 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Architectural Complexity of Neural Networks
May 05, 2026We introduce a unified theoretical framework for the rigorous analysis and systematic construction of deep neural networks (DNNs). This framework addresses a gap in existing theory by explicitly modeling the structure of tensor operations -- lower level information that is often abstracted. Our framework enables two novel objectives: (1) analysis of the evolution of architectural complexity over deep learning history, and (2) automatic construction of novel architectures based on new types of tensor operations. Our study of DNNs introduced over the past 40 years reveals a connection between groundbreaking architectures and increases in different types of architectural complexity. Moreover, we identify several large classes of higher complexity architectures that have not yet been explored. We then collect a dataset of 3,000+ higher complexity architectures, which we publicly release at: https://github.com/combinatoriallabs/ArchitecturalComplexity.
Flickering Multi-Armed Bandits
Feb 19, 2026We introduce Flickering Multi-Armed Bandits (FMAB), a new MAB framework where the set of available arms (or actions) can change at each round, and the available set at any time may depend on the agent's previously selected arm. We model this constrained, evolving availability using random graph processes, where arms are nodes and the agent's movement is restricted to its local neighborhood. We analyze this problem under two random graph models: an i.i.d. Erdős--Rényi (ER) process and an Edge-Markovian process. We propose and analyze a two-phase algorithm that employs a lazy random walk for exploration to efficiently identify the optimal arm, followed by a navigation and commitment phase for exploitation. We establish high-probability and expected sublinear regret bounds for both graph settings. We show that the exploration cost of our algorithm is near-optimal by establishing a matching information-theoretic lower bound for this problem class, highlighting the fundamental cost of exploration under local-move constraints. We complement our theoretical guarantees with numerical simulations, including a scenario of a robotic ground vehicle scouting a disaster-affected region.
A Unified Framework for Locality in Scalable MARL
Feb 19, 2026Scalable Multi-Agent Reinforcement Learning (MARL) is fundamentally challenged by the curse of dimensionality. A common solution is to exploit locality, which hinges on an Exponential Decay Property (EDP) of the value function. However, existing conditions that guarantee the EDP are often conservative, as they are based on worst-case, environment-only bounds (e.g., supremums over actions) and fail to capture the regularizing effect of the policy itself. In this work, we establish that locality can also be a \emph{policy-dependent} phenomenon. Our central contribution is a novel decomposition of the policy-induced interdependence matrix, $H^π$, which decouples the environment's sensitivity to state ($E^{\mathrm{s}}$) and action ($E^{\mathrm{a}}$) from the policy's sensitivity to state ($Π(π)$). This decomposition reveals that locality can be induced by a smooth policy (small $Π(π)$) even when the environment is strongly action-coupled, exposing a fundamental locality-optimality tradeoff. We use this framework to derive a general spectral condition $ρ(E^{\mathrm{s}}+E^{\mathrm{a}}Π(π)) < 1$ for exponential decay, which is strictly tighter than prior norm-based conditions. Finally, we leverage this theory to analyze a provably-sound localized block-coordinate policy improvement framework with guarantees tied directly to this spectral radius.
Multi-Agent Lipschitz Bandits
Feb 18, 2026We study the decentralized multi-player stochastic bandit problem over a continuous, Lipschitz-structured action space where hard collisions yield zero reward. Our objective is to design a communication-free policy that maximizes collective reward, with coordination costs that are independent of the time horizon $T$. We propose a modular protocol that first solves the multi-agent coordination problem -- identifying and seating players on distinct high-value regions via a novel maxima-directed search -- and then decouples the problem into $N$ independent single-player Lipschitz bandits. We establish a near-optimal regret bound of $\tilde{O}(T^{(d+1)/(d+2)})$ plus a $T$-independent coordination cost, matching the single-player rate. To our knowledge, this is the first framework providing such guarantees, and it extends to general distance-threshold collision models.
Logit-Based Losses Limit the Effectiveness of Feature Knowledge Distillation
Nov 18, 2025Knowledge distillation (KD) methods can transfer knowledge of a parameter-heavy teacher model to a light-weight student model. The status quo for feature KD methods is to utilize loss functions based on logits (i.e., pre-softmax class scores) and intermediate layer features (i.e., latent representations). Unlike previous approaches, we propose a feature KD framework for training the student's backbone using feature-based losses exclusively (i.e., without logit-based losses such as cross entropy). Leveraging recent discoveries about the geometry of latent representations, we introduce a knowledge quality metric for identifying which teacher layers provide the most effective knowledge for distillation. Experiments on three image classification datasets with four diverse student-teacher pairs, spanning convolutional neural networks and vision transformers, demonstrate our KD method achieves state-of-the-art performance, delivering top-1 accuracy boosts of up to 15% over standard approaches. We publically share our code to facilitate future work at https://github.com/Thegolfingocto/KD_wo_CE.
Incentivized Lipschitz Bandits
Aug 26, 2025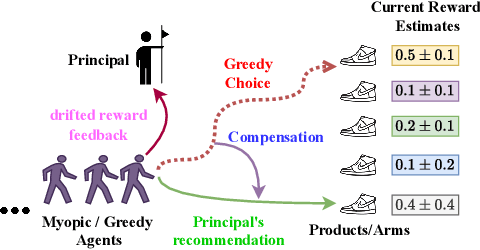
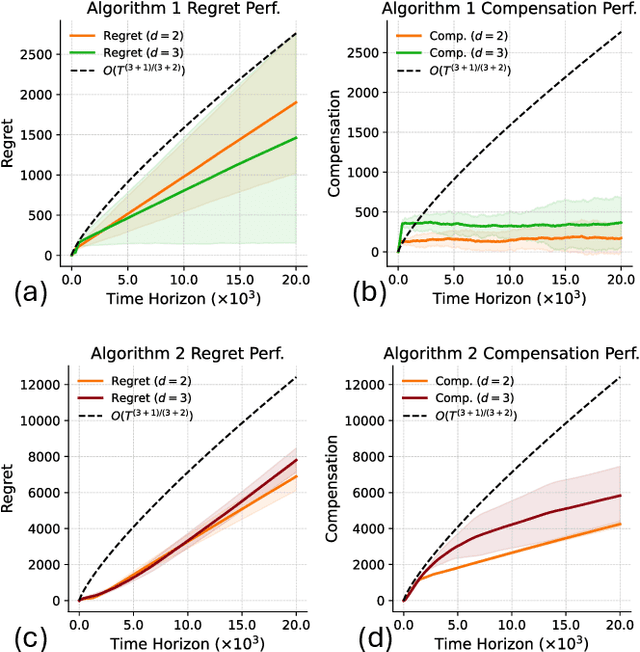
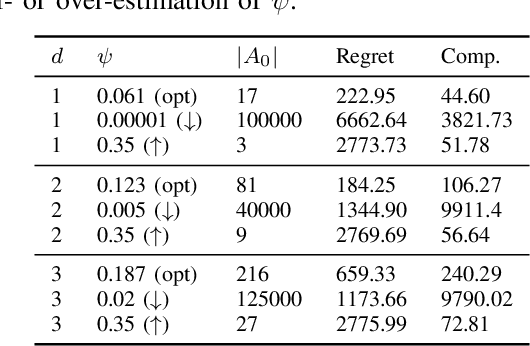
We study incentivized exploration in multi-armed bandit (MAB) settings with infinitely many arms modeled as elements in continuous metric spaces. Unlike classical bandit models, we consider scenarios where the decision-maker (principal) incentivizes myopic agents to explore beyond their greedy choices through compensation, but with the complication of reward drift--biased feedback arising due to the incentives. We propose novel incentivized exploration algorithms that discretize the infinite arm space uniformly and demonstrate that these algorithms simultaneously achieve sublinear cumulative regret and sublinear total compensation. Specifically, we derive regret and compensation bounds of $\Tilde{O}(T^{d+1/d+2})$, with $d$ representing the covering dimension of the metric space. Furthermore, we generalize our results to contextual bandits, achieving comparable performance guarantees. We validate our theoretical findings through numerical simulations.
GaRe: Relightable 3D Gaussian Splatting for Outdoor Scenes from Unconstrained Photo Collections
Jul 28, 2025



We propose a 3D Gaussian splatting-based framework for outdoor relighting that leverages intrinsic image decomposition to precisely integrate sunlight, sky radiance, and indirect lighting from unconstrained photo collections. Unlike prior methods that compress the per-image global illumination into a single latent vector, our approach enables simultaneously diverse shading manipulation and the generation of dynamic shadow effects. This is achieved through three key innovations: (1) a residual-based sun visibility extraction method to accurately separate direct sunlight effects, (2) a region-based supervision framework with a structural consistency loss for physically interpretable and coherent illumination decomposition, and (3) a ray-tracing-based technique for realistic shadow simulation. Extensive experiments demonstrate that our framework synthesizes novel views with competitive fidelity against state-of-the-art relighting solutions and produces more natural and multifaceted illumination and shadow effects.
Incentivized Exploration of Non-Stationary Stochastic Bandits
Mar 16, 2024



We study incentivized exploration for the multi-armed bandit (MAB) problem with non-stationary reward distributions, where players receive compensation for exploring arms other than the greedy choice and may provide biased feedback on the reward. We consider two different non-stationary environments: abruptly-changing and continuously-changing, and propose respective incentivized exploration algorithms. We show that the proposed algorithms achieve sublinear regret and compensation over time, thus effectively incentivizing exploration despite the nonstationarity and the biased or drifted feedback.
NeuV-SLAM: Fast Neural Multiresolution Voxel Optimization for RGBD Dense SLAM
Feb 03, 2024We introduce NeuV-SLAM, a novel dense simultaneous localization and mapping pipeline based on neural multiresolution voxels, characterized by ultra-fast convergence and incremental expansion capabilities. This pipeline utilizes RGBD images as input to construct multiresolution neural voxels, achieving rapid convergence while maintaining robust incremental scene reconstruction and camera tracking. Central to our methodology is to propose a novel implicit representation, termed VDF that combines the implementation of neural signed distance field (SDF) voxels with an SDF activation strategy. This approach entails the direct optimization of color features and SDF values anchored within the voxels, substantially enhancing the rate of scene convergence. To ensure the acquisition of clear edge delineation, SDF activation is designed, which maintains exemplary scene representation fidelity even under constraints of voxel resolution. Furthermore, in pursuit of advancing rapid incremental expansion with low computational overhead, we developed hashMV, a novel hash-based multiresolution voxel management structure. This architecture is complemented by a strategically designed voxel generation technique that synergizes with a two-dimensional scene prior. Our empirical evaluations, conducted on the Replica and ScanNet Datasets, substantiate NeuV-SLAM's exceptional efficacy in terms of convergence speed, tracking accuracy, scene reconstruction, and rendering quality.
Unsupervised Deep Cross-Language Entity Alignment
Sep 19, 2023Cross-lingual entity alignment is the task of finding the same semantic entities from different language knowledge graphs. In this paper, we propose a simple and novel unsupervised method for cross-language entity alignment. We utilize the deep learning multi-language encoder combined with a machine translator to encode knowledge graph text, which reduces the reliance on label data. Unlike traditional methods that only emphasize global or local alignment, our method simultaneously considers both alignment strategies. We first view the alignment task as a bipartite matching problem and then adopt the re-exchanging idea to accomplish alignment. Compared with the traditional bipartite matching algorithm that only gives one optimal solution, our algorithm generates ranked matching results which enabled many potentials downstream tasks. Additionally, our method can adapt two different types of optimization (minimal and maximal) in the bipartite matching process, which provides more flexibility. Our evaluation shows, we each scored 0.966, 0.990, and 0.996 Hits@1 rates on the DBP15K dataset in Chinese, Japanese, and French to English alignment tasks. We outperformed the state-of-the-art method in unsupervised and semi-supervised categories. Compared with the state-of-the-art supervised method, our method outperforms 2.6% and 0.4% in Ja-En and Fr-En alignment tasks while marginally lower by 0.2% in the Zh-En alignment task.