 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPA-Cache: Singular Proxies for Adaptive Caching in Diffusion Language Models
Jan 30, 2026While Diffusion Language Models (DLMs) offer a flexible, arbitrary-order alternative to the autoregressive paradigm, their non-causal nature precludes standard KV caching, forcing costly hidden state recomputation at every decoding step. Existing DLM caching approaches reduce this cost by selective hidden state updates; however, they are still limited by (i) costly token-wise update identification heuristics and (ii) rigid, uniform budget allocation that fails to account for heterogeneous hidden state dynamics. To address these challenges, we present SPA-Cache that jointly optimizes update identification and budget allocation in DLM cache. First, we derive a low-dimensional singular proxy that enables the identification of update-critical tokens in a low-dimensional subspace, substantially reducing the overhead of update identification. Second, we introduce an adaptive strategy that allocates fewer updates to stable layers without degrading generation quality. Together, these contributions significantly improve the efficiency of DLMs, yielding up to an $8\times$ throughput improvement over vanilla decoding and a $2$--$4\times$ speedup over existing caching baselines.
AD-FM: Multimodal LLMs for Anomaly Detection via Multi-Stage Reasoning and Fine-Grained Reward Optimization
Aug 06, 2025



While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities across diverse domains, their application to specialized anomaly detection (AD) remains constrained by domain adaptation challenges. Existing Group Relative Policy Optimization (GRPO) based approaches suffer from two critical limitations: inadequate training data utilization when models produce uniform responses, and insufficient supervision over reasoning processes that encourage immediate binary decisions without deliberative analysis. We propose a comprehensive framework addressing these limitations through two synergistic innovations. First, we introduce a multi-stage deliberative reasoning process that guides models from region identification to focused examination, generating diverse response patterns essential for GRPO optimization while enabling structured supervision over analytical workflows. Second, we develop a fine-grained reward mechanism incorporating classification accuracy and localization supervision, transforming binary feedback into continuous signals that distinguish genuine analytical insight from spurious correctness. Comprehensive evaluation across multiple industrial datasets demonstrates substantial performance improvements in adapting general vision-language models to specialized anomaly detection. Our method achieves superior accuracy with efficient adaptation of existing annotations, effectively bridging the gap between general-purpose MLLM capabilities and the fine-grained visual discrimination required for detecting subtle manufacturing defects and structural irregularities.
Multimodal Reasoning Agent for Zero-Shot Composed Image Retrieval
May 26, 2025Zero-Shot Composed Image Retrieval (ZS-CIR) aims to retrieve target images given a compositional query, consisting of a reference image and a modifying text-without relying on annotated training data. Existing approaches often generate a synthetic target text using large language models (LLMs) to serve as an intermediate anchor between the compositional query and the target image. Models are then trained to align the compositional query with the generated text, and separately align images with their corresponding texts using contrastive learning. However, this reliance on intermediate text introduces error propagation, as inaccuracies in query-to-text and text-to-image mappings accumulate, ultimately degrading retrieval performance. To address these problems, we propose a novel framework by employing a Multimodal Reasoning Agent (MRA) for ZS-CIR. MRA eliminates the dependence on textual intermediaries by directly constructing triplets, <reference image, modification text, target image>, using only unlabeled image data. By training on these synthetic triplets, our model learns to capture the relationships between compositional queries and candidate images directly. Extensive experiments on three standard CIR benchmarks demonstrate the effectiveness of our approach. On the FashionIQ dataset, our method improves Average R@10 by at least 7.5\% over existing baselines; on CIRR, it boosts R@1 by 9.6\%; and on CIRCO, it increases mAP@5 by 9.5\%.
VORTA: Efficient Video Diffusion via Routing Sparse Attention
May 24, 2025Video Diffusion Transformers (VDiTs) have achieved remarkable progress in high-quality video generation, but remain computationally expensive due to the quadratic complexity of attention over high-dimensional video sequences. Recent attention acceleration methods leverage the sparsity of attention patterns to improve efficiency; however, they often overlook inefficiencies of redundant long-range interactions. To address this problem, we propose \textbf{VORTA}, an acceleration framework with two novel components: 1) a sparse attention mechanism that efficiently captures long-range dependencies, and 2) a routing strategy that adaptively replaces full 3D attention with specialized sparse attention variants throughout the sampling process. It achieves a $1.76\times$ end-to-end speedup without quality loss on VBench. Furthermore, VORTA can seamlessly integrate with various other acceleration methods, such as caching and step distillation, reaching up to $14.41\times$ speedup with negligible performance degradation. VORTA demonstrates its efficiency and enhances the practicality of VDiTs in real-world settings.
Attentive Eraser: Unleashing Diffusion Model's Object Removal Potential via Self-Attention Redirection Guidance
Dec 17, 2024
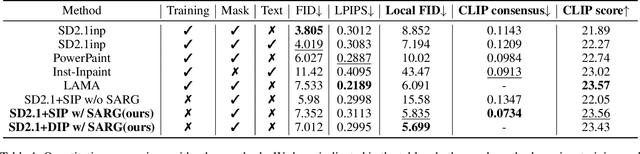
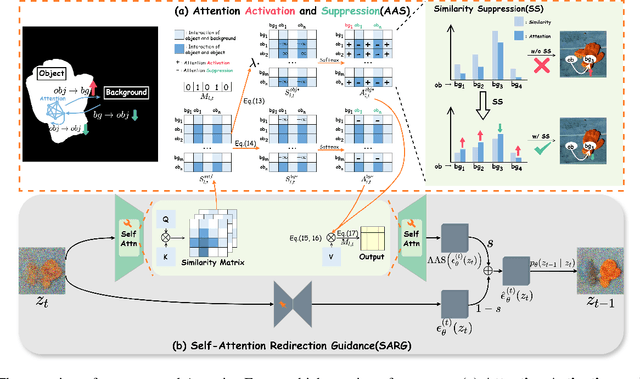
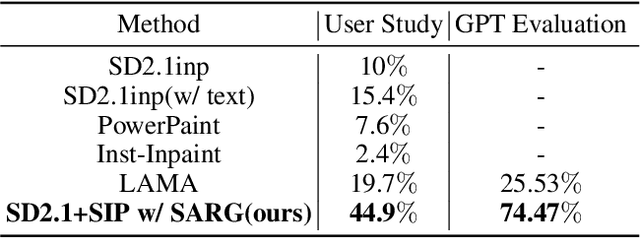
Recently, diffusion models have emerged as promising newcomers in the field of generative models, shining brightly in image generation. However, when employed for object removal tasks, they still encounter issues such as generating random artifacts and the incapacity to repaint foreground object areas with appropriate content after removal. To tackle these problems, we propose Attentive Eraser, a tuning-free method to empower pre-trained diffusion models for stable and effective object removal. Firstly, in light of the observation that the self-attention maps influence the structure and shape details of the generated images, we propose Attention Activation and Suppression (ASS), which re-engineers the self-attention mechanism within the pre-trained diffusion models based on the given mask, thereby prioritizing the background over the foreground object during the reverse generation process. Moreover, we introduce Self-Attention Redirection Guidance (SARG), which utilizes the self-attention redirected by ASS to guide the generation process, effectively removing foreground objects within the mask while simultaneously generating content that is both plausible and coherent. Experiments demonstrate the stability and effectiveness of Attentive Eraser in object removal across a variety of pre-trained diffusion models, outperforming even training-based methods. Furthermore, Attentive Eraser can be implemented in various diffusion model architectures and checkpoints, enabling excellent scalability. Code is available at https://github.com/Anonym0u3/AttentiveEraser.
AsymRnR: Video Diffusion Transformers Acceleration with Asymmetric Reduction and Restoration
Dec 16, 2024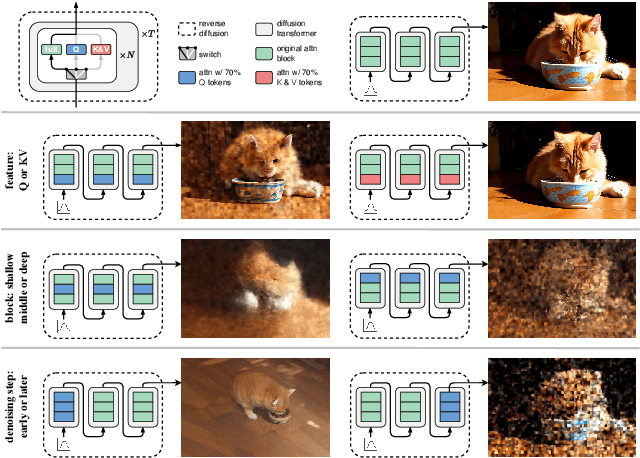
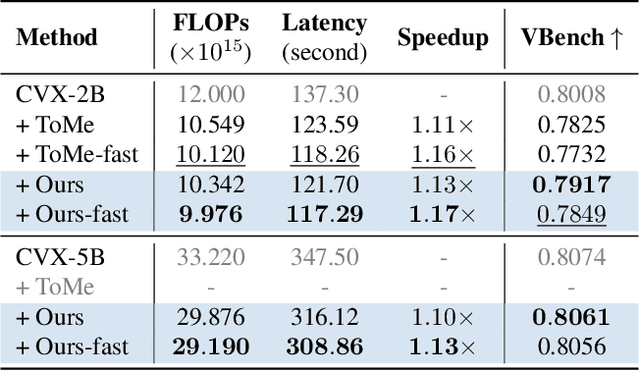
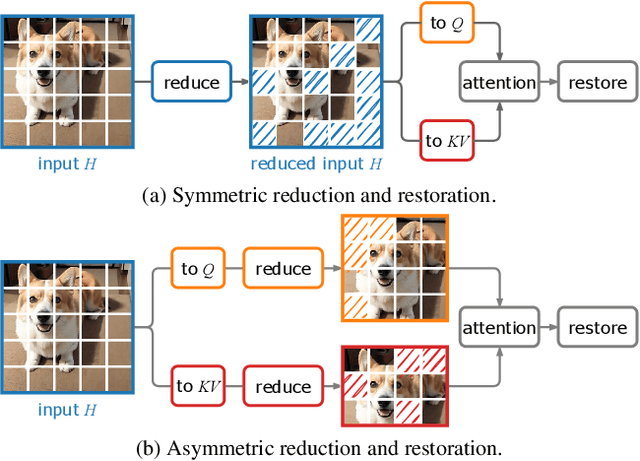
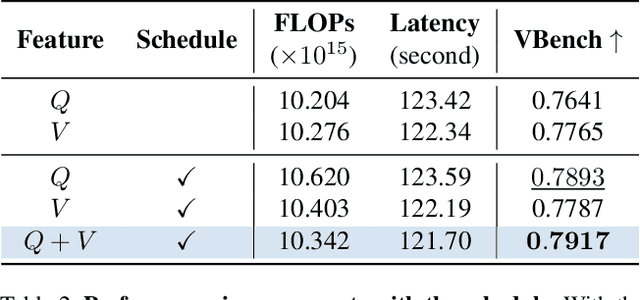
Video Diffusion Transformers (DiTs) have demonstrated significant potential for generating high-fidelity videos but are computationally intensive. Existing acceleration methods include distillation, which requires costly retraining, and feature caching, which is highly sensitive to network architecture. Recent token reduction methods are training-free and architecture-agnostic, offering greater flexibility and wider applicability. However, they enforce the same sequence length across different components, constraining their acceleration potential. We observe that intra-sequence redundancy in video DiTs varies across features, blocks, and denoising timesteps. Building on this observation, we propose Asymmetric Reduction and Restoration (AsymRnR), a training-free approach to accelerate video DiTs. It offers a flexible and adaptive strategy that reduces the number of tokens based on their redundancy to enhance both acceleration and generation quality. We further propose matching cache to facilitate faster processing. Integrated into state-of-the-art video DiTs, AsymRnR achieves a superior speedup without compromising the quality.
DaDu-E: Rethinking the Role of Large Language Model in Robotic Computing Pipeline
Dec 02, 2024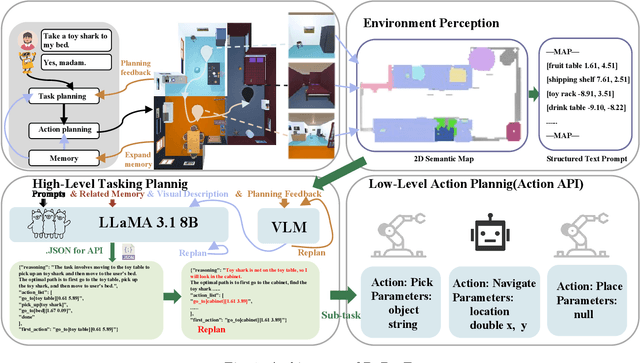



Performing complex tasks in open environments remains challenging for robots, even when using large language models (LLMs) as the core planner. Many LLM-based planners are inefficient due to their large number of parameters and prone to inaccuracies because they operate in open-loop systems. We think the reason is that only applying LLMs as planners is insufficient. In this work, we propose DaDu-E, a robust closed-loop planning framework for embodied AI robots. Specifically, DaDu-E is equipped with a relatively lightweight LLM, a set of encapsulated robot skill instructions, a robust feedback system, and memory augmentation. Together, these components enable DaDu-E to (i) actively perceive and adapt to dynamic environments, (ii) optimize computational costs while maintaining high performance, and (iii) recover from execution failures using its memory and feedback mechanisms. Extensive experiments on real-world and simulated tasks show that DaDu-E achieves task success rates comparable to embodied AI robots with larger models as planners like COME-Robot, while reducing computational requirements by $6.6 \times$. Users are encouraged to explore our system at: \url{https://rlc-lab.github.io/dadu-e/}.
SPAgent: Adaptive Task Decomposition and Model Selection for General Video Generation and Editing
Nov 28, 2024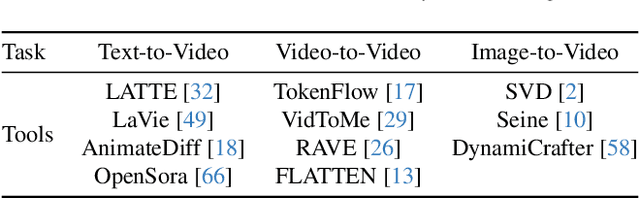
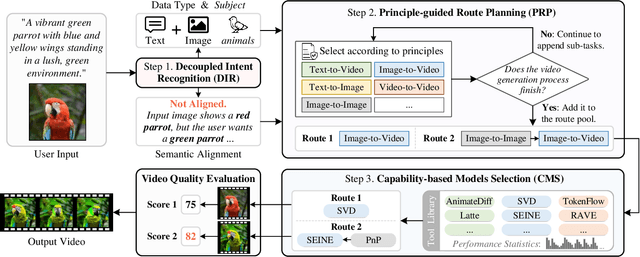

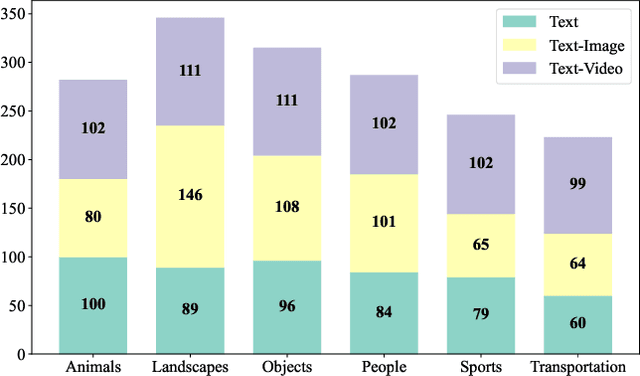
While open-source video generation and editing models have made significant progress, individual models are typically limited to specific tasks, failing to meet the diverse needs of users. Effectively coordinating these models can unlock a wide range of video generation and editing capabilities. However, manual coordination is complex and time-consuming, requiring users to deeply understand task requirements and possess comprehensive knowledge of each model's performance, applicability, and limitations, thereby increasing the barrier to entry. To address these challenges, we propose a novel video generation and editing system powered by our Semantic Planning Agent (SPAgent). SPAgent bridges the gap between diverse user intents and the effective utilization of existing generative models, enhancing the adaptability, efficiency, and overall quality of video generation and editing. Specifically, the SPAgent assembles a tool library integrating state-of-the-art open-source image and video generation and editing models as tools. After fine-tuning on our manually annotated dataset, SPAgent can automatically coordinate the tools for video generation and editing, through our novelly designed three-step framework: (1) decoupled intent recognition, (2) principle-guided route planning, and (3) capability-based execution model selection. Additionally, we enhance the SPAgent's video quality evaluation capability, enabling it to autonomously assess and incorporate new video generation and editing models into its tool library without human intervention. Experimental results demonstrate that the SPAgent effectively coordinates models to generate or edit videos, highlighting its versatility and adaptability across various video tasks.
Diffusion Model-Based Video Editing: A Survey
Jun 26, 2024



The rapid development of diffusion models (DMs) has significantly advanced image and video applications, making "what you want is what you see" a reality. Among these, video editing has gained substantial attention and seen a swift rise in research activity, necessitating a comprehensive and systematic review of the existing literature. This paper reviews diffusion model-based video editing techniques, including theoretical foundations and practical applications. We begin by overviewing the mathematical formulation and image domain's key methods. Subsequently, we categorize video editing approaches by the inherent connections of their core technologies, depicting evolutionary trajectory. This paper also dives into novel applications, including point-based editing and pose-guided human video editing. Additionally, we present a comprehensive comparison using our newly introduced V2VBench. Building on the progress achieved to date, the paper concludes with ongoing challenges and potential directions for future research.
Class-based Quantization for Neural Networks
Nov 27, 2022In deep neural networks (DNNs), there are a huge number of weights and multiply-and-accumulate (MAC) operations. Accordingly, it is challenging to apply DNNs on resource-constrained platforms, e.g., mobile phones. Quantization is a method to reduce the size and the computational complexity of DNNs. Existing quantization methods either require hardware overhead to achieve a non-uniform quantization or focus on model-wise and layer-wise uniform quantization, which are not as fine-grained as filter-wise quantization. In this paper, we propose a class-based quantization method to determine the minimum number of quantization bits for each filter or neuron in DNNs individually. In the proposed method, the importance score of each filter or neuron with respect to the number of classes in the dataset is first evaluated. The larger the score is, the more important the filter or neuron is and thus the larger the number of quantization bits should be. Afterwards, a search algorithm is adopted to exploit the different importance of filters and neurons to determine the number of quantization bits of each filter or neuron. Experimental results demonstrate that the proposed method can maintain the inference accuracy with low bit-width quantization. Given the same number of quantization bits, the proposed method can also achieve a better inference accuracy than the existing methods.