 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Know When They Do Not Know: Calibration, Cascading, and Cleaning
Jan 12, 2026When a model knows when it does not know, many possibilities emerge. The first question is how to enable a model to recognize that it does not know. A promising approach is to use confidence, computed from the model's internal signals, to reflect its ignorance. Prior work in specific domains has shown that calibration can provide reliable confidence estimates. In this work, we propose a simple, effective, and universal training-free method that applies to both vision and language models, performing model calibration, cascading, and data cleaning to better exploit a model's ability to recognize when it does not know. We first highlight two key empirical observations: higher confidence corresponds to higher accuracy within a single model, and models calibrated on the validation set remain calibrated on a held-out test set. These findings empirically establish the reliability and comparability of calibrated confidence. Building on this, we introduce two applications: (1) model cascading with calibrated advantage routing and (2) data cleaning based on model ensemble. Using the routing signal derived from the comparability of calibrated confidences, we cascade large and small models to improve efficiency with almost no compromise in accuracy, and we further cascade two models of comparable scale to achieve performance beyond either model alone. Leveraging multiple experts and their calibrated confidences, we design a simple yet effective data-cleaning method that balances precision and detection rate to identify mislabeled samples in ImageNet and Massive Multitask Language Understanding (MMLU) datasets. Our results demonstrate that enabling models to recognize when they do not know is a practical step toward more efficient, reliable, and trustworthy AI.
Neural Motion Simulator: Pushing the Limit of World Models in Reinforcement Learning
Apr 09, 2025



An embodied system must not only model the patterns of the external world but also understand its own motion dynamics. A motion dynamic model is essential for efficient skill acquisition and effective planning. In this work, we introduce the neural motion simulator (MoSim), a world model that predicts the future physical state of an embodied system based on current observations and actions. MoSim achieves state-of-the-art performance in physical state prediction and provides competitive performance across a range of downstream tasks. This works shows that when a world model is accurate enough and performs precise long-horizon predictions, it can facilitate efficient skill acquisition in imagined worlds and even enable zero-shot reinforcement learning. Furthermore, MoSim can transform any model-free reinforcement learning (RL) algorithm into a model-based approach, effectively decoupling physical environment modeling from RL algorithm development. This separation allows for independent advancements in RL algorithms and world modeling, significantly improving sample efficiency and enhancing generalization capabilities. Our findings highlight that world models for motion dynamics is a promising direction for developing more versatile and capable embodied systems.
RA-PbRL: Provably Efficient Risk-Aware Preference-Based Reinforcement Learning
Oct 31, 2024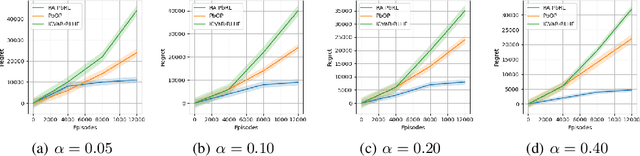
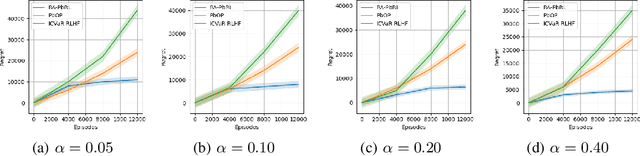
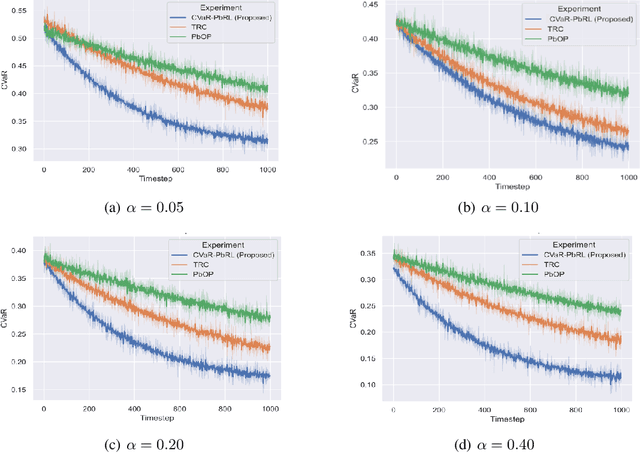
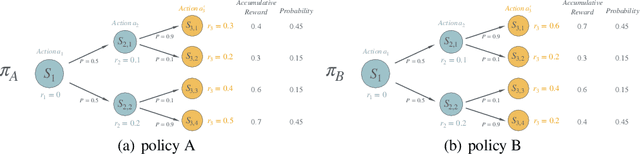
Preference-based Reinforcement Learning (PbRL) studies the problem where agents receive only preferences over pairs of trajectories in each episode. Traditional approaches in this field have predominantly focused on the mean reward or utility criterion. However, in PbRL scenarios demanding heightened risk awareness, such as in AI systems, healthcare, and agriculture, risk-aware measures are requisite. Traditional risk-aware objectives and algorithms are not applicable in such one-episode-reward settings. To address this, we explore and prove the applicability of two risk-aware objectives to PbRL: nested and static quantile risk objectives. We also introduce Risk-Aware- PbRL (RA-PbRL), an algorithm designed to optimize both nested and static objectives. Additionally, we provide a theoretical analysis of the regret upper bounds, demonstrating that they are sublinear with respect to the number of episodes, and present empirical results to support our findings. Our code is available in https://github.com/aguilarjose11/PbRLNeurips.