 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive-Evo: Online Evolution of Agentic Memory from Continuous Feedback
Feb 02, 2026Large language model (LLM) agents are increasingly equipped with memory, which are stored experience and reusable guidance that can improve task-solving performance. Recent \emph{self-evolving} systems update memory based on interaction outcomes, but most existing evolution pipelines are developed for static train/test splits and only approximate online learning by folding static benchmarks, making them brittle under true distribution shift and continuous feedback. We introduce \textsc{Live-Evo}, an online self-evolving memory system that learns from a stream of incoming data over time. \textsc{Live-Evo} decouples \emph{what happened} from \emph{how to use it} via an Experience Bank and a Meta-Guideline Bank, compiling task-adaptive guidelines from retrieved experiences for each task. To manage memory online, \textsc{Live-Evo} maintains experience weights and updates them from feedback: experiences that consistently help are reinforced and retrieved more often, while misleading or stale experiences are down-weighted and gradually forgotten, analogous to reinforcement and decay in human memory. On the live \textit{Prophet Arena} benchmark over a 10-week horizon, \textsc{Live-Evo} improves Brier score by 20.8\% and increases market returns by 12.9\%, while also transferring to deep-research benchmarks with consistent gains over strong baselines. Our code is available at https://github.com/ag2ai/Live-Evo.
Sliding Window Attention Adaptation
Dec 16, 2025The self-attention mechanism in Transformer-based Large Language Models (LLMs) scales quadratically with input length, making long-context inference expensive. Sliding window attention (SWA) reduces this cost to linear complexity, but naively enabling complete SWA at inference-time for models pretrained with full attention (FA) causes severe long-context performance degradation due to training-inference mismatch. This makes us wonder: Can FA-pretrained LLMs be well adapted to SWA without pretraining? We investigate this by proposing Sliding Window Attention Adaptation (SWAA), a set of practical recipes that combine five methods for better adaptation: (1) applying SWA only during prefilling; (2) preserving "sink" tokens; (3) interleaving FA/SWA layers; (4) chain-of-thought (CoT); and (5) fine-tuning. Our experiments show that SWA adaptation is feasible while non-trivial: no single method suffices, yet specific synergistic combinations effectively recover the original long-context performance. We further analyze the performance-efficiency trade-offs of different SWAA configurations and provide recommended recipes for diverse scenarios, which can greatly and fundamentally accelerate LLM long-context inference speed by up to 100%. Our code is available at https://github.com/yuyijiong/sliding-window-attention-adaptation
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025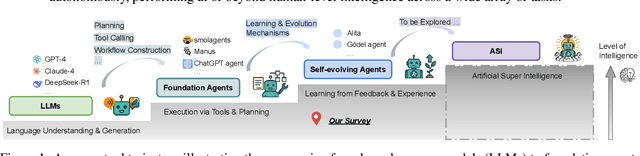

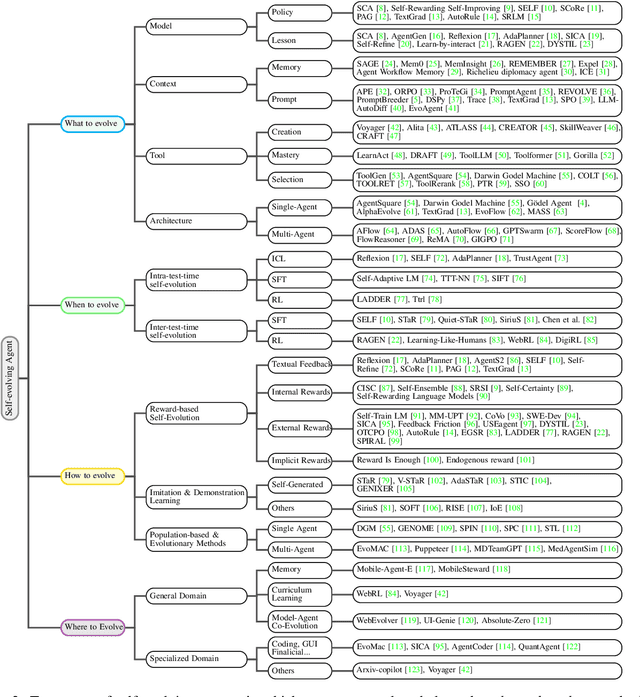
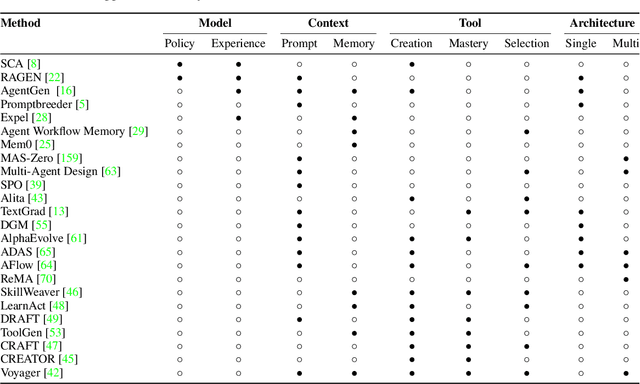
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
Provably Efficient Algorithm for Best Scoring Rule Identification in Online Principal-Agent Information Acquisition
May 23, 2025We investigate the problem of identifying the optimal scoring rule within the principal-agent framework for online information acquisition problem. We focus on the principal's perspective, seeking to determine the desired scoring rule through interactions with the agent. To address this challenge, we propose two algorithms: OIAFC and OIAFB, tailored for fixed confidence and fixed budget settings, respectively. Our theoretical analysis demonstrates that OIAFC can extract the desired $(\epsilon, \delta)$-scoring rule with a efficient instance-dependent sample complexity or an instance-independent sample complexity. Our analysis also shows that OIAFB matches the instance-independent performance bound of OIAFC, while both algorithms share the same complexity across fixed confidence and fixed budget settings.
Divide, Optimize, Merge: Fine-Grained LLM Agent Optimization at Scale
May 06, 2025LLM-based optimization has shown remarkable potential in enhancing agentic systems. However, the conventional approach of prompting LLM optimizer with the whole training trajectories on training dataset in a single pass becomes untenable as datasets grow, leading to context window overflow and degraded pattern recognition. To address these challenges, we propose Fine-Grained Optimization (FGO), a scalable framework that divides large optimization tasks into manageable subsets, performs targeted optimizations, and systematically combines optimized components through progressive merging. Evaluation across ALFWorld, LogisticsQA, and GAIA benchmarks demonstrate that FGO outperforms existing approaches by 1.6-8.6% while reducing average prompt token consumption by 56.3%. Our framework provides a practical solution for scaling up LLM-based optimization of increasingly sophisticated agent systems. Further analysis demonstrates that FGO achieves the most consistent performance gain in all training dataset sizes, showcasing its scalability and efficiency.
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
Apr 30, 2025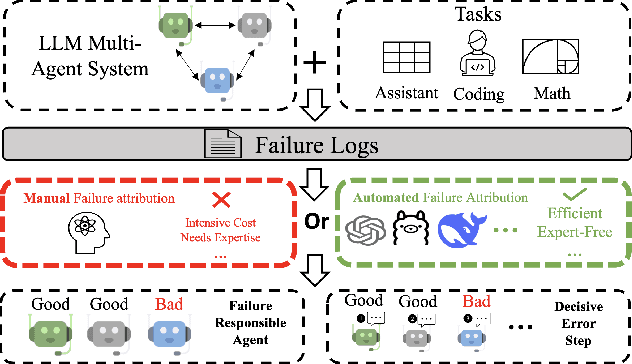
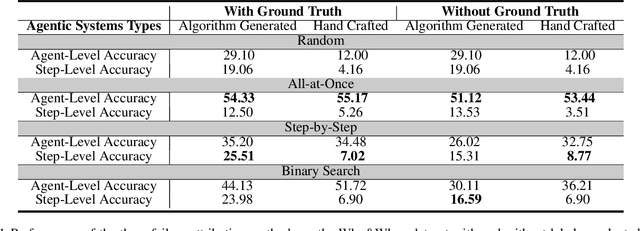
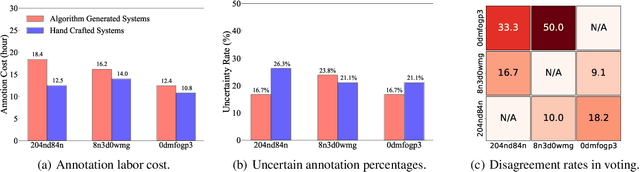

Failure attribution in LLM multi-agent systems-identifying the agent and step responsible for task failures-provides crucial clues for systems debugging but remains underexplored and labor-intensive. In this paper, we propose and formulate a new research area: automated failure attribution for LLM multi-agent systems. To support this initiative, we introduce the Who&When dataset, comprising extensive failure logs from 127 LLM multi-agent systems with fine-grained annotations linking failures to specific agents and decisive error steps. Using the Who&When, we develop and evaluate three automated failure attribution methods, summarizing their corresponding pros and cons. The best method achieves 53.5% accuracy in identifying failure-responsible agents but only 14.2% in pinpointing failure steps, with some methods performing below random. Even SOTA reasoning models, such as OpenAI o1 and DeepSeek R1, fail to achieve practical usability. These results highlight the task's complexity and the need for further research in this area. Code and dataset are available at https://github.com/mingyin1/Agents_Failure_Attribution
Erasing Without Remembering: Safeguarding Knowledge Forgetting in Large Language Models
Feb 27, 2025



In this paper, we explore machine unlearning from a novel dimension, by studying how to safeguard model unlearning in large language models (LLMs). Our goal is to prevent unlearned models from recalling any related memory of the targeted knowledge.We begin by uncovering a surprisingly simple yet overlooked fact: existing methods typically erase only the exact expressions of the targeted knowledge, leaving paraphrased or related information intact. To rigorously measure such oversights, we introduce UGBench, the first benchmark tailored for evaluating the generalisation performance across 13 state-of-the-art methods.UGBench reveals that unlearned models can still recall paraphrased answers and retain target facts in intermediate layers. To address this, we propose PERMU, a perturbation-based method that significantly enhances the generalisation capabilities for safeguarding LLM unlearning.Experiments demonstrate that PERMU delivers up to a 50.13% improvement in unlearning while maintaining a 43.53% boost in robust generalisation. Our code can be found in https://github.com/MaybeLizzy/UGBench.
Memory-Augmented Agent Training for Business Document Understanding
Dec 17, 2024



Traditional enterprises face significant challenges in processing business documents, where tasks like extracting transport references from invoices remain largely manual despite their crucial role in logistics operations. While Large Language Models offer potential automation, their direct application to specialized business domains often yields unsatisfactory results. We introduce Matrix (Memory-Augmented agent Training through Reasoning and Iterative eXploration), a novel paradigm that enables LLM agents to progressively build domain expertise through experience-driven memory refinement and iterative learning. To validate this approach, we collaborate with one of the world's largest logistics companies to create a dataset of Universal Business Language format invoice documents, focusing on the task of transport reference extraction. Experiments demonstrate that Matrix outperforms prompting a single LLM by 30.3%, vanilla LLM agent by 35.2%. We further analyze the metrics of the optimized systems and observe that the agent system requires less API calls, fewer costs and can analyze longer documents on average. Our methods establish a new approach to transform general-purpose LLMs into specialized business tools through systematic memory enhancement in document processing tasks.
RA-PbRL: Provably Efficient Risk-Aware Preference-Based Reinforcement Learning
Oct 31, 2024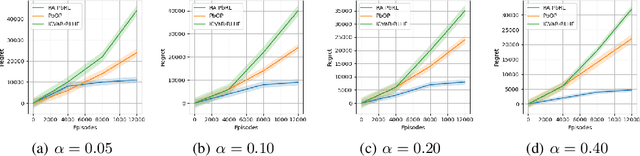
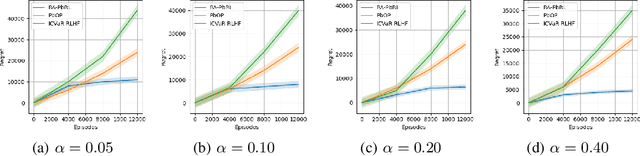
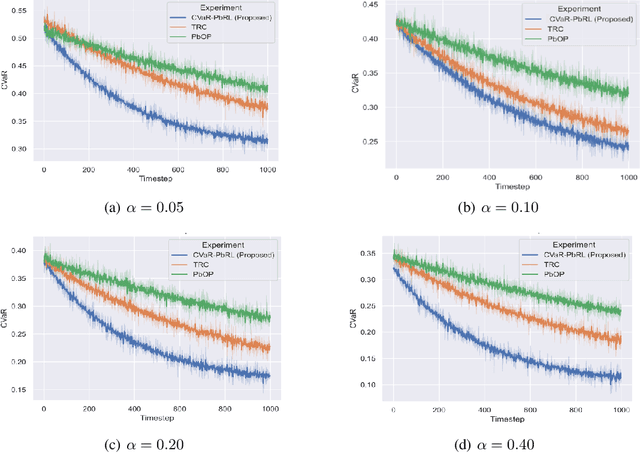
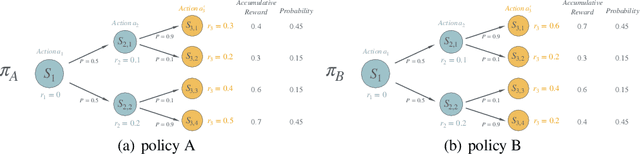
Preference-based Reinforcement Learning (PbRL) studies the problem where agents receive only preferences over pairs of trajectories in each episode. Traditional approaches in this field have predominantly focused on the mean reward or utility criterion. However, in PbRL scenarios demanding heightened risk awareness, such as in AI systems, healthcare, and agriculture, risk-aware measures are requisite. Traditional risk-aware objectives and algorithms are not applicable in such one-episode-reward settings. To address this, we explore and prove the applicability of two risk-aware objectives to PbRL: nested and static quantile risk objectives. We also introduce Risk-Aware- PbRL (RA-PbRL), an algorithm designed to optimize both nested and static objectives. Additionally, we provide a theoretical analysis of the regret upper bounds, demonstrating that they are sublinear with respect to the number of episodes, and present empirical results to support our findings. Our code is available in https://github.com/aguilarjose11/PbRLNeurips.
TreeBoN: Enhancing Inference-Time Alignment with Speculative Tree-Search and Best-of-N Sampling
Oct 18, 2024

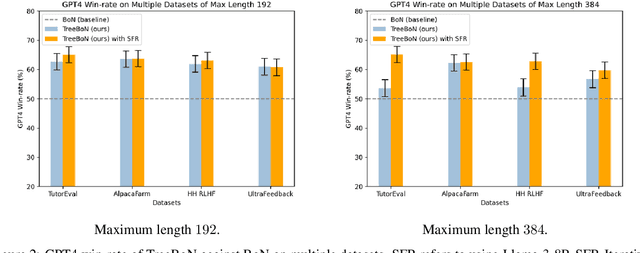

Inference-time alignment enhances the performance of large language models without requiring additional training or fine-tuning but presents challenges due to balancing computational efficiency with high-quality output. Best-of-N (BoN) sampling, as a simple yet powerful approach, generates multiple responses and selects the best one, achieving improved performance but with a high computational cost. We propose TreeBoN, a novel framework that integrates a speculative tree-search strategy into Best-of-N (BoN) Sampling. TreeBoN maintains a set of parent nodes, iteratively branching and pruning low-quality responses, thereby reducing computational overhead while maintaining high output quality. Our approach also leverages token-level rewards from Direct Preference Optimization (DPO) to guide tree expansion and prune low-quality paths. We evaluate TreeBoN using AlpacaFarm, UltraFeedback, GSM8K, HH-RLHF, and TutorEval datasets, demonstrating consistent improvements. Specifically, TreeBoN achieves a 65% win rate at maximum lengths of 192 and 384 tokens, outperforming standard BoN with the same computational cost. Furthermore, TreeBoN achieves around a 60% win rate across longer responses, showcasing its scalability and alignment efficacy.