 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Multi-Task Learning on ReLU Neural Network Functions
Oct 29, 2024This paper studies the properties of solutions to multi-task shallow ReLU neural network learning problems, wherein the network is trained to fit a dataset with minimal sum of squared weights. Remarkably, the solutions learned for each individual task resemble those obtained by solving a kernel method, revealing a novel connection between neural networks and kernel methods. It is known that single-task neural network training problems are equivalent to minimum norm interpolation problem in a non-Hilbertian Banach space, and that the solutions of such problems are generally non-unique. In contrast, we prove that the solutions to univariate-input, multi-task neural network interpolation problems are almost always unique, and coincide with the solution to a minimum-norm interpolation problem in a Sobolev (Reproducing Kernel) Hilbert Space. We also demonstrate a similar phenomenon in the multivariate-input case; specifically, we show that neural network learning problems with large numbers of diverse tasks are approximately equivalent to an $\ell^2$ (Hilbert space) minimization problem over a fixed kernel determined by the optimal neurons.
ReLUs Are Sufficient for Learning Implicit Neural Representations
Jun 04, 2024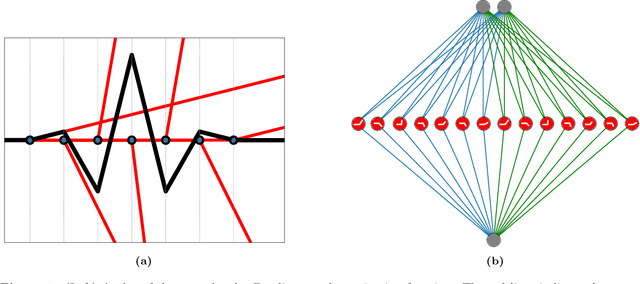
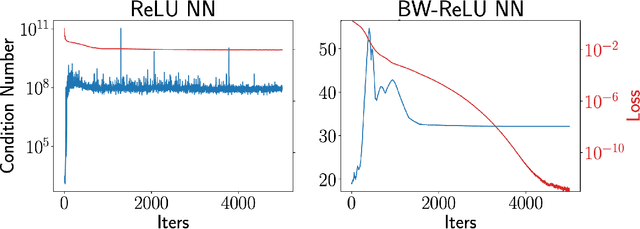
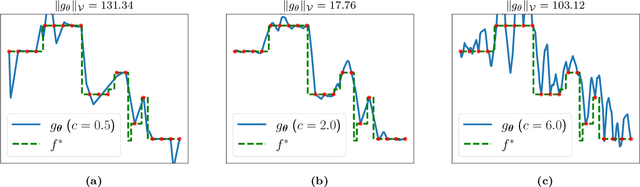
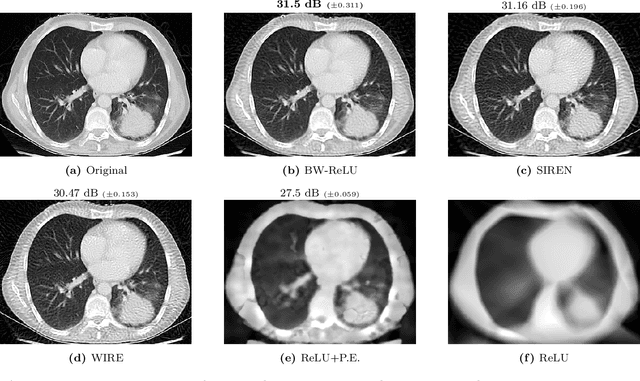
Motivated by the growing theoretical understanding of neural networks that employ the Rectified Linear Unit (ReLU) as their activation function, we revisit the use of ReLU activation functions for learning implicit neural representations (INRs). Inspired by second order B-spline wavelets, we incorporate a set of simple constraints to the ReLU neurons in each layer of a deep neural network (DNN) to remedy the spectral bias. This in turn enables its use for various INR tasks. Empirically, we demonstrate that, contrary to popular belief, one can learn state-of-the-art INRs based on a DNN composed of only ReLU neurons. Next, by leveraging recent theoretical works which characterize the kinds of functions ReLU neural networks learn, we provide a way to quantify the regularity of the learned function. This offers a principled approach to selecting the hyperparameters in INR architectures. We substantiate our claims through experiments in signal representation, super resolution, and computed tomography, demonstrating the versatility and effectiveness of our method. The code for all experiments can be found at https://github.com/joeshenouda/relu-inrs.
Vector-Valued Variation Spaces and Width Bounds for DNNs: Insights on Weight Decay Regularization
May 25, 2023Deep neural networks (DNNs) trained to minimize a loss term plus the sum of squared weights via gradient descent corresponds to the common approach of training with weight decay. This paper provides new insights into this common learning framework. We characterize the kinds of functions learned by training with weight decay for multi-output (vector-valued) ReLU neural networks. This extends previous characterizations that were limited to single-output (scalar-valued) networks. This characterization requires the definition of a new class of neural function spaces that we call vector-valued variation (VV) spaces. We prove that neural networks (NNs) are optimal solutions to learning problems posed over VV spaces via a novel representer theorem. This new representer theorem shows that solutions to these learning problems exist as vector-valued neural networks with widths bounded in terms of the number of training data. Next, via a novel connection to the multi-task lasso problem, we derive new and tighter bounds on the widths of homogeneous layers in DNNs. The bounds are determined by the effective dimensions of the training data embeddings in/out of the layers. This result sheds new light on the architectural requirements for DNNs. Finally, the connection to the multi-task lasso problem suggests a new approach to compressing pre-trained networks.
A Better Way to Decay: Proximal Gradient Training Algorithms for Neural Nets
Oct 06, 2022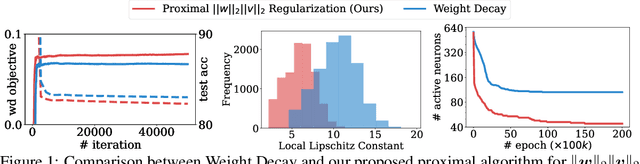
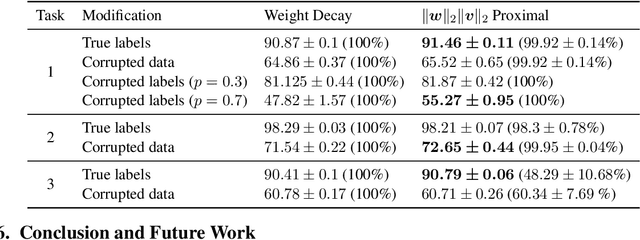

Weight decay is one of the most widely used forms of regularization in deep learning, and has been shown to improve generalization and robustness. The optimization objective driving weight decay is a sum of losses plus a term proportional to the sum of squared weights. This paper argues that stochastic gradient descent (SGD) may be an inefficient algorithm for this objective. For neural networks with ReLU activations, solutions to the weight decay objective are equivalent to those of a different objective in which the regularization term is instead a sum of products of $\ell_2$ (not squared) norms of the input and output weights associated each ReLU. This alternative (and effectively equivalent) regularization suggests a novel proximal gradient algorithm for network training. Theory and experiments support the new training approach, showing that it can converge much faster to the sparse solutions it shares with standard weight decay training.
A Guide to Reproducible Research in Signal Processing and Machine Learning
Aug 27, 2021

Reproducibility is a growing problem that has been extensively studied among computational researchers and within the signal processing and machine learning research community. However, with the changing landscape of signal processing and machine learning research come new obstacles and unseen challenges in creating reproducible experiments. Due to these new challenges most experiments have become difficult, if not impossible, to be reproduced by an independent researcher. In 2016 a survey conducted by the journal Nature found that 50% of researchers were unable to reproduce their own experiments. While the issue of reproducibility has been discussed in the literature and specifically within the signal processing community, it is still unclear to most researchers what are the best practices to ensure reproducibility without impinging on their primary responsibility of conducting research. We feel that although researchers understand the importance of making experiments reproducible, the lack of a clear set of standards and tools makes it difficult to incorporate good reproducibility practices in most labs. It is in this regard that we aim to present signal processing researchers with a set of practical tools and strategies that can help mitigate many of the obstacles to producing reproducible computational experiments.