 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-based Quantization for Neural Networks
Nov 27, 2022In deep neural networks (DNNs), there are a huge number of weights and multiply-and-accumulate (MAC) operations. Accordingly, it is challenging to apply DNNs on resource-constrained platforms, e.g., mobile phones. Quantization is a method to reduce the size and the computational complexity of DNNs. Existing quantization methods either require hardware overhead to achieve a non-uniform quantization or focus on model-wise and layer-wise uniform quantization, which are not as fine-grained as filter-wise quantization. In this paper, we propose a class-based quantization method to determine the minimum number of quantization bits for each filter or neuron in DNNs individually. In the proposed method, the importance score of each filter or neuron with respect to the number of classes in the dataset is first evaluated. The larger the score is, the more important the filter or neuron is and thus the larger the number of quantization bits should be. Afterwards, a search algorithm is adopted to exploit the different importance of filters and neurons to determine the number of quantization bits of each filter or neuron. Experimental results demonstrate that the proposed method can maintain the inference accuracy with low bit-width quantization. Given the same number of quantization bits, the proposed method can also achieve a better inference accuracy than the existing methods.
SteppingNet: A Stepping Neural Network with Incremental Accuracy Enhancement
Nov 27, 2022


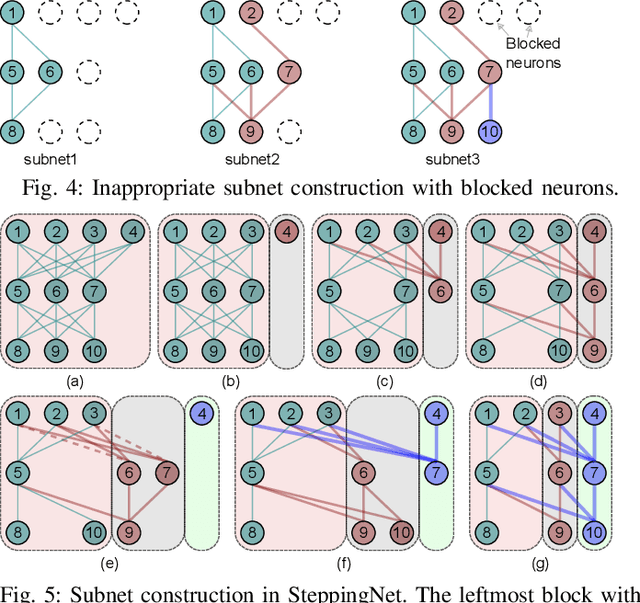
Deep neural networks (DNNs) have successfully been applied in many fields in the past decades. However, the increasing number of multiply-and-accumulate (MAC) operations in DNNs prevents their application in resource-constrained and resource-varying platforms, e.g., mobile phones and autonomous vehicles. In such platforms, neural networks need to provide acceptable results quickly and the accuracy of the results should be able to be enhanced dynamically according to the computational resources available in the computing system. To address these challenges, we propose a design framework called SteppingNet. SteppingNet constructs a series of subnets whose accuracy is incrementally enhanced as more MAC operations become available. Therefore, this design allows a trade-off between accuracy and latency. In addition, the larger subnets in SteppingNet are built upon smaller subnets, so that the results of the latter can directly be reused in the former without recomputation. This property allows SteppingNet to decide on-the-fly whether to enhance the inference accuracy by executing further MAC operations. Experimental results demonstrate that SteppingNet provides an effective incremental accuracy improvement and its inference accuracy consistently outperforms the state-of-the-art work under the same limit of computational resources.