 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Adversarial Examples for Efficient Active Learning in Machine Learning Classifiers
Paper and Code
Sep 23, 2021


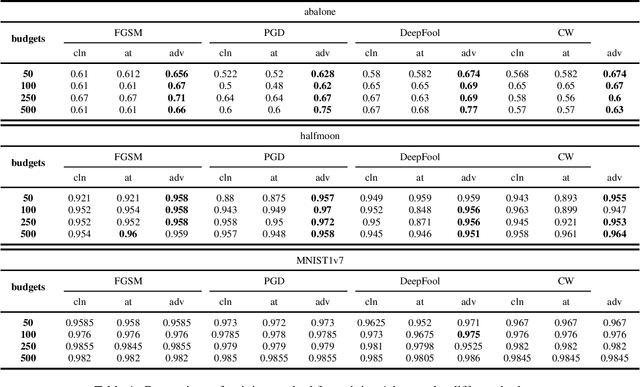
Machine learning researchers have long noticed the phenomenon that the model training process will be more effective and efficient when the training samples are densely sampled around the underlying decision boundary. While this observation has already been widely applied in a range of machine learning security techniques, it lacks theoretical analyses of the correctness of the observation. To address this challenge, we first add particular perturbation to original training examples using adversarial attack methods so that the generated examples could lie approximately on the decision boundary of the ML classifiers. We then investigate the connections between active learning and these particular training examples. Through analyzing various representative classifiers such as k-NN classifiers, kernel methods as well as deep neural networks, we establish a theoretical foundation for the observation. As a result, our theoretical proofs provide support to more efficient active learning methods with the help of adversarial examples, contrary to previous works where adversarial examples are often used as destructive solutions. Experimental results show that the established theoretical foundation will guide better active learning strategies based on adversarial examples.