 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLUs Are Sufficient for Learning Implicit Neural Representations
Jun 04, 2024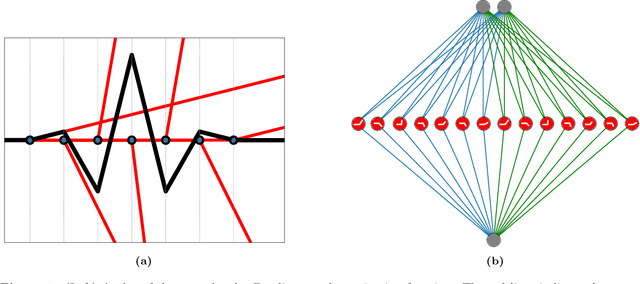
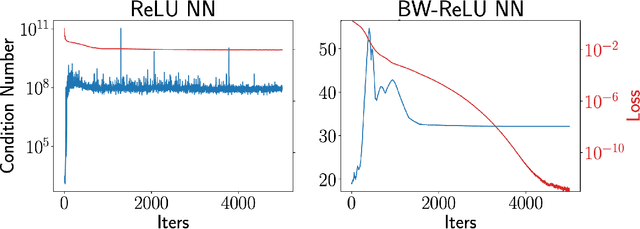
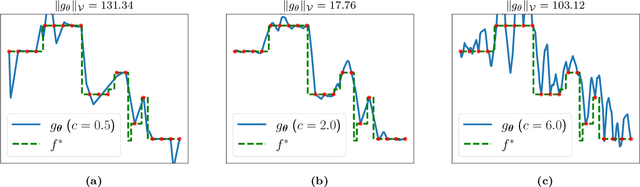
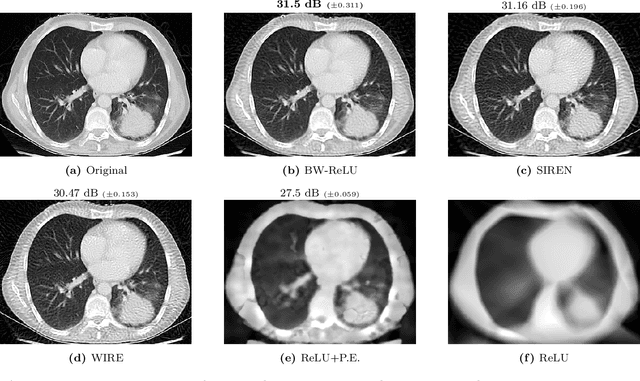
Motivated by the growing theoretical understanding of neural networks that employ the Rectified Linear Unit (ReLU) as their activation function, we revisit the use of ReLU activation functions for learning implicit neural representations (INRs). Inspired by second order B-spline wavelets, we incorporate a set of simple constraints to the ReLU neurons in each layer of a deep neural network (DNN) to remedy the spectral bias. This in turn enables its use for various INR tasks. Empirically, we demonstrate that, contrary to popular belief, one can learn state-of-the-art INRs based on a DNN composed of only ReLU neurons. Next, by leveraging recent theoretical works which characterize the kinds of functions ReLU neural networks learn, we provide a way to quantify the regularity of the learned function. This offers a principled approach to selecting the hyperparameters in INR architectures. We substantiate our claims through experiments in signal representation, super resolution, and computed tomography, demonstrating the versatility and effectiveness of our method. The code for all experiments can be found at https://github.com/joeshenouda/relu-inrs.