 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Costs in Data Science: Foundations and the Quasi-Banach Spaces of Deep Neural Networks
Jun 16, 2026We develop a general framework for analyzing representation costs of parametric data-fitting methods through their parameter-space regularizers. From this abstract perspective, we define representation costs for arbitrary parametric models and reveal their induced (native) function spaces. This unifies recent function-space views of data-fitting methods. We also prove that many natural results hold in this abstract setting, including representer theorems for parametric methods on their native spaces. The framework also rigorously connects parametric methods with their equivalent nonparametric descriptions under sufficient overparameterization. Classical methods and their native spaces, such as kernel methods / reproducing kernel Hilbert spaces, wavelets / Besov spaces, and shallow neural networks / variation spaces emerge as special cases of our abstract framework. A byproduct of "axiomatizing" the study of representation costs is that we also immediately obtain new results for deep neural networks: For depth-$L$ feedforward ReLU networks, their induced native spaces are $p$-normable quasi-Banach spaces with $p = 2/L$. This reveals that the inductive bias of deep neural networks (as given by the representation cost) cannot be captured by norms for depths $L > 2$.
On the Loss Landscape Geometry of Regularized Deep Matrix Factorization: Uniqueness and Sharpness
Mar 28, 2026Weight decay is ubiquitous in training deep neural network architectures. Its empirical success is often attributed to capacity control; nonetheless, our theoretical understanding of its effect on the loss landscape and the set of minimizers remains limited. In this paper, we show that $\ell^2$-regularized deep matrix factorization/deep linear network training problems with squared-error loss admit a unique end-to-end minimizer for all target matrices subject to factorization, except for a set of Lebesgue measure zero formed by the depth and the regularization parameter. This observation reveals fundamental properties of the loss landscape of regularized deep matrix factorization problems: the Hessian spectrum is constant across all minimizers of the regularized deep scalar factorization problem with squared-error loss. Moreover, we show that, in regularized deep matrix factorization problems with squared-error loss, if the target matrix does not belong to the Lebesgue measure-zero set, then the Frobenius norm of each layer is constant across all minimizers. This, in turn, yields a global lower bound on the trace of the Hessian evaluated at any minimizer of the regularized deep matrix factorization problem. Furthermore, we establish a critical threshold for the regularization parameter above which the unique end-to-end minimizer collapses to zero.
The Inductive Bias of Convolutional Neural Networks: Locality and Weight Sharing Reshape Implicit Regularization
Mar 05, 2026We study how architectural inductive bias reshapes the implicit regularization induced by the edge-of-stability phenomenon in gradient descent. Prior work has established that for fully connected networks, the strength of this regularization is governed solely by the global input geometry; consequently, it is insufficient to prevent overfitting on difficult distributions such as the high-dimensional sphere. In this paper, we show that locality and weight sharing fundamentally change this picture. Specifically, we prove that provided the receptive field size $m$ remains small relative to the ambient dimension $d$, these networks generalize on spherical data with a rate of $n^{-\frac{1}{6} +O(m/d)}$, a regime where fully connected networks provably fail. This theoretical result confirms that weight sharing couples the learned filters to the low-dimensional patch manifold, thereby bypassing the high dimensionality of the ambient space. We further corroborate our theory by analyzing the patch geometry of natural images, showing that standard convolutional designs induce patch distributions that are highly amenable to this stability mechanism, thus providing a systematic explanation for the superior generalization of convolutional networks over fully connected baselines.
Towards Sharp Minimax Risk Bounds for Operator Learning
Dec 19, 2025We develop a minimax theory for operator learning, where the goal is to estimate an unknown operator between separable Hilbert spaces from finitely many noisy input-output samples. For uniformly bounded Lipschitz operators, we prove information-theoretic lower bounds together with matching or near-matching upper bounds, covering both fixed and random designs under Hilbert-valued Gaussian noise and Gaussian white noise errors. The rates are controlled by the spectrum of the covariance operator of the measure that defines the error metric. Our setup is very general and allows for measures with unbounded support. A key implication is a curse of sample complexity which shows that the minimax risk for generic Lipschitz operators cannot decay at any algebraic rate in the sample size. We obtain essentially sharp characterizations when the covariance spectrum decays exponentially and provide general upper and lower bounds in slower-decay regimes.
Nonasymptotic Convergence Rates for Plug-and-Play Methods With MMSE Denoisers
Oct 31, 2025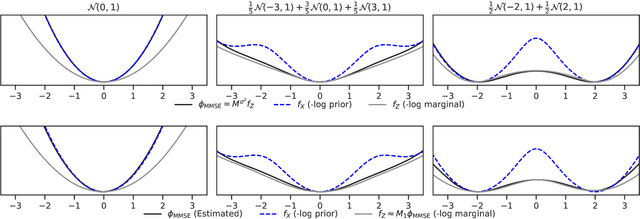



It is known that the minimum-mean-squared-error (MMSE) denoiser under Gaussian noise can be written as a proximal operator, which suffices for asymptotic convergence of plug-and-play (PnP) methods but does not reveal the structure of the induced regularizer or give convergence rates. We show that the MMSE denoiser corresponds to a regularizer that can be written explicitly as an upper Moreau envelope of the negative log-marginal density, which in turn implies that the regularizer is 1-weakly convex. Using this property, we derive (to the best of our knowledge) the first sublinear convergence guarantee for PnP proximal gradient descent with an MMSE denoiser. We validate the theory with a one-dimensional synthetic study that recovers the implicit regularizer. We also validate the theory with imaging experiments (deblurring and computed tomography), which exhibit the predicted sublinear behavior.
Stable Minima of ReLU Neural Networks Suffer from the Curse of Dimensionality: The Neural Shattering Phenomenon
Jun 25, 2025We study the implicit bias of flatness / low (loss) curvature and its effects on generalization in two-layer overparameterized ReLU networks with multivariate inputs -- a problem well motivated by the minima stability and edge-of-stability phenomena in gradient-descent training. Existing work either requires interpolation or focuses only on univariate inputs. This paper presents new and somewhat surprising theoretical results for multivariate inputs. On two natural settings (1) generalization gap for flat solutions, and (2) mean-squared error (MSE) in nonparametric function estimation by stable minima, we prove upper and lower bounds, which establish that while flatness does imply generalization, the resulting rates of convergence necessarily deteriorate exponentially as the input dimension grows. This gives an exponential separation between the flat solutions vis-\`a-vis low-norm solutions (i.e., weight decay), which knowingly do not suffer from the curse of dimensionality. In particular, our minimax lower bound construction, based on a novel packing argument with boundary-localized ReLU neurons, reveals how flat solutions can exploit a kind of ''neural shattering'' where neurons rarely activate, but with high weight magnitudes. This leads to poor performance in high dimensions. We corroborate these theoretical findings with extensive numerical simulations. To the best of our knowledge, our analysis provides the first systematic explanation for why flat minima may fail to generalize in high dimensions.
LoLA: Low-Rank Linear Attention With Sparse Caching
May 29, 2025Transformer-based large language models suffer from quadratic complexity at inference on long sequences. Linear attention methods are efficient alternatives, however, they fail to provide an accurate approximation of softmax attention. By additionally incorporating sliding window attention into each linear attention head, this gap can be closed for short context-length tasks. Unfortunately, these approaches cannot recall important information from long contexts due to "memory collisions". In this paper , we propose LoLA: Low-rank Linear Attention with sparse caching. LoLA separately stores additional key-value pairs that would otherwise interfere with past associative memories. Moreover, LoLA further closes the gap between linear attention models and transformers by distributing past key-value pairs into three forms of memory: (i) recent pairs in a local sliding window; (ii) difficult-to-memorize pairs in a sparse, global cache; and (iii) generic pairs in the recurrent hidden state of linear attention. As an inference-only strategy, LoLA enables pass-key retrieval on up to 8K context lengths on needle-in-a-haystack tasks from RULER. It boosts the accuracy of the base subquadratic model from 0.6% to 97.4% at 4K context lengths, with a 4.6x smaller cache than that of Llama-3.1 8B. LoLA demonstrates strong performance on zero-shot commonsense reasoning tasks among 1B and 8B parameter subquadratic models. Finally, LoLA is an extremely lightweight approach: Nearly all of our results can be reproduced on a single consumer GPU.
Optimal Recovery Meets Minimax Estimation
Feb 24, 2025A fundamental problem in statistics and machine learning is to estimate a function $f$ from possibly noisy observations of its point samples. The goal is to design a numerical algorithm to construct an approximation $\hat f$ to $f$ in a prescribed norm that asymptotically achieves the best possible error (as a function of the number $m$ of observations and the variance $\sigma^2$ of the noise). This problem has received considerable attention in both nonparametric statistics (noisy observations) and optimal recovery (noiseless observations). Quantitative bounds require assumptions on $f$, known as model class assumptions. Classical results assume that $f$ is in the unit ball of a Besov space. In nonparametric statistics, the best possible performance of an algorithm for finding $\hat f$ is known as the minimax rate and has been studied in this setting under the assumption that the noise is Gaussian. In optimal recovery, the best possible performance of an algorithm is known as the optimal recovery rate and has also been determined in this setting. While one would expect that the minimax rate recovers the optimal recovery rate when the noise level $\sigma$ tends to zero, it turns out that the current results on minimax rates do not carefully determine the dependence on $\sigma$ and the limit cannot be taken. This paper handles this issue and determines the noise-level-aware (NLA) minimax rates for Besov classes when error is measured in an $L_q$-norm with matching upper and lower bounds. The end result is a reconciliation between minimax rates and optimal recovery rates. The NLA minimax rate continuously depends on the noise level and recovers the optimal recovery rate when $\sigma$ tends to zero.
A Gap Between the Gaussian RKHS and Neural Networks: An Infinite-Center Asymptotic Analysis
Feb 22, 2025
Recent works have characterized the function-space inductive bias of infinite-width bounded-norm single-hidden-layer neural networks as a kind of bounded-variation-type space. This novel neural network Banach space encompasses many classical multivariate function spaces including certain Sobolev spaces and the spectral Barron spaces. Notably, this Banach space also includes functions that exhibit less classical regularity such as those that only vary in a few directions. On bounded domains, it is well-established that the Gaussian reproducing kernel Hilbert space (RKHS) strictly embeds into this Banach space, demonstrating a clear gap between the Gaussian RKHS and the neural network Banach space. It turns out that when investigating these spaces on unbounded domains, e.g., all of $\mathbb{R}^d$, the story is fundamentally different. We establish the following fundamental result: Certain functions that lie in the Gaussian RKHS have infinite norm in the neural network Banach space. This provides a nontrivial gap between kernel methods and neural networks by the exhibition of functions in which kernel methods can do strictly better than neural networks.
Random ReLU Neural Networks as Non-Gaussian Processes
May 16, 2024

We consider a large class of shallow neural networks with randomly initialized parameters and rectified linear unit activation functions. We prove that these random neural networks are well-defined non-Gaussian processes. As a by-product, we demonstrate that these networks are solutions to stochastic differential equations driven by impulsive white noise (combinations of random Dirac measures). These processes are parameterized by the law of the weights and biases as well as the density of activation thresholds in each bounded region of the input domain. We prove that these processes are isotropic and wide-sense self-similar with Hurst exponent $3/2$. We also derive a remarkably simple closed-form expression for their autocovariance function. Our results are fundamentally different from prior work in that we consider a non-asymptotic viewpoint: The number of neurons in each bounded region of the input domain (i.e., the width) is itself a random variable with a Poisson law with mean proportional to the density parameter. Finally, we show that, under suitable hypotheses, as the expected width tends to infinity, these processes can converge in law not only to Gaussian processes, but also to non-Gaussian processes depending on the law of the weights. Our asymptotic results provide a new take on several classical results (wide networks converge to Gaussian processes) as well as some new ones (wide networks can converge to non-Gaussian processes).