 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Driving Perception: A Flexible Scale-Driven Family for Self-Supervised Monocular Depth Estimation
Jul 01, 2026Self-Supervised Monocular Depth Estimation (MDE) has garnered attention in recent years due to its independence from ground truth. However, most existing models are limited to a single scale and exhibit considerable performance degradation in complex driving environments. Networks specifically designed to handle dynamic traffic participants tend to be overly complex, hindering their deployment on resource-constrained automotive edge devices. To address these limitations and move towards robust driving perception, we propose FlexDepth, a scale-driven and flexible family of self-supervised MDE models tailored for challenging road scenarios. FlexDepth employs a two-stage static-dynamic decoupled training strategy, enabling the independent assessment of confidence for both static backgrounds and dynamic road objects. Furthermore, it introduces a meticulously designed Scale-Driven Decoder (SDD) to dynamically select components based on scale size, facilitating efficient feature fusion and the output of high-precision depth maps. Extensive experiments on standard driving benchmarks demonstrate that without any auxiliary information, our model achieves state-of-the-art performance across arbitrary scales with minimal computational overhead. Our smallest model, Flex-Nano, requires only 0.7 GFLOPs and achieves 37.6 FPS on mobile platforms, ensuring reliable real-time perception while maintaining excellent zero-shot generalization.Our source code is avalible: https://github.com/startnew/flexdepth
SCARCE: Scalable Cascade Analysis for Rare-event Characterisation via Embeddings
Jun 28, 2026Rare events govern the safety profile of modern AI systems, yet their probabilities are extremely difficult to estimate: direct Monte Carlo requires prohibitive sample budgets. Subset Simulation (SS) addresses this by decomposing a rare-event probability into moderate conditional probabilities over nested intermediate events. However, classical SS requires a handcrafted scalar performance function whose sublevel sets define those events, demanding detailed knowledge of the failure geometry and limiting transfer to new domains. We propose SCARCE (Scalable Cascade Analysis for Rare-event Characterisation via Embeddings), which replaces the performance function with learned latent representations and geometric rulers that score proximity to failure regions. Adaptive thresholding constructs nested intermediate events directly from data. We formalise SCARCE through a non-negative supermartingale, yielding a high-probability upper envelope that remains valid under early stopping. On MNIST misclassification, where dense Monte Carlo provides ground truth, SCARCE achieves approximately 400--500 times lower mean absolute error than grid-searched traditional SS while eliminating systematic over-counting. We then study PAIR-style LLM jailbreaks under a fleet-level threat model with adversarial fraction $η$. On Llama-Guard-3-8B hidden states, a PCA-based ruler attains 2.6% mean relative error for $η\geq 10^{-3}$ against finite-sample references whose average bootstrap relative half-width is 27.9%, and transfers to a GCG-style corpus with 2.93% relative error after recalibration. A directional criterion $\mathrm{KL}(p_{\mathrm{good}}\,\|\,p_{\mathrm{bad}})$ ranks rulers consistently with estimation error (Spearman $ρ=0.83$).
S2MAM: Semi-supervised Meta Additive Model for Robust Estimation and Variable Selection
Apr 21, 2026Semi-supervised learning with manifold regularization is a classical framework for jointly learning from both labeled and unlabeled data, where the key requirement is that the support of the unknown marginal distribution has the geometric structure of a Riemannian manifold. Typically, the Laplace-Beltrami operator-based manifold regularization can be approximated empirically by the Laplacian regularization associated with the entire training data and its corresponding graph Laplacian matrix. However, the graph Laplacian matrix depends heavily on the prespecified similarity metric and may lead to inappropriate penalties when dealing with redundant or noisy input variables. To address the above issues, this paper proposes a new \textit{Semi-Supervised Meta Additive Model (S$^2$MAM) based on a bilevel optimization scheme that automatically identifies informative variables, updates the similarity matrix, and simultaneously achieves interpretable predictions. Theoretical guarantees are provided for S$^2$MAM, including the computing convergence and the statistical generalization bound. Experimental assessments across 4 synthetic and 12 real-world datasets, with varying levels and categories of corruption, validate the robustness and interpretability of the proposed approach.
BadCLIP++: Stealthy and Persistent Backdoors in Multimodal Contrastive Learning
Feb 19, 2026Research on backdoor attacks against multimodal contrastive learning models faces two key challenges: stealthiness and persistence. Existing methods often fail under strong detection or continuous fine-tuning, largely due to (1) cross-modal inconsistency that exposes trigger patterns and (2) gradient dilution at low poisoning rates that accelerates backdoor forgetting. These coupled causes remain insufficiently modeled and addressed. We propose BadCLIP++, a unified framework that tackles both challenges. For stealthiness, we introduce a semantic-fusion QR micro-trigger that embeds imperceptible patterns near task-relevant regions, preserving clean-data statistics while producing compact trigger distributions. We further apply target-aligned subset selection to strengthen signals at low injection rates. For persistence, we stabilize trigger embeddings via radius shrinkage and centroid alignment, and stabilize model parameters through curvature control and elastic weight consolidation, maintaining solutions within a low-curvature wide basin resistant to fine-tuning. We also provide the first theoretical analysis showing that, within a trust region, gradients from clean fine-tuning and backdoor objectives are co-directional, yielding a non-increasing upper bound on attack success degradation. Experiments demonstrate that with only 0.3% poisoning, BadCLIP++ achieves 99.99% attack success rate (ASR) in digital settings, surpassing baselines by 11.4 points. Across nineteen defenses, ASR remains above 99.90% with less than 0.8% drop in clean accuracy. The method further attains 65.03% success in physical attacks and shows robustness against watermark removal defenses.
Why Self-Rewarding Works: Theoretical Guarantees for Iterative Alignment of Language Models
Jan 30, 2026Self-Rewarding Language Models (SRLMs) achieve notable success in iteratively improving alignment without external feedback. Yet, despite their striking empirical progress, the core mechanisms driving their capabilities remain unelucidated, leaving a critical gap in theoretical understanding. This paper provides the first rigorous theoretical guarantees for SRLMs. We first establish a lower bound that characterizes the fundamental limits of a single update step, revealing a critical dependence on the quality of the initial model. We then derive finite-sample error bounds for the full iterative paradigm, showing that performance improves at a rate of $\widetilde{\mathcal{O}}\left(1/\sqrt{n}\right)$ with sample size $n$. Crucially, our analysis reveals that the dependence on the initial model decays exponentially with the number of iterations $T$. This provides a formal explanation for why self-rewarding succeeds: it robustly overcomes poor initialization by steering the dynamics toward internal stability and consistency. Finally, we instantiate our theoretical framework for the linear softmax model class, yielding tailored guarantees that connect our high-level insights to practical model architectures.
Language as Prior, Vision as Calibration: Metric Scale Recovery for Monocular Depth Estimation
Jan 07, 2026Relative-depth foundation models transfer well, yet monocular metric depth remains ill-posed due to unidentifiable global scale and heightened domain-shift sensitivity. Under a frozen-backbone calibration setting, we recover metric depth via an image-specific affine transform in inverse depth and train only lightweight calibration heads while keeping the relative-depth backbone and the CLIP text encoder fixed. Since captions provide coarse but noisy scale cues that vary with phrasing and missing objects, we use language to predict an uncertainty-aware envelope that bounds feasible calibration parameters in an unconstrained space, rather than committing to a text-only point estimate. We then use pooled multi-scale frozen visual features to select an image-specific calibration within this envelope. During training, a closed-form least-squares oracle in inverse depth provides per-image supervision for learning the envelope and the selected calibration. Experiments on NYUv2 and KITTI improve in-domain accuracy, while zero-shot transfer to SUN-RGBD and DDAD demonstrates improved robustness over strong language-only baselines.
CoVeR: Conformal Calibration for Versatile and Reliable Autoregressive Next-Token Prediction
Sep 05, 2025
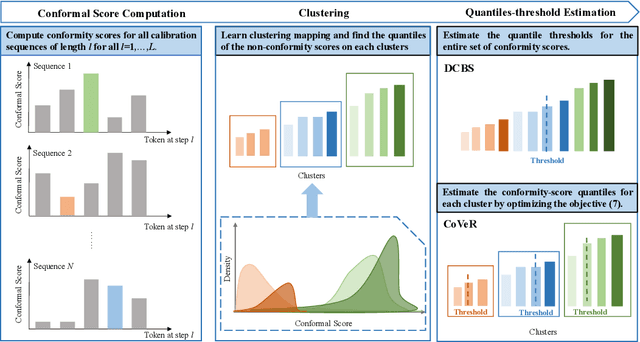
Autoregressive pre-trained models combined with decoding methods have achieved impressive performance on complex reasoning tasks. While mainstream decoding strategies such as beam search can generate plausible candidate sets, they often lack provable coverage guarantees, and struggle to effectively balance search efficiency with the need for versatile trajectories, particularly those involving long-tail sequences that are essential in certain real-world applications. To address these limitations, we propose \textsc{CoVeR}, a novel model-free decoding strategy wihtin the conformal prediction framework that simultaneously maintains a compact search space and ensures high coverage probability over desirable trajectories. Theoretically, we establish a PAC-style generalization bound, guaranteeing that \textsc{CoVeR} asymptotically achieves a coverage rate of at least $1 - \alpha$ for any target level $\alpha \in (0,1)$.
Consistent Paths Lead to Truth: Self-Rewarding Reinforcement Learning for LLM Reasoning
Jun 10, 2025Recent advances of Reinforcement Learning (RL) have highlighted its potential in complex reasoning tasks, yet effective training often relies on external supervision, which limits the broader applicability. In this work, we propose a novel self-rewarding reinforcement learning framework to enhance Large Language Model (LLM) reasoning by leveraging the consistency of intermediate reasoning states across different reasoning trajectories. Our key insight is that correct responses often exhibit consistent trajectory patterns in terms of model likelihood: their intermediate reasoning states tend to converge toward their own final answers (high consistency) with minimal deviation toward other candidates (low volatility). Inspired by this observation, we introduce CoVo, an intrinsic reward mechanism that integrates Consistency and Volatility via a robust vector-space aggregation strategy, complemented by a curiosity bonus to promote diverse exploration. CoVo enables LLMs to perform RL in a self-rewarding manner, offering a scalable pathway for learning to reason without external supervision. Extensive experiments on diverse reasoning benchmarks show that CoVo achieves performance comparable to or even surpassing supervised RL. Our code is available at https://github.com/sastpg/CoVo.
MLLM-Guided VLM Fine-Tuning with Joint Inference for Zero-Shot Composed Image Retrieval
May 26, 2025Existing Zero-Shot Composed Image Retrieval (ZS-CIR) methods typically train adapters that convert reference images into pseudo-text tokens, which are concatenated with the modifying text and processed by frozen text encoders in pretrained VLMs or LLMs. While this design leverages the strengths of large pretrained models, it only supervises the adapter to produce encoder-compatible tokens that loosely preserve visual semantics. Crucially, it does not directly optimize the composed query representation to capture the full intent of the composition or to align with the target semantics, thereby limiting retrieval performance, particularly in cases involving fine-grained or complex visual transformations. To address this problem, we propose MLLM-Guided VLM Fine-Tuning with Joint Inference (MVFT-JI), a novel approach that leverages a pretrained multimodal large language model (MLLM) to construct two complementary training tasks using only unlabeled images: target text retrieval taskand text-to-image retrieval task. By jointly optimizing these tasks, our method enables the VLM to inherently acquire robust compositional retrieval capabilities, supported by the provided theoretical justifications and empirical validation. Furthermore, during inference, we further prompt the MLLM to generate target texts from composed queries and compute retrieval scores by integrating similarities between (i) the composed query and candidate images, and (ii) the MLLM-generated target text and candidate images. This strategy effectively combines the VLM's semantic alignment strengths with the MLLM's reasoning capabilities.
Multimodal Reasoning Agent for Zero-Shot Composed Image Retrieval
May 26, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve target images given a compositional query, consisting of a reference image and a modifying text-without relying on annotated training data. Existing approaches often generate a synthetic target text using large language models (LLMs) to serve as an intermediate anchor between the compositional query and the target image. Models are then trained to align the compositional query with the generated text, and separately align images with their corresponding texts using contrastive learning. However, this reliance on intermediate text introduces error propagation, as inaccuracies in query-to-text and text-to-image mappings accumulate, ultimately degrading retrieval performance. To address these problems, we propose a novel framework by employing a Multimodal Reasoning Agent (MRA) for ZS-CIR. MRA eliminates the dependence on textual intermediaries by directly constructing triplets, <reference image, modification text, target image>, using only unlabeled image data. By training on these synthetic triplets, our model learns to capture the relationships between compositional queries and candidate images directly. Extensive experiments on three standard CIR benchmarks demonstrate the effectiveness of our approach. On the FashionIQ dataset, our method improves Average R@10 by at least 7.5\% over existing baselines; on CIRR, it boosts R@1 by 9.6\%; and on CIRCO, it increases mAP@5 by 9.5\%.