 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTSAC: Curriculum-Based Transformer Soft Actor-Critic for Goal-Oriented Robot Exploration
Mar 18, 2025
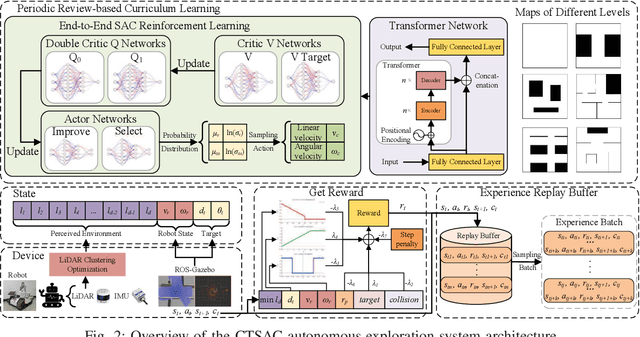


With the increasing demand for efficient and flexible robotic exploration solutions, Reinforcement Learning (RL) is becoming a promising approach in the field of autonomous robotic exploration. However, current RL-based exploration algorithms often face limited environmental reasoning capabilities, slow convergence rates, and substantial challenges in Sim-To-Real (S2R) transfer. To address these issues, we propose a Curriculum Learning-based Transformer Reinforcement Learning Algorithm (CTSAC) aimed at improving both exploration efficiency and transfer performance. To enhance the robot's reasoning ability, a Transformer is integrated into the perception network of the Soft Actor-Critic (SAC) framework, leveraging historical information to improve the farsightedness of the strategy. A periodic review-based curriculum learning is proposed, which enhances training efficiency while mitigating catastrophic forgetting during curriculum transitions. Training is conducted on the ROS-Gazebo continuous robotic simulation platform, with LiDAR clustering optimization to further reduce the S2R gap. Experimental results demonstrate the CTSAC algorithm outperforms the state-of-the-art non-learning and learning-based algorithms in terms of success rate and success rate-weighted exploration time. Moreover, real-world experiments validate the strong S2R transfer capabilities of CTSAC.
Learning Optical Flow and Scene Flow with Bidirectional Camera-LiDAR Fusion
Mar 21, 2023In this paper, we study the problem of jointly estimating the optical flow and scene flow from synchronized 2D and 3D data. Previous methods either employ a complex pipeline that splits the joint task into independent stages, or fuse 2D and 3D information in an ``early-fusion'' or ``late-fusion'' manner. Such one-size-fits-all approaches suffer from a dilemma of failing to fully utilize the characteristic of each modality or to maximize the inter-modality complementarity. To address the problem, we propose a novel end-to-end framework, which consists of 2D and 3D branches with multiple bidirectional fusion connections between them in specific layers. Different from previous work, we apply a point-based 3D branch to extract the LiDAR features, as it preserves the geometric structure of point clouds. To fuse dense image features and sparse point features, we propose a learnable operator named bidirectional camera-LiDAR fusion module (Bi-CLFM). We instantiate two types of the bidirectional fusion pipeline, one based on the pyramidal coarse-to-fine architecture (dubbed CamLiPWC), and the other one based on the recurrent all-pairs field transforms (dubbed CamLiRAFT). On FlyingThings3D, both CamLiPWC and CamLiRAFT surpass all existing methods and achieve up to a 47.9\% reduction in 3D end-point-error from the best published result. Our best-performing model, CamLiRAFT, achieves an error of 4.26\% on the KITTI Scene Flow benchmark, ranking 1st among all submissions with much fewer parameters. Besides, our methods have strong generalization performance and the ability to handle non-rigid motion. Code is available at https://github.com/MCG-NJU/CamLiFlow.
CamLiFlow: Bidirectional Camera-LiDAR Fusion for Joint Optical Flow and Scene Flow Estimation
Nov 20, 2021


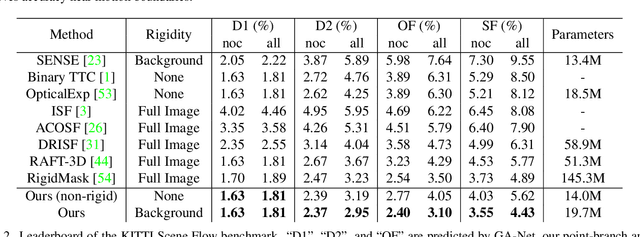
In this paper, we study the problem of jointly estimating the optical flow and scene flow from synchronized 2D and 3D data. Previous methods either employ a complex pipeline which splits the joint task into independent stages, or fuse 2D and 3D information in an ``early-fusion'' or ``late-fusion'' manner. Such one-size-fits-all approaches suffer from a dilemma of failing to fully utilize the characteristic of each modality or to maximize the inter-modality complementarity. To address the problem, we propose a novel end-to-end framework, called CamLiFlow. It consists of 2D and 3D branches with multiple bidirectional connections between them in specific layers. Different from previous work, we apply a point-based 3D branch to better extract the geometric features and design a symmetric learnable operator to fuse dense image features and sparse point features. We also propose a transformation for point clouds to solve the non-linear issue of 3D-2D projection. Experiments show that CamLiFlow achieves better performance with fewer parameters. Our method ranks 1st on the KITTI Scene Flow benchmark, outperforming the previous art with 1/7 parameters. Code will be made available.