 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatBench: Discriminative, Faithful, and Efficient VLM Evaluations
Jan 05, 2026Empirical evaluation serves as the primary compass guiding research progress in foundation models. Despite a large body of work focused on training frontier vision-language models (VLMs), approaches to their evaluation remain nascent. To guide their maturation, we propose three desiderata that evaluations should satisfy: (1) faithfulness to the modality and application, (2) discriminability between models of varying quality, and (3) efficiency in compute. Through this lens, we identify critical failure modes that violate faithfulness and discriminability, misrepresenting model capabilities: (i) multiple-choice formats reward guessing, poorly reflect downstream use cases, and saturate early as models improve; (ii) blindly solvable questions, which can be answered without images, constitute up to 70% of some evaluations; and (iii) mislabeled or ambiguous samples compromise up to 42% of examples in certain datasets. Regarding efficiency, the computational burden of evaluating frontier models has become prohibitive: by some accounts, nearly 20% of development compute is devoted to evaluation alone. Rather than discarding existing benchmarks, we curate them via transformation and filtering to maximize fidelity and discriminability. We find that converting multiple-choice questions to generative tasks reveals sharp capability drops of up to 35%. In addition, filtering blindly solvable and mislabeled samples improves discriminative power while simultaneously reducing computational cost. We release DatBench-Full, a cleaned evaluation suite of 33 datasets spanning nine VLM capabilities, and DatBench, a discriminative subset that achieves 13x average speedup (up to 50x) while closely matching the discriminative power of the original datasets. Our work outlines a path toward evaluation practices that are both rigorous and sustainable as VLMs continue to scale.
Luxical: High-Speed Lexical-Dense Text Embeddings
Dec 11, 2025Frontier language model quality increasingly hinges on our ability to organize web-scale text corpora for training. Today's dominant tools trade off speed and flexibility: lexical classifiers (e.g., FastText) are fast but limited to producing classification output scores, while the vector-valued outputs of transformer text embedding models flexibly support numerous workflows (e.g., clustering, classification, and retrieval) but are computationally expensive to produce. We introduce Luxical, a library for high-speed "lexical-dense" text embeddings that aims to recover the best properties of both approaches for web-scale text organization. Luxical combines sparse TF--IDF features, a small ReLU network, and a knowledge distillation training regimen to approximate large transformer embedding models at a fraction of their operational cost. In this technical report, we describe the Luxical architecture and training objective and evaluate a concrete Luxical model in two disparate applications: a targeted webcrawl document retrieval test and an end-to-end language model data curation task grounded in text classification. In these tasks we demonstrate speedups ranging from 3x to 100x over varying-sized neural baselines, and comparable to FastText model inference during the data curation task. On these evaluations, the tested Luxical model illustrates favorable compute/quality trade-offs for large-scale text organization, matching the quality of neural baselines. Luxical is available as open-source software at https://github.com/datologyai/luxical.
UniCat: Crafting a Stronger Fusion Baseline for Multimodal Re-Identification
Oct 28, 2023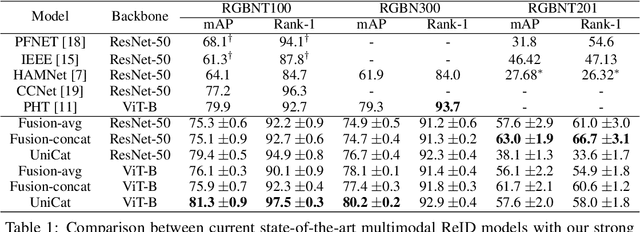

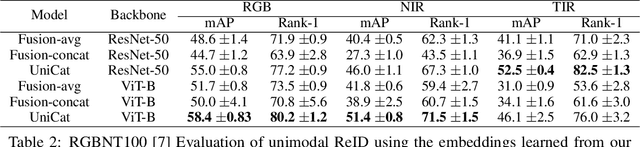
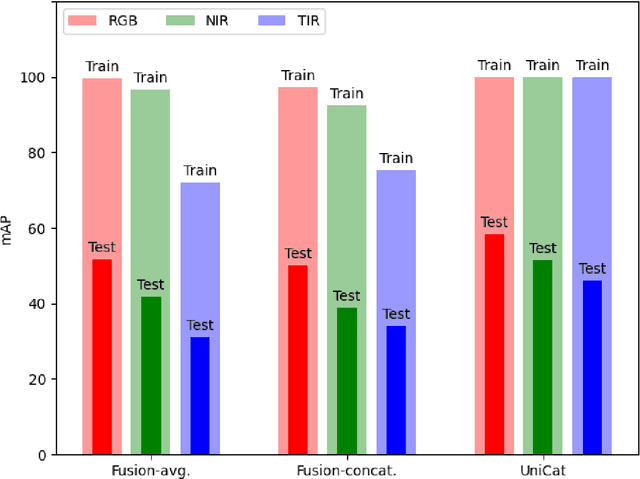
Multimodal Re-Identification (ReID) is a popular retrieval task that aims to re-identify objects across diverse data streams, prompting many researchers to integrate multiple modalities into a unified representation. While such fusion promises a holistic view, our investigations shed light on potential pitfalls. We uncover that prevailing late-fusion techniques often produce suboptimal latent representations when compared to methods that train modalities in isolation. We argue that this effect is largely due to the inadvertent relaxation of the training objectives on individual modalities when using fusion, what others have termed modality laziness. We present a nuanced point-of-view that this relaxation can lead to certain modalities failing to fully harness available task-relevant information, and yet, offers a protective veil to noisy modalities, preventing them from overfitting to task-irrelevant data. Our findings also show that unimodal concatenation (UniCat) and other late-fusion ensembling of unimodal backbones, when paired with best-known training techniques, exceed the current state-of-the-art performance across several multimodal ReID benchmarks. By unveiling the double-edged sword of "modality laziness", we motivate future research in balancing local modality strengths with global representations.
GraFT: Gradual Fusion Transformer for Multimodal Re-Identification
Oct 25, 2023



Object Re-Identification (ReID) is pivotal in computer vision, witnessing an escalating demand for adept multimodal representation learning. Current models, although promising, reveal scalability limitations with increasing modalities as they rely heavily on late fusion, which postpones the integration of specific modality insights. Addressing this, we introduce the \textbf{Gradual Fusion Transformer (GraFT)} for multimodal ReID. At its core, GraFT employs learnable fusion tokens that guide self-attention across encoders, adeptly capturing both modality-specific and object-specific features. Further bolstering its efficacy, we introduce a novel training paradigm combined with an augmented triplet loss, optimizing the ReID feature embedding space. We demonstrate these enhancements through extensive ablation studies and show that GraFT consistently surpasses established multimodal ReID benchmarks. Additionally, aiming for deployment versatility, we've integrated neural network pruning into GraFT, offering a balance between model size and performance.
Prostate Lesion Detection and Salient Feature Assessment Using Zone-Based Classifiers
Aug 24, 2022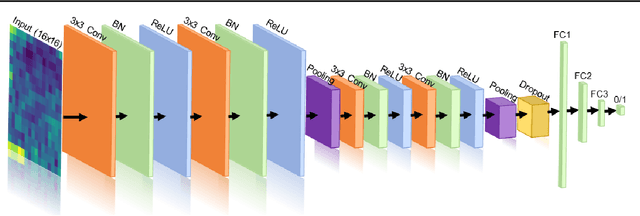
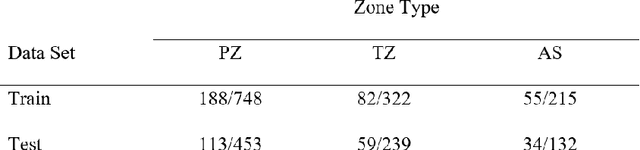

Multi-parametric magnetic resonance imaging (mpMRI) has a growing role in detecting prostate cancer lesions. Thus, it is pertinent that medical professionals who interpret these scans reduce the risk of human error by using computer-aided detection systems. The variety of algorithms used in system implementation, however, has yielded mixed results. Here we investigate the best machine learning classifier for each prostate zone. We also discover salient features to clarify the models' classification rationale. Of the data provided, we gathered and augmented T2 weighted images and apparent diffusion coefficient map images to extract first through third order statistical features as input to machine learning classifiers. For our deep learning classifier, we used a convolutional neural net (CNN) architecture for automatic feature extraction and classification. The interpretability of the CNN results was improved by saliency mapping to understand the classification mechanisms within. Ultimately, we concluded that effective detection of peripheral and anterior fibromuscular stroma (AS) lesions depended more on statistical distribution features, whereas those in the transition zone (TZ) depended more on textural features. Ensemble algorithms worked best for PZ and TZ zones, while CNNs were best in the AS zone. These classifiers can be used to validate a radiologist's predictions and reduce inter-reader variability in patients suspected to have prostate cancer. The salient features reported in this study can also be investigated further to better understand hidden features and biomarkers of prostate lesions with mpMRIs.