder for Standard View Identification in Pediatric Echocardiography
Mar 17, 2023
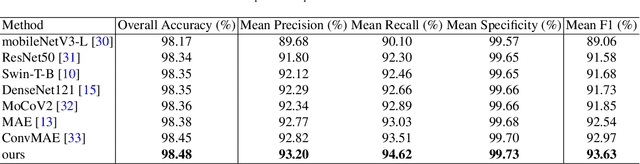

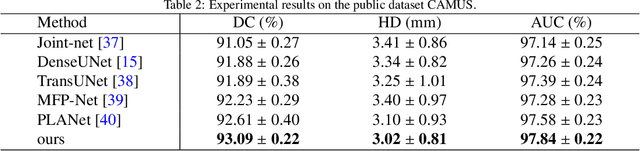
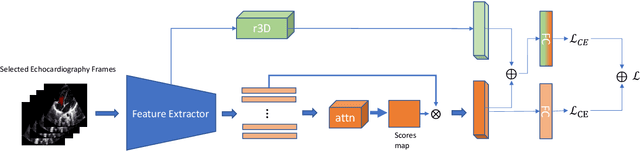
An efficient decoupled masked autoencoder (EDMAE), which is a novel self-supervised method is proposed for standard view recognition in pediatric echocardiography in this paper. The proposed EDMAE based on the encoder-decoder structure forms a new proxy task. The decoder of EDMAE consists of a teacher encoder and a student encoder, in which the teacher encoder extracts the latent representation of the masked image blocks, while the student encoder extracts the latent representation of the visible image blocks. A loss is calculated between the feature maps output from two encoders to ensure consistency in the latent representations they extracted. EDMAE replaces the VIT structure in the encoder of traditional MAE with pure convolution operation to improve training efficiency. EDMAE is pre-trained in a self-supervised manner on a large-scale private dataset of pediatric echocardiography, and then fine-tuned on the downstream task of standard view recognition. The high classification accuracy is achieved in 27 standard views of pediatric echocardiography. To further validate the effectiveness of the proposed method, another downstream task of cardiac ultrasound segmentation is performed on a public dataset CAMUS. The experiments show that the proposed method not only can surpass some recent supervised methods but also has more competitiveness on different downstream tasks.