 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasis Sharing: Cross-Layer Parameter Sharing for Large Language Model Compression
Oct 02, 2024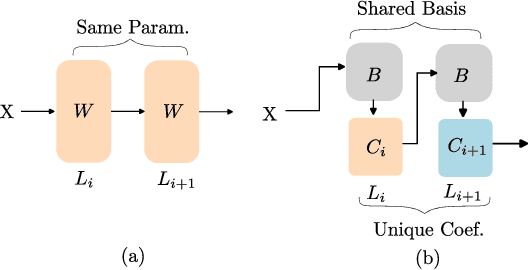
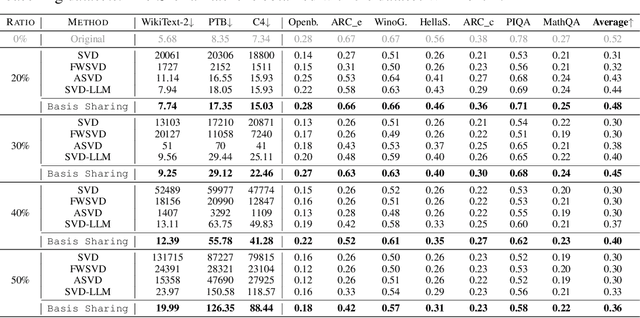
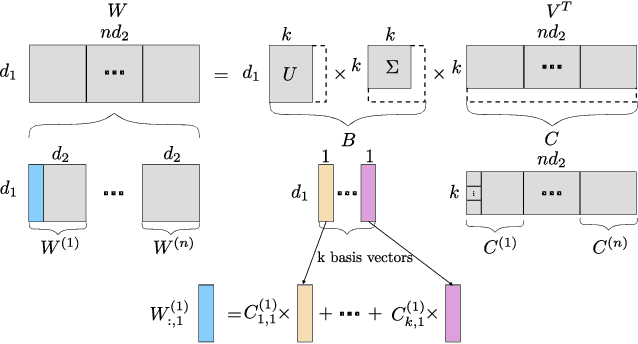

Large Language Models (LLMs) have achieved remarkable breakthroughs. However, the huge number of parameters in LLMs require significant amount of memory storage in inference, which prevents their practical deployment in many applications. To reduce memory storage of LLMs, singular value decomposition (SVD) provides a promising solution to approximate weight matrices for compressing LLMs. In this paper, we take a step further to explore parameter sharing across different layers with SVD to achieve more effective compression for LLMs. Specifically, weight matrices in different layers are decomposed and represented as a linear combination of a set of shared basis vectors and unique coefficients. The types of weight matrices and the layer selection for basis sharing are examined when compressing LLMs to maintain the performance. Comprehensive experiments demonstrate that Basis Sharing outperforms state-of-the-art SVD-based compression approaches and parameter sharing techniques, especially under large compression ratios. Code is available at: https://github.com/TUDa-HWAI/Basis_Sharing
BasisN: Reprogramming-Free RRAM-Based In-Memory-Computing by Basis Combination for Deep Neural Networks
Jul 04, 2024Deep neural networks (DNNs) have made breakthroughs in various fields including image recognition and language processing. DNNs execute hundreds of millions of multiply-and-accumulate (MAC) operations. To efficiently accelerate such computations, analog in-memory-computing platforms have emerged leveraging emerging devices such as resistive RAM (RRAM). However, such accelerators face the hurdle of being required to have sufficient on-chip crossbars to hold all the weights of a DNN. Otherwise, RRAM cells in the crossbars need to be reprogramed to process further layers, which causes huge time/energy overhead due to the extremely slow writing and verification of the RRAM cells. As a result, it is still not possible to deploy such accelerators to process large-scale DNNs in industry. To address this problem, we propose the BasisN framework to accelerate DNNs on any number of available crossbars without reprogramming. BasisN introduces a novel representation of the kernels in DNN layers as combinations of global basis vectors shared between all layers with quantized coefficients. These basis vectors are written to crossbars only once and used for the computations of all layers with marginal hardware modification. BasisN also provides a novel training approach to enhance computation parallelization with the global basis vectors and optimize the coefficients to construct the kernels. Experimental results demonstrate that cycles per inference and energy-delay product were reduced to below 1% compared with applying reprogramming on crossbars in processing large-scale DNNs such as DenseNet and ResNet on ImageNet and CIFAR100 datasets, while the training and hardware costs are negligible.
Class-Aware Pruning for Efficient Neural Networks
Dec 10, 2023



Deep neural networks (DNNs) have demonstrated remarkable success in various fields. However, the large number of floating-point operations (FLOPs) in DNNs poses challenges for their deployment in resource-constrained applications, e.g., edge devices. To address the problem, pruning has been introduced to reduce the computational cost in executing DNNs. Previous pruning strategies are based on weight values, gradient values and activation outputs. Different from previous pruning solutions, in this paper, we propose a class-aware pruning technique to compress DNNs, which provides a novel perspective to reduce the computational cost of DNNs. In each iteration, the neural network training is modified to facilitate the class-aware pruning. Afterwards, the importance of filters with respect to the number of classes is evaluated. The filters that are only important for a few number of classes are removed. The neural network is then retrained to compensate for the incurred accuracy loss. The pruning iterations end until no filter can be removed anymore, indicating that the remaining filters are very important for many classes. This pruning technique outperforms previous pruning solutions in terms of accuracy, pruning ratio and the reduction of FLOPs. Experimental results confirm that this class-aware pruning technique can significantly reduce the number of weights and FLOPs, while maintaining a high inference accuracy.
CIMulator: A Comprehensive Simulation Platform for Computing-In-Memory Circuit Macros with Low Bit-Width and Real Memory Materials
Jun 26, 2023



This paper presents a simulation platform, namely CIMulator, for quantifying the efficacy of various synaptic devices in neuromorphic accelerators for different neural network architectures. Nonvolatile memory devices, such as resistive random-access memory, ferroelectric field-effect transistor, and volatile static random-access memory devices, can be selected as synaptic devices. A multilayer perceptron and convolutional neural networks (CNNs), such as LeNet-5, VGG-16, and a custom CNN named C4W-1, are simulated to evaluate the effects of these synaptic devices on the training and inference outcomes. The dataset used in the simulations are MNIST, CIFAR-10, and a white blood cell dataset. By applying batch normalization and appropriate optimizers in the training phase, neuromorphic systems with very low-bit-width or binary weights could achieve high pattern recognition rates that approach software-based CNN accuracy. We also introduce spiking neural networks with RRAM-based synaptic devices for the recognition of MNIST handwritten digits.
Exploring Adversarial Examples for Efficient Active Learning in Machine Learning Classifiers
Sep 23, 2021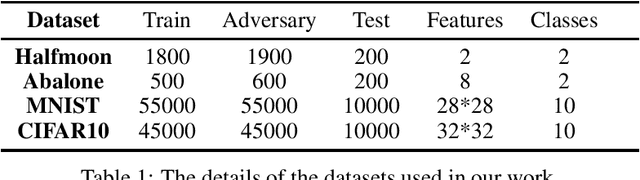


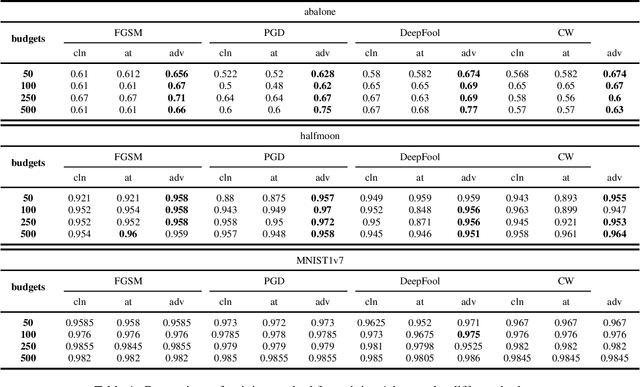
Machine learning researchers have long noticed the phenomenon that the model training process will be more effective and efficient when the training samples are densely sampled around the underlying decision boundary. While this observation has already been widely applied in a range of machine learning security techniques, it lacks theoretical analyses of the correctness of the observation. To address this challenge, we first add particular perturbation to original training examples using adversarial attack methods so that the generated examples could lie approximately on the decision boundary of the ML classifiers. We then investigate the connections between active learning and these particular training examples. Through analyzing various representative classifiers such as k-NN classifiers, kernel methods as well as deep neural networks, we establish a theoretical foundation for the observation. As a result, our theoretical proofs provide support to more efficient active learning methods with the help of adversarial examples, contrary to previous works where adversarial examples are often used as destructive solutions. Experimental results show that the established theoretical foundation will guide better active learning strategies based on adversarial examples.