Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivized Exploration for Multi-Armed Bandits under Reward Drift
Paper and Code
Dec 16, 2019


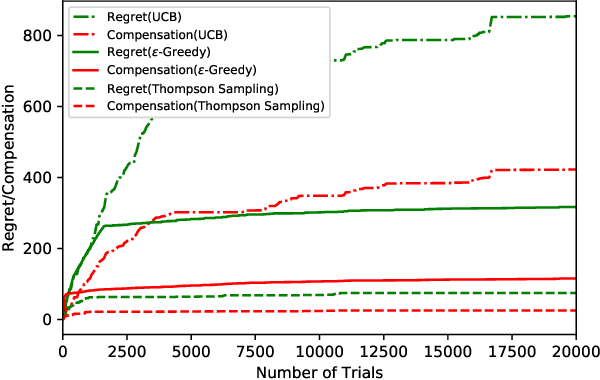
We study incentivized exploration for the multi-armed bandit (MAB) problem where the players receive compensation for exploring arms other than the greedy choice and may provide biased feedback on reward. We seek to understand the impact of this drifted reward feedback by analyzing the performance of three instantiations of the incentivized MAB algorithm: UCB, $\varepsilon$-Greedy, and Thompson Sampling. Our results show that they all achieve $\mathcal{O}(\log T)$ regret and compensation under the drifted reward, and are therefore effective in incentivizing exploration. Numerical examples are provided to complement the theoretical analysis.
* 10 pages, 2 figures, AAAI 2020
View paper on