 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplineSplat: 3D Ray Tracing for Higher-Quality Tomography
Nov 14, 2025We propose a method to efficiently compute tomographic projections of a 3D volume represented by a linear combination of shifted B-splines. To do so, we propose a ray-tracing algorithm that computes 3D line integrals with arbitrary projection geometries. One of the components of our algorithm is a neural network that computes the contribution of the basis functions efficiently. In our experiments, we consider well-posed cases where the data are sufficient for accurate reconstruction without the need for regularization. We achieve higher reconstruction quality than traditional voxel-based methods.
Undersampled Phase Retrieval with Image Priors
Sep 18, 2025Phase retrieval seeks to recover a complex signal from amplitude-only measurements, a challenging nonlinear inverse problem. Current theory and algorithms often ignore signal priors. By contrast, we evaluate here a variety of image priors in the context of severe undersampling with structured random Fourier measurements. Our results show that those priors significantly improve reconstruction, allowing accurate reconstruction even below the weak recovery threshold.
A Statistical Benchmark for Diffusion Posterior Sampling Algorithms
Sep 16, 2025We propose a statistical benchmark for diffusion posterior sampling (DPS) algorithms for Bayesian linear inverse problems. The benchmark synthesizes signals from sparse L\'evy-process priors whose posteriors admit efficient Gibbs methods. These Gibbs methods can be used to obtain gold-standard posterior samples that can be compared to the samples obtained by the DPS algorithms. By using the Gibbs methods for the resolution of the denoising problems in the reverse diffusion, the framework also isolates the error that arises from the approximations to the likelihood score. We instantiate the benchmark with the minimum-mean-squared-error optimality gap and posterior coverage tests and provide numerical experiments for popular DPS algorithms on the inverse problems of denoising, deconvolution, imputation, and reconstruction from partial Fourier measurements. We release the benchmark code at https://github.com/zacmar/dps-benchmark. The repository exposes simple plug-in interfaces, reference scripts, and config-driven runs so that new algorithms can be added and evaluated with minimal effort. We invite researchers to contribute and report results.
Multivariate Fields of Experts
Aug 08, 2025We introduce the multivariate fields of experts, a new framework for the learning of image priors. Our model generalizes existing fields of experts methods by incorporating multivariate potential functions constructed via Moreau envelopes of the $\ell_\infty$-norm. We demonstrate the effectiveness of our proposal across a range of inverse problems that include image denoising, deblurring, compressed-sensing magnetic-resonance imaging, and computed tomography. The proposed approach outperforms comparable univariate models and achieves performance close to that of deep-learning-based regularizers while being significantly faster, requiring fewer parameters, and being trained on substantially fewer data. In addition, our model retains a relatively high level of interpretability due to its structured design.
The Gaussian Latent Machine: Efficient Prior and Posterior Sampling for Inverse Problems
May 19, 2025We consider the problem of sampling from a product-of-experts-type model that encompasses many standard prior and posterior distributions commonly found in Bayesian imaging. We show that this model can be easily lifted into a novel latent variable model, which we refer to as a Gaussian latent machine. This leads to a general sampling approach that unifies and generalizes many existing sampling algorithms in the literature. Most notably, it yields a highly efficient and effective two-block Gibbs sampling approach in the general case, while also specializing to direct sampling algorithms in particular cases. Finally, we present detailed numerical experiments that demonstrate the efficiency and effectiveness of our proposed sampling approach across a wide range of prior and posterior sampling problems from Bayesian imaging.
Generalized Ray Tracing with Basis functions for Tomographic Projections
Mar 26, 2025This work aims at the precise and efficient computation of the x-ray projection of an image represented by a linear combination of general shifted basis functions that typically overlap. We achieve this with a suitable adaptation of ray tracing, which is one of the most efficient methods to compute line integrals. In our work, the cases in which the image is expressed as a spline are of particular relevance. The proposed implementation is applicable to any projection geometry as it computes the forward and backward operators over a collection of arbitrary lines. We validate our work with experiments in the context of inverse problems for image reconstruction and maximize the image quality for a given resolution of the reconstruction grid.
Universal Architectures for the Learning of Polyhedral Norms and Convex Regularization Functionals
Mar 24, 2025



This paper addresses the task of learning convex regularizers to guide the reconstruction of images from limited data. By imposing that the reconstruction be amplitude-equivariant, we narrow down the class of admissible functionals to those that can be expressed as a power of a seminorm. We then show that such functionals can be approximated to arbitrary precision with the help of polyhedral norms. In particular, we identify two dual parameterizations of such systems: (i) a synthesis form with an $\ell_1$-penalty that involves some learnable dictionary; and (ii) an analysis form with an $\ell_\infty$-penalty that involves a trainable regularization operator. After having provided geometric insights and proved that the two forms are universal, we propose an implementation that relies on a specific architecture (tight frame with a weighted $\ell_1$ penalty) that is easy to train. We illustrate its use for denoising and the reconstruction of biomedical images. We find that the proposed framework outperforms the sparsity-based methods of compressed sensing, while it offers essentially the same convergence and robustness guarantees.
DEALing with Image Reconstruction: Deep Attentive Least Squares
Feb 06, 2025



State-of-the-art image reconstruction often relies on complex, highly parameterized deep architectures. We propose an alternative: a data-driven reconstruction method inspired by the classic Tikhonov regularization. Our approach iteratively refines intermediate reconstructions by solving a sequence of quadratic problems. These updates have two key components: (i) learned filters to extract salient image features, and (ii) an attention mechanism that locally adjusts the penalty of filter responses. Our method achieves performance on par with leading plug-and-play and learned regularizer approaches while offering interpretability, robustness, and convergent behavior. In effect, we bridge traditional regularization and deep learning with a principled reconstruction approach.
Comparison of 2D Regular Lattices for the CPWL Approximation of Functions
Feb 05, 2025


We investigate the approximation error of functions with continuous and piecewise-linear (CPWL) representations. We focus on the CPWL search spaces generated by translates of box splines on two-dimensional regular lattices. We compute the approximation error in terms of the stepsize and angles that define the lattice. Our results show that hexagonal lattices are optimal, in the sense that they minimize the asymptotic approximation error.
Learning of Patch-Based Smooth-Plus-Sparse Models for Image Reconstruction
Dec 17, 2024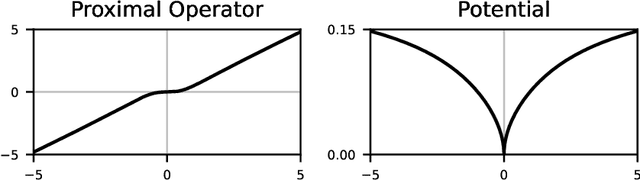
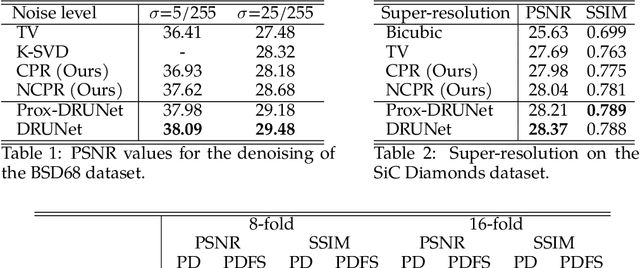

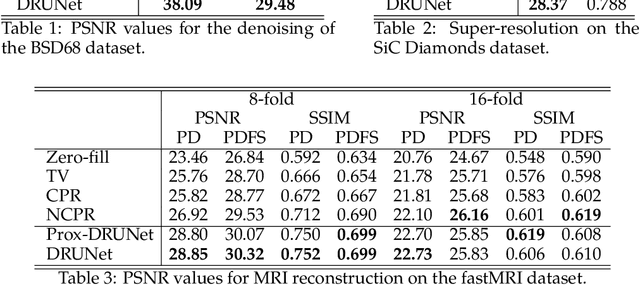
We aim at the solution of inverse problems in imaging, by combining a penalized sparse representation of image patches with an unconstrained smooth one. This allows for a straightforward interpretation of the reconstruction. We formulate the optimization as a bilevel problem. The inner problem deploys classical algorithms while the outer problem optimizes the dictionary and the regularizer parameters through supervised learning. The process is carried out via implicit differentiation and gradient-based optimization. We evaluate our method for denoising, super-resolution, and compressed-sensing magnetic-resonance imaging. We compare it to other classical models as well as deep-learning-based methods and show that it always outperforms the former and also the latter in some instances.