 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoLA: Low-Rank Linear Attention With Sparse Caching
May 29, 2025Transformer-based large language models suffer from quadratic complexity at inference on long sequences. Linear attention methods are efficient alternatives, however, they fail to provide an accurate approximation of softmax attention. By additionally incorporating sliding window attention into each linear attention head, this gap can be closed for short context-length tasks. Unfortunately, these approaches cannot recall important information from long contexts due to "memory collisions". In this paper , we propose LoLA: Low-rank Linear Attention with sparse caching. LoLA separately stores additional key-value pairs that would otherwise interfere with past associative memories. Moreover, LoLA further closes the gap between linear attention models and transformers by distributing past key-value pairs into three forms of memory: (i) recent pairs in a local sliding window; (ii) difficult-to-memorize pairs in a sparse, global cache; and (iii) generic pairs in the recurrent hidden state of linear attention. As an inference-only strategy, LoLA enables pass-key retrieval on up to 8K context lengths on needle-in-a-haystack tasks from RULER. It boosts the accuracy of the base subquadratic model from 0.6% to 97.4% at 4K context lengths, with a 4.6x smaller cache than that of Llama-3.1 8B. LoLA demonstrates strong performance on zero-shot commonsense reasoning tasks among 1B and 8B parameter subquadratic models. Finally, LoLA is an extremely lightweight approach: Nearly all of our results can be reproduced on a single consumer GPU.
Neural Architecture Codesign for Fast Physics Applications
Jan 09, 2025



We develop a pipeline to streamline neural architecture codesign for physics applications to reduce the need for ML expertise when designing models for novel tasks. Our method employs neural architecture search and network compression in a two-stage approach to discover hardware efficient models. This approach consists of a global search stage that explores a wide range of architectures while considering hardware constraints, followed by a local search stage that fine-tunes and compresses the most promising candidates. We exceed performance on various tasks and show further speedup through model compression techniques such as quantization-aware-training and neural network pruning. We synthesize the optimal models to high level synthesis code for FPGA deployment with the hls4ml library. Additionally, our hierarchical search space provides greater flexibility in optimization, which can easily extend to other tasks and domains. We demonstrate this with two case studies: Bragg peak finding in materials science and jet classification in high energy physics, achieving models with improved accuracy, smaller latencies, or reduced resource utilization relative to the baseline models.
Embedding Compression for Efficient Re-Identification
May 23, 2024



Real world re-identfication (ReID) algorithms aim to map new observations of an object to previously recorded instances. These systems are often constrained by quantity and size of the stored embeddings. To combat this scaling problem, we attempt to shrink the size of these vectors by using a variety of compression techniques. In this paper, we benchmark quantization-aware-training along with three different dimension reduction methods: iterative structured pruning, slicing the embeddings at initialize, and using low rank embeddings. We find that ReID embeddings can be compressed by up to 96x with minimal drop in performance. This implies that modern re-identification paradigms do not fully leverage the high dimensional latent space, opening up further research to increase the capabilities of these systems.
Neural Architecture Codesign for Fast Bragg Peak Analysis
Dec 12, 2023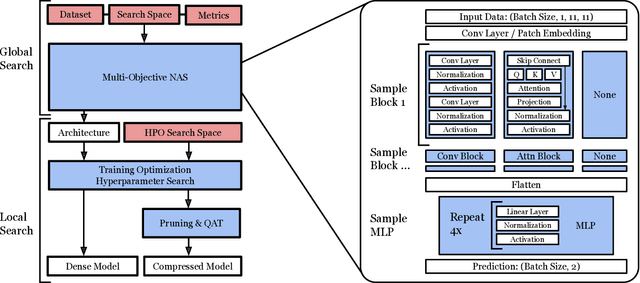
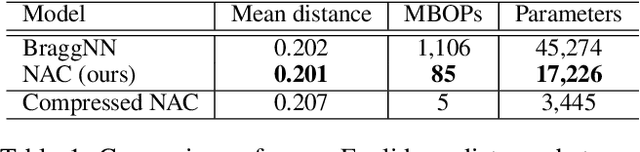
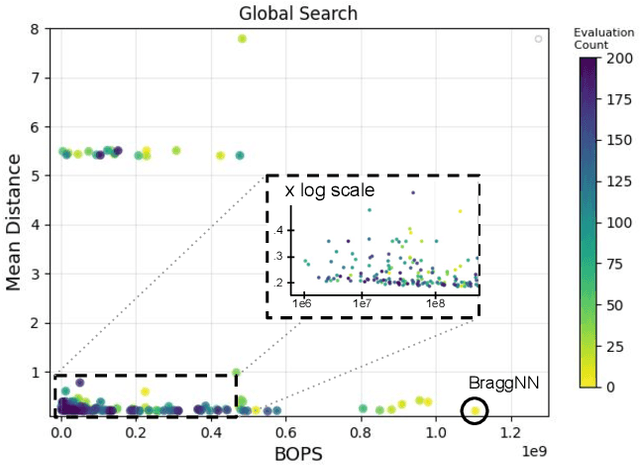

We develop an automated pipeline to streamline neural architecture codesign for fast, real-time Bragg peak analysis in high-energy diffraction microscopy. Traditional approaches, notably pseudo-Voigt fitting, demand significant computational resources, prompting interest in deep learning models for more efficient solutions. Our method employs neural architecture search and AutoML to enhance these models, including hardware costs, leading to the discovery of more hardware-efficient neural architectures. Our results match the performance, while achieving a 13$\times$ reduction in bit operations compared to the previous state-of-the-art. We show further speedup through model compression techniques such as quantization-aware-training and neural network pruning. Additionally, our hierarchical search space provides greater flexibility in optimization, which can easily extend to other tasks and domains.
UniCat: Crafting a Stronger Fusion Baseline for Multimodal Re-Identification
Oct 28, 2023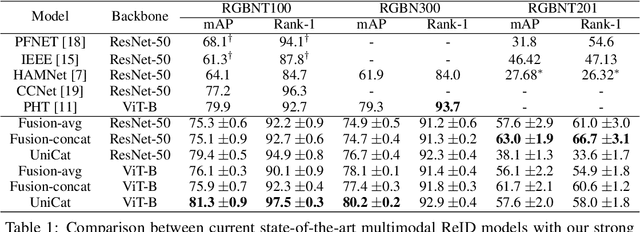

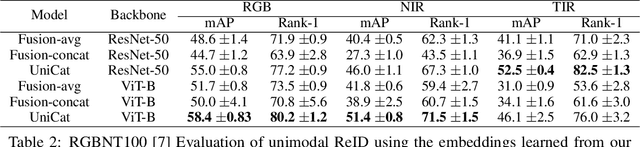
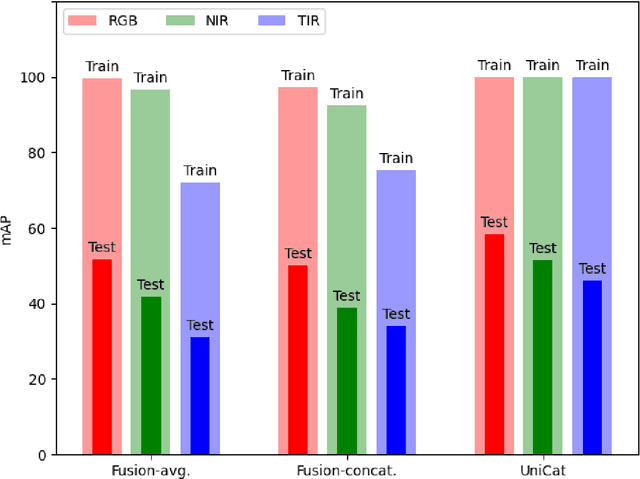
Multimodal Re-Identification (ReID) is a popular retrieval task that aims to re-identify objects across diverse data streams, prompting many researchers to integrate multiple modalities into a unified representation. While such fusion promises a holistic view, our investigations shed light on potential pitfalls. We uncover that prevailing late-fusion techniques often produce suboptimal latent representations when compared to methods that train modalities in isolation. We argue that this effect is largely due to the inadvertent relaxation of the training objectives on individual modalities when using fusion, what others have termed modality laziness. We present a nuanced point-of-view that this relaxation can lead to certain modalities failing to fully harness available task-relevant information, and yet, offers a protective veil to noisy modalities, preventing them from overfitting to task-irrelevant data. Our findings also show that unimodal concatenation (UniCat) and other late-fusion ensembling of unimodal backbones, when paired with best-known training techniques, exceed the current state-of-the-art performance across several multimodal ReID benchmarks. By unveiling the double-edged sword of "modality laziness", we motivate future research in balancing local modality strengths with global representations.
Linear Mode Connectivity in Sparse Neural Networks
Oct 28, 2023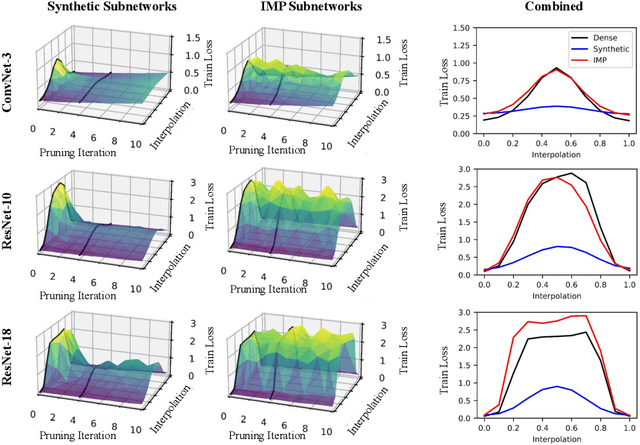
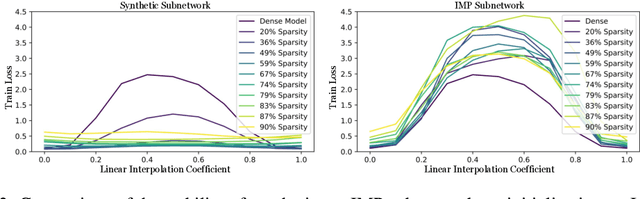
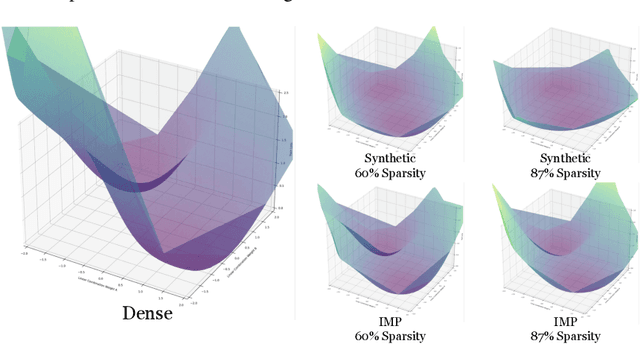
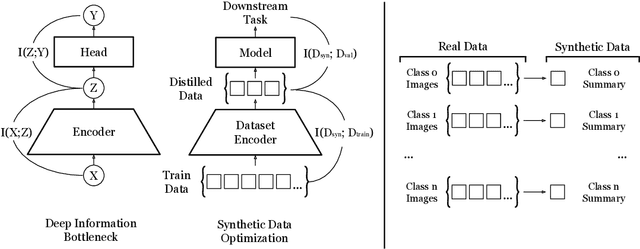
With the rise in interest of sparse neural networks, we study how neural network pruning with synthetic data leads to sparse networks with unique training properties. We find that distilled data, a synthetic summarization of the real data, paired with Iterative Magnitude Pruning (IMP) unveils a new class of sparse networks that are more stable to SGD noise on the real data, than either the dense model, or subnetworks found with real data in IMP. That is, synthetically chosen subnetworks often train to the same minima, or exhibit linear mode connectivity. We study this through linear interpolation, loss landscape visualizations, and measuring the diagonal of the hessian. While dataset distillation as a field is still young, we find that these properties lead to synthetic subnetworks matching the performance of traditional IMP with up to 150x less training points in settings where distilled data applies.
GraFT: Gradual Fusion Transformer for Multimodal Re-Identification
Oct 25, 2023



Object Re-Identification (ReID) is pivotal in computer vision, witnessing an escalating demand for adept multimodal representation learning. Current models, although promising, reveal scalability limitations with increasing modalities as they rely heavily on late fusion, which postpones the integration of specific modality insights. Addressing this, we introduce the \textbf{Gradual Fusion Transformer (GraFT)} for multimodal ReID. At its core, GraFT employs learnable fusion tokens that guide self-attention across encoders, adeptly capturing both modality-specific and object-specific features. Further bolstering its efficacy, we introduce a novel training paradigm combined with an augmented triplet loss, optimizing the ReID feature embedding space. We demonstrate these enhancements through extensive ablation studies and show that GraFT consistently surpasses established multimodal ReID benchmarks. Additionally, aiming for deployment versatility, we've integrated neural network pruning into GraFT, offering a balance between model size and performance.
A Generalization of Continuous Relaxation in Structured Pruning
Aug 28, 2023



Deep learning harnesses massive parallel floating-point processing to train and evaluate large neural networks. Trends indicate that deeper and larger neural networks with an increasing number of parameters achieve higher accuracy than smaller neural networks. This performance improvement, which often requires heavy compute for both training and evaluation, eventually needs to translate well to resource-constrained hardware for practical value. Structured pruning asserts that while large networks enable us to find solutions to complex computer vision problems, a smaller, computationally efficient sub-network can be derived from the large neural network that retains model accuracy but significantly improves computational efficiency. We generalize structured pruning with algorithms for network augmentation, pruning, sub-network collapse and removal. In addition, we demonstrate efficient and stable convergence up to 93% sparsity and 95% FLOPs reduction without loss of inference accuracy using with continuous relaxation matching or exceeding the state of the art for all structured pruning methods. The resulting CNN executes efficiently on GPU hardware without computationally expensive sparse matrix operations. We achieve this with routine automatable operations on classification and segmentation problems using CIFAR-10, ImageNet, and CityScapes datasets with the ResNet and U-NET network architectures.
Distilled Pruning: Using Synthetic Data to Win the Lottery
Jul 11, 2023This work introduces a novel approach to pruning deep learning models by using distilled data. Unlike conventional strategies which primarily focus on architectural or algorithmic optimization, our method reconsiders the role of data in these scenarios. Distilled datasets capture essential patterns from larger datasets, and we demonstrate how to leverage this capability to enable a computationally efficient pruning process. Our approach can find sparse, trainable subnetworks (a.k.a. Lottery Tickets) up to 5x faster than Iterative Magnitude Pruning at comparable sparsity on CIFAR-10. The experimental results highlight the potential of using distilled data for resource-efficient neural network pruning, model compression, and neural architecture search.