 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEALing with Image Reconstruction: Deep Attentive Least Squares
Feb 06, 2025



State-of-the-art image reconstruction often relies on complex, highly parameterized deep architectures. We propose an alternative: a data-driven reconstruction method inspired by the classic Tikhonov regularization. Our approach iteratively refines intermediate reconstructions by solving a sequence of quadratic problems. These updates have two key components: (i) learned filters to extract salient image features, and (ii) an attention mechanism that locally adjusts the penalty of filter responses. Our method achieves performance on par with leading plug-and-play and learned regularizer approaches while offering interpretability, robustness, and convergent behavior. In effect, we bridge traditional regularization and deep learning with a principled reconstruction approach.
Comparison of 2D Regular Lattices for the CPWL Approximation of Functions
Feb 05, 2025


We investigate the approximation error of functions with continuous and piecewise-linear (CPWL) representations. We focus on the CPWL search spaces generated by translates of box splines on two-dimensional regular lattices. We compute the approximation error in terms of the stepsize and angles that define the lattice. Our results show that hexagonal lattices are optimal, in the sense that they minimize the asymptotic approximation error.
Iteratively Refined Image Reconstruction with Learned Attentive Regularizers
Jul 09, 2024We propose a regularization scheme for image reconstruction that leverages the power of deep learning while hinging on classic sparsity-promoting models. Many deep-learning-based models are hard to interpret and cumbersome to analyze theoretically. In contrast, our scheme is interpretable because it corresponds to the minimization of a series of convex problems. For each problem in the series, a mask is generated based on the previous solution to refine the regularization strength spatially. In this way, the model becomes progressively attentive to the image structure. For the underlying update operator, we prove the existence of a fixed point. As a special case, we investigate a mask generator for which the fixed-point iterations converge to a critical point of an explicit energy functional. In our experiments, we match the performance of state-of-the-art learned variational models for the solution of inverse problems. Additionally, we offer a promising balance between interpretability, theoretical guarantees, reliability, and performance.
Random ReLU Neural Networks as Non-Gaussian Processes
May 16, 2024

We consider a large class of shallow neural networks with randomly initialized parameters and rectified linear unit activation functions. We prove that these random neural networks are well-defined non-Gaussian processes. As a by-product, we demonstrate that these networks are solutions to stochastic differential equations driven by impulsive white noise (combinations of random Dirac measures). These processes are parameterized by the law of the weights and biases as well as the density of activation thresholds in each bounded region of the input domain. We prove that these processes are isotropic and wide-sense self-similar with Hurst exponent $3/2$. We also derive a remarkably simple closed-form expression for their autocovariance function. Our results are fundamentally different from prior work in that we consider a non-asymptotic viewpoint: The number of neurons in each bounded region of the input domain (i.e., the width) is itself a random variable with a Poisson law with mean proportional to the density parameter. Finally, we show that, under suitable hypotheses, as the expected width tends to infinity, these processes can converge in law not only to Gaussian processes, but also to non-Gaussian processes depending on the law of the weights. Our asymptotic results provide a new take on several classical results (wide networks converge to Gaussian processes) as well as some new ones (wide networks can converge to non-Gaussian processes).
Delaunay-Triangulation-Based Learning with Hessian Total-Variation Regularization
Aug 16, 2022
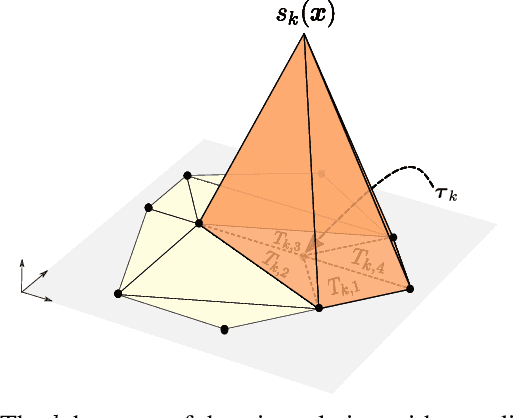
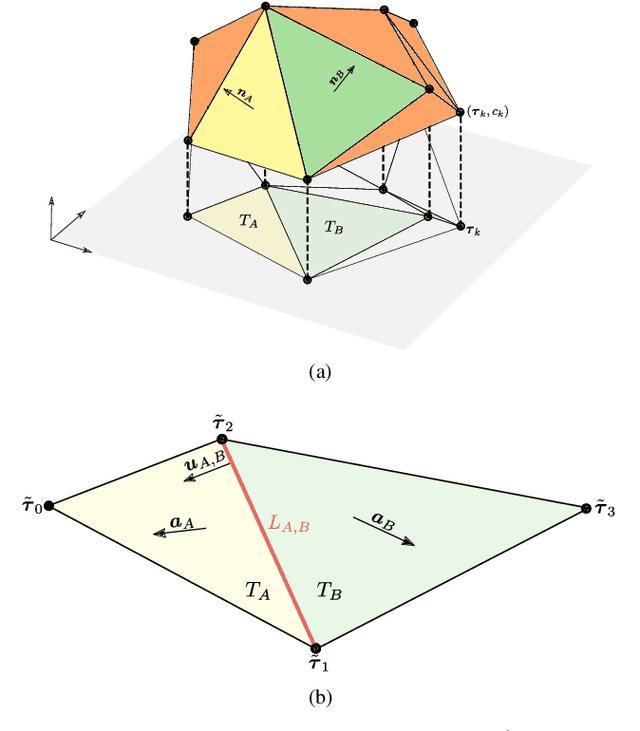

Regression is one of the core problems tackled in supervised learning. Rectified linear unit (ReLU) neural networks generate continuous and piecewise-linear (CPWL) mappings and are the state-of-the-art approach for solving regression problems. In this paper, we propose an alternative method that leverages the expressivity of CPWL functions. In contrast to deep neural networks, our CPWL parameterization guarantees stability and is interpretable. Our approach relies on the partitioning of the domain of the CPWL function by a Delaunay triangulation. The function values at the vertices of the triangulation are our learnable parameters and identify the CPWL function uniquely. Formulating the learning scheme as a variational problem, we use the Hessian total variation (HTV) as regularizer to favor CPWL functions with few affine pieces. In this way, we control the complexity of our model through a single hyperparameter. By developing a computational framework to compute the HTV of any CPWL function parameterized by a triangulation, we discretize the learning problem as the generalized least absolute shrinkage and selection operator (LASSO). Our experiments validate the usage of our method in low-dimensional scenarios.