 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV Packet: Recomputation-Free Context-Independent KV Caching for LLMs
Apr 14, 2026Large Language Models (LLMs) rely heavily on Key-Value (KV) caching to minimize inference latency. However, standard KV caches are context-dependent: reusing a cached document in a new context requires recomputing KV states to account for shifts in attention distribution. Existing solutions such as CacheBlend, EPIC, and SAM-KV mitigate this issue by selectively recomputing a subset of tokens; however, they still incur non-negligible computational overhead (FLOPs) and increased Time-to-First-Token (TTFT) latency. In this paper, we propose KV Packet, a recomputation-free cache reuse framework that treats cached documents as immutable ``packets'' wrapped in light-weight trainable soft-token adapters, which are trained via self-supervised distillation to bridge context discontinuities. Experiments on Llama-3.1 and Qwen2.5 demonstrate that the proposed KV Packet method achieves near-zero FLOPs and lower TTFT than recomputation-based baselines, while retaining F1 scores comparable to those of the full recomputation baseline.
FactorHD: A Hyperdimensional Computing Model for Multi-Object Multi-Class Representation and Factorization
Jul 16, 2025Neuro-symbolic artificial intelligence (neuro-symbolic AI) excels in logical analysis and reasoning. Hyperdimensional Computing (HDC), a promising brain-inspired computational model, is integral to neuro-symbolic AI. Various HDC models have been proposed to represent class-instance and class-class relations, but when representing the more complex class-subclass relation, where multiple objects associate different levels of classes and subclasses, they face challenges for factorization, a crucial task for neuro-symbolic AI systems. In this article, we propose FactorHD, a novel HDC model capable of representing and factorizing the complex class-subclass relation efficiently. FactorHD features a symbolic encoding method that embeds an extra memorization clause, preserving more information for multiple objects. In addition, it employs an efficient factorization algorithm that selectively eliminates redundant classes by identifying the memorization clause of the target class. Such model significantly enhances computing efficiency and accuracy in representing and factorizing multiple objects with class-subclass relation, overcoming limitations of existing HDC models such as "superposition catastrophe" and "the problem of 2". Evaluations show that FactorHD achieves approximately 5667x speedup at a representation size of 10^9 compared to existing HDC models. When integrated with the ResNet-18 neural network, FactorHD achieves 92.48% factorization accuracy on the Cifar-10 dataset.
Trustworthy Tree-based Machine Learning by $MoS_2$ Flash-based Analog CAM with Inherent Soft Boundaries
Jul 16, 2025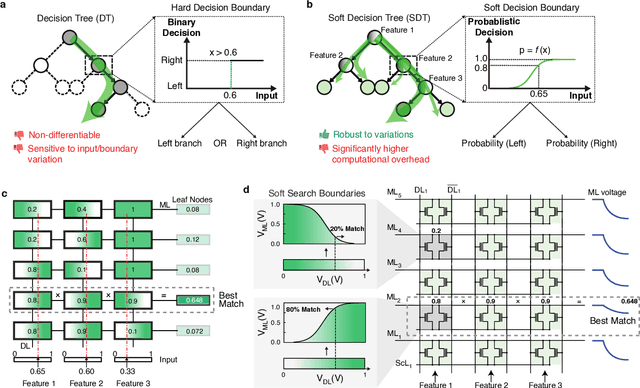
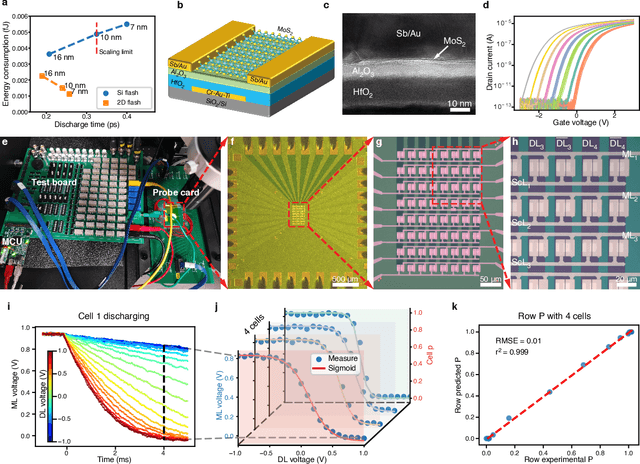
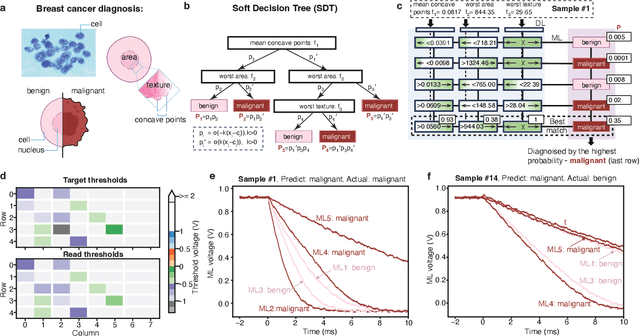
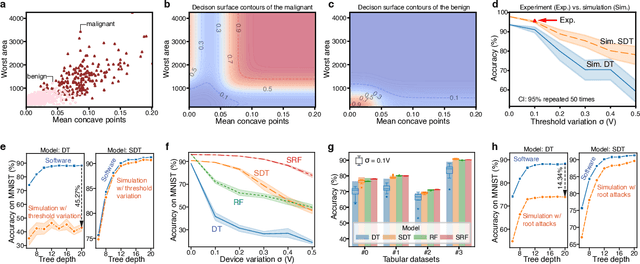
The rapid advancement of artificial intelligence has raised concerns regarding its trustworthiness, especially in terms of interpretability and robustness. Tree-based models like Random Forest and XGBoost excel in interpretability and accuracy for tabular data, but scaling them remains computationally expensive due to poor data locality and high data dependence. Previous efforts to accelerate these models with analog content addressable memory (CAM) have struggled, due to the fact that the difficult-to-implement sharp decision boundaries are highly susceptible to device variations, which leads to poor hardware performance and vulnerability to adversarial attacks. This work presents a novel hardware-software co-design approach using $MoS_2$ Flash-based analog CAM with inherent soft boundaries, enabling efficient inference with soft tree-based models. Our soft tree model inference experiments on $MoS_2$ analog CAM arrays show this method achieves exceptional robustness against device variation and adversarial attacks while achieving state-of-the-art accuracy. Specifically, our fabricated analog CAM arrays achieve $96\%$ accuracy on Wisconsin Diagnostic Breast Cancer (WDBC) database, while maintaining decision explainability. Our experimentally calibrated model validated only a $0.6\%$ accuracy drop on the MNIST dataset under $10\%$ device threshold variation, compared to a $45.3\%$ drop for traditional decision trees. This work paves the way for specialized hardware that enhances AI's trustworthiness and efficiency.
FeBiM: Efficient and Compact Bayesian Inference Engine Empowered with Ferroelectric In-Memory Computing
Oct 25, 2024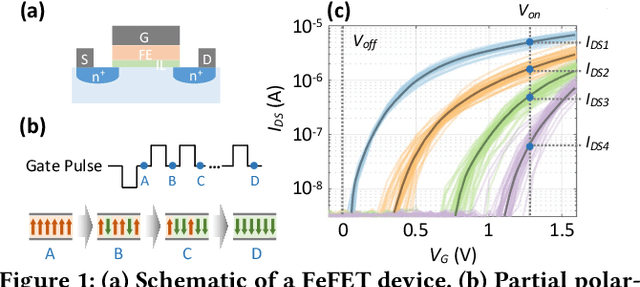
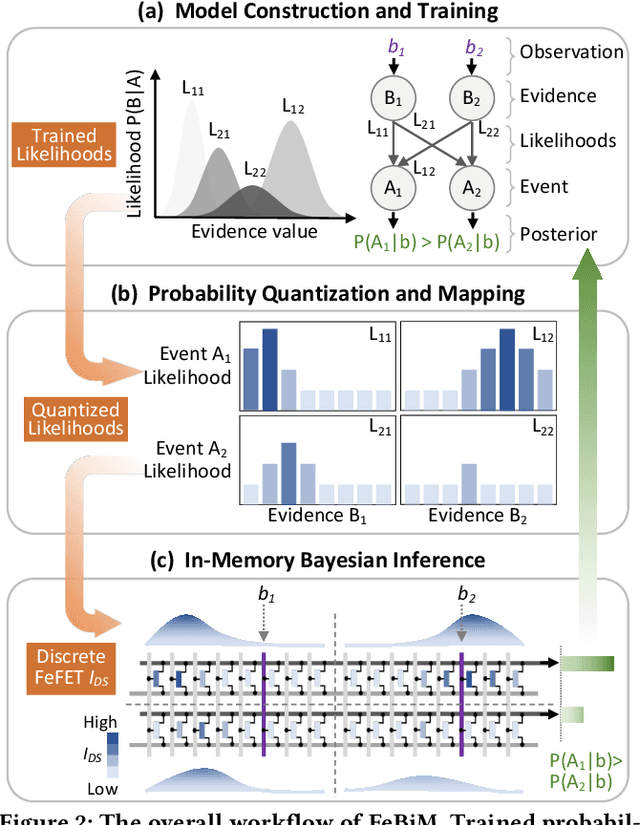
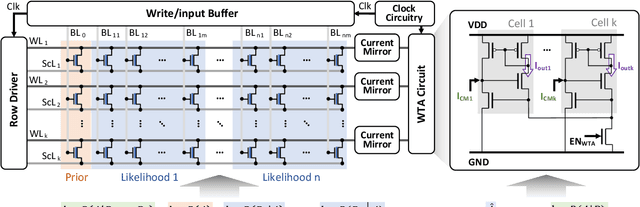
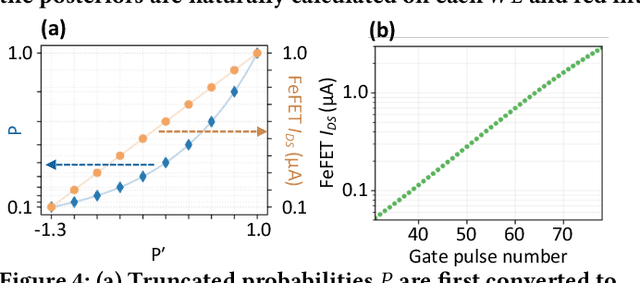
In scenarios with limited training data or where explainability is crucial, conventional neural network-based machine learning models often face challenges. In contrast, Bayesian inference-based algorithms excel in providing interpretable predictions and reliable uncertainty estimation in these scenarios. While many state-of-the-art in-memory computing (IMC) architectures leverage emerging non-volatile memory (NVM) technologies to offer unparalleled computing capacity and energy efficiency for neural network workloads, their application in Bayesian inference is limited. This is because the core operations in Bayesian inference differ significantly from the multiplication-accumulation (MAC) operations common in neural networks, rendering them generally unsuitable for direct implementation in most existing IMC designs. In this paper, we propose FeBiM, an efficient and compact Bayesian inference engine powered by multi-bit ferroelectric field-effect transistor (FeFET)-based IMC. FeBiM effectively encodes the trained probabilities of a Bayesian inference model within a compact FeFET-based crossbar. It maps quantized logarithmic probabilities to discrete FeFET states. As a result, the accumulated outputs of the crossbar naturally represent the posterior probabilities, i.e., the Bayesian inference model's output given a set of observations. This approach enables efficient in-memory Bayesian inference without the need for additional calculation circuitry. As the first FeFET-based in-memory Bayesian inference engine, FeBiM achieves an impressive storage density of 26.32 Mb/mm$^{2}$ and a computing efficiency of 581.40 TOPS/W in a representative Bayesian classification task. These results demonstrate 10.7$\times$/43.4$\times$ improvement in compactness/efficiency compared to the state-of-the-art hardware implementation of Bayesian inference.
A Remedy to Compute-in-Memory with Dynamic Random Access Memory: 1FeFET-1C Technology for Neuro-Symbolic AI
Oct 20, 2024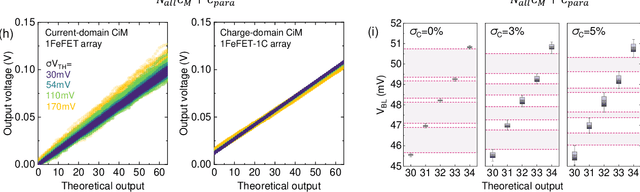
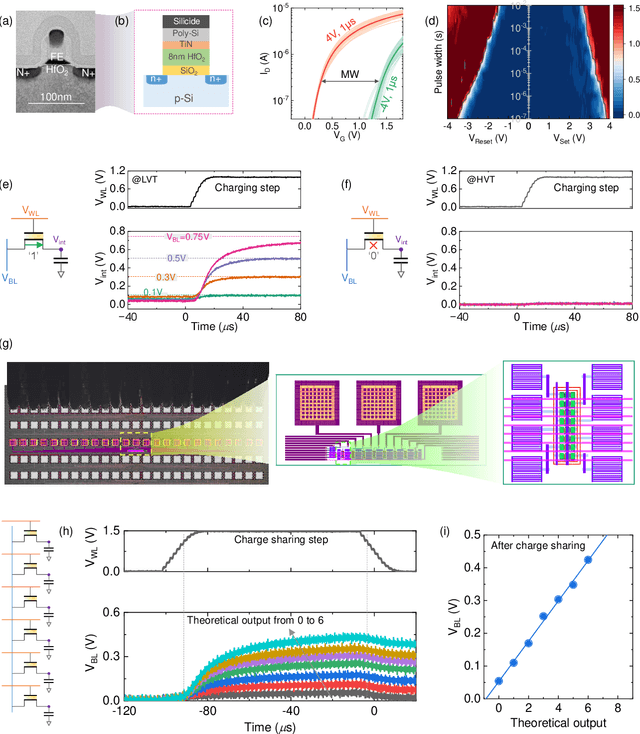
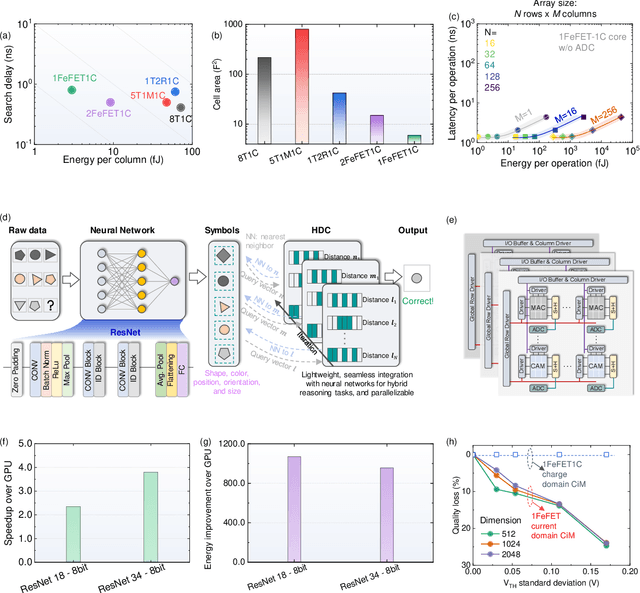
Neuro-symbolic artificial intelligence (AI) excels at learning from noisy and generalized patterns, conducting logical inferences, and providing interpretable reasoning. Comprising a 'neuro' component for feature extraction and a 'symbolic' component for decision-making, neuro-symbolic AI has yet to fully benefit from efficient hardware accelerators. Additionally, current hardware struggles to accommodate applications requiring dynamic resource allocation between these two components. To address these challenges-and mitigate the typical data-transfer bottleneck of classical Von Neumann architectures-we propose a ferroelectric charge-domain compute-in-memory (CiM) array as the foundational processing element for neuro-symbolic AI. This array seamlessly handles both the critical multiply-accumulate (MAC) operations of the 'neuro' workload and the parallel associative search operations of the 'symbolic' workload. To enable this approach, we introduce an innovative 1FeFET-1C cell, combining a ferroelectric field-effect transistor (FeFET) with a capacitor. This design, overcomes the destructive sensing limitations of DRAM in CiM applications, while capable of capitalizing decades of DRAM expertise with a similar cell structure as DRAM, achieves high immunity against FeFET variation-crucial for neuro-symbolic AI-and demonstrates superior energy efficiency. The functionalities of our design have been successfully validated through SPICE simulations and prototype fabrication and testing. Our hardware platform has been benchmarked in executing typical neuro-symbolic AI reasoning tasks, showing over 2x improvement in latency and 1000x improvement in energy efficiency compared to GPU-based implementations.
BasisN: Reprogramming-Free RRAM-Based In-Memory-Computing by Basis Combination for Deep Neural Networks
Jul 04, 2024Deep neural networks (DNNs) have made breakthroughs in various fields including image recognition and language processing. DNNs execute hundreds of millions of multiply-and-accumulate (MAC) operations. To efficiently accelerate such computations, analog in-memory-computing platforms have emerged leveraging emerging devices such as resistive RAM (RRAM). However, such accelerators face the hurdle of being required to have sufficient on-chip crossbars to hold all the weights of a DNN. Otherwise, RRAM cells in the crossbars need to be reprogramed to process further layers, which causes huge time/energy overhead due to the extremely slow writing and verification of the RRAM cells. As a result, it is still not possible to deploy such accelerators to process large-scale DNNs in industry. To address this problem, we propose the BasisN framework to accelerate DNNs on any number of available crossbars without reprogramming. BasisN introduces a novel representation of the kernels in DNN layers as combinations of global basis vectors shared between all layers with quantized coefficients. These basis vectors are written to crossbars only once and used for the computations of all layers with marginal hardware modification. BasisN also provides a novel training approach to enhance computation parallelization with the global basis vectors and optimize the coefficients to construct the kernels. Experimental results demonstrate that cycles per inference and energy-delay product were reduced to below 1% compared with applying reprogramming on crossbars in processing large-scale DNNs such as DenseNet and ResNet on ImageNet and CIFAR100 datasets, while the training and hardware costs are negligible.
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Jun 20, 2024



In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
EncodingNet: A Novel Encoding-based MAC Design for Efficient Neural Network Acceleration
Feb 25, 2024Deep neural networks (DNNs) have achieved great breakthroughs in many fields such as image classification and natural language processing. However, the execution of DNNs needs to conduct massive numbers of multiply-accumulate (MAC) operations on hardware and thus incurs a large power consumption. To address this challenge, we propose a novel digital MAC design based on encoding. In this new design, the multipliers are replaced by simple logic gates to project the results onto a wide bit representation. These bits carry individual position weights, which can be trained for specific neural networks to enhance inference accuracy. The outputs of the new multipliers are added by bit-wise weighted accumulation and the accumulation results are compatible with existing computing platforms accelerating neural networks with either uniform or non-uniform quantization. Since the multiplication function is replaced by simple logic projection, the critical paths in the resulting circuits become much shorter. Correspondingly, pipelining stages in the MAC array can be reduced, leading to a significantly smaller area as well as a better power efficiency. The proposed design has been synthesized and verified by ResNet18-Cifar10, ResNet20-Cifar100 and ResNet50-ImageNet. The experimental results confirmed the reduction of circuit area by up to 79.63% and the reduction of power consumption of executing DNNs by up to 70.18%, while the accuracy of the neural networks can still be well maintained.
Reconfigurable Frequency Multipliers Based on Complementary Ferroelectric Transistors
Dec 29, 2023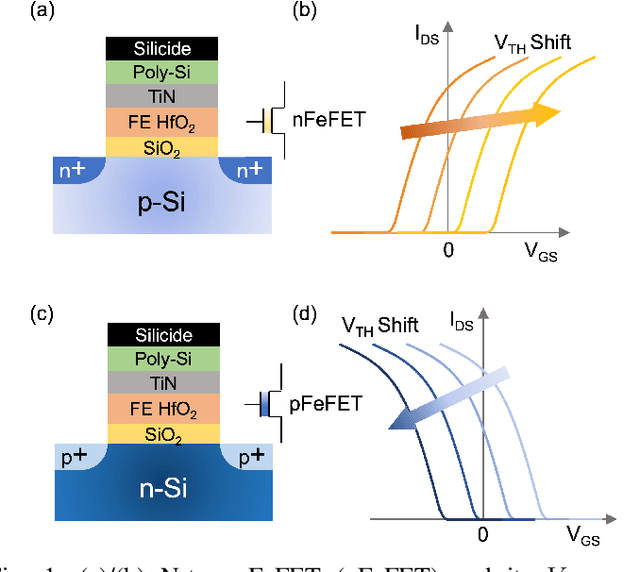
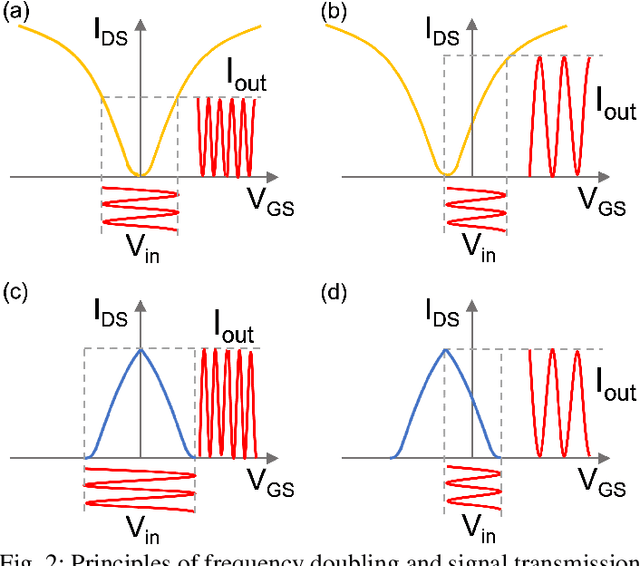
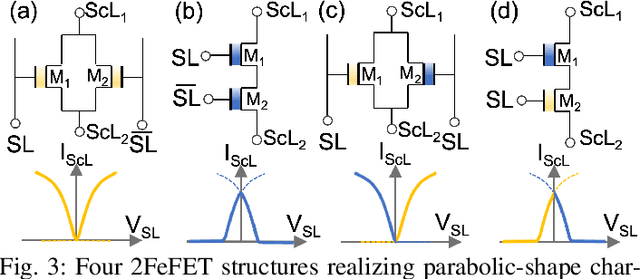
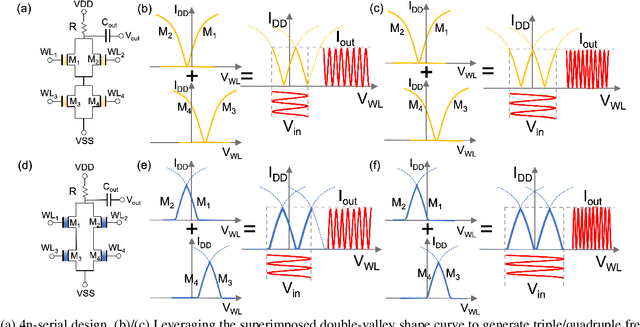
Frequency multipliers, a class of essential electronic components, play a pivotal role in contemporary signal processing and communication systems. They serve as crucial building blocks for generating high-frequency signals by multiplying the frequency of an input signal. However, traditional frequency multipliers that rely on nonlinear devices often require energy- and area-consuming filtering and amplification circuits, and emerging designs based on an ambipolar ferroelectric transistor require costly non-trivial characteristic tuning or complex technology process. In this paper, we show that a pair of standard ferroelectric field effect transistors (FeFETs) can be used to build compact frequency multipliers without aforementioned technology issues. By leveraging the tunable parabolic shape of the 2FeFET structures' transfer characteristics, we propose four reconfigurable frequency multipliers, which can switch between signal transmission and frequency doubling. Furthermore, based on the 2FeFET structures, we propose four frequency multipliers that realize triple, quadruple frequency modes, elucidating a scalable methodology to generate more multiplication harmonics of the input frequency. Performance metrics such as maximum operating frequency, power, etc., are evaluated and compared with existing works. We also implement a practical case of frequency modulation scheme based on the proposed reconfigurable multipliers without additional devices. Our work provides a novel path of scalable and reconfigurable frequency multiplier designs based on devices that have characteristics similar to FeFETs, and show that FeFETs are a promising candidate for signal processing and communication systems in terms of maximum operating frequency and power.
Class-Aware Pruning for Efficient Neural Networks
Dec 10, 2023



Deep neural networks (DNNs) have demonstrated remarkable success in various fields. However, the large number of floating-point operations (FLOPs) in DNNs poses challenges for their deployment in resource-constrained applications, e.g., edge devices. To address the problem, pruning has been introduced to reduce the computational cost in executing DNNs. Previous pruning strategies are based on weight values, gradient values and activation outputs. Different from previous pruning solutions, in this paper, we propose a class-aware pruning technique to compress DNNs, which provides a novel perspective to reduce the computational cost of DNNs. In each iteration, the neural network training is modified to facilitate the class-aware pruning. Afterwards, the importance of filters with respect to the number of classes is evaluated. The filters that are only important for a few number of classes are removed. The neural network is then retrained to compensate for the incurred accuracy loss. The pruning iterations end until no filter can be removed anymore, indicating that the remaining filters are very important for many classes. This pruning technique outperforms previous pruning solutions in terms of accuracy, pruning ratio and the reduction of FLOPs. Experimental results confirm that this class-aware pruning technique can significantly reduce the number of weights and FLOPs, while maintaining a high inference accuracy.