 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressKV: Semantic-Retrieval-Guided KV-Cache Compression for Resource-Efficient Long-Context LLM Inference
Jun 23, 2026Long-context large language model (LLM) inference is increasingly constrained by the memory footprint and decoding cost of key-value (KV) caches, limiting sustainable deployment on resource-constrained hardware. Existing KV cache eviction methods typically apply heuristic token scoring over all heads in GQA-based LLMs. These methods ignore the different functionalities of attention heads, leading to the eviction of critical tokens and thus degrading the performance of LLMs. To address this issue, we propose CompressKV, a resource-efficient KV-cache compression framework for GQA-based LLMs. Instead of aggregating attention scores from all heads, CompressKV identifies Semantic Retrieval Heads (SRHs) that capture both the initial and final tokens of a prompt and semantically important mid-context evidence, and uses them to select tokens whose KV pairs should be retained. Furthermore, CompressKV allocates cache budgets across layers according to offline estimates of layer-wise eviction error. Experiments on LongBench and Needle-in-a-Haystack show that CompressKV consistently outperforms existing KV-cache eviction methods across memory budgets. Notably, it preserves over 97\% of full-cache performance using only 3\% of the KV cache on LongBench question-answering tasks and achieves 90\% accuracy with just 0.7\% KV storage on Needle-in-a-Haystack. These results demonstrate an improved resource--performance trade-off for long-context LLM inference. Our code is publicly available at: https://github.com/TUDa-HWAI/CompressKV
Basis Sharing: Cross-Layer Parameter Sharing for Large Language Model Compression
Oct 02, 2024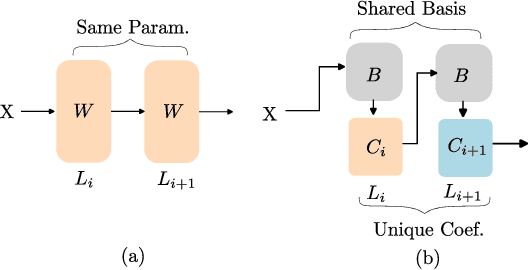
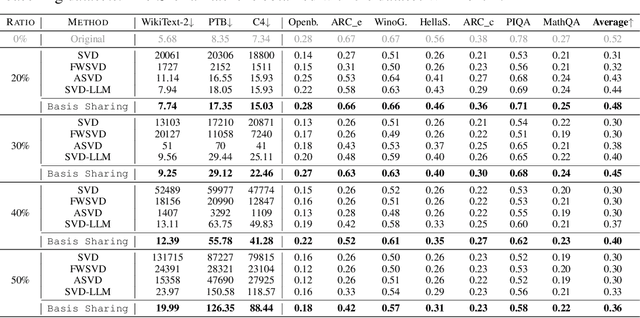
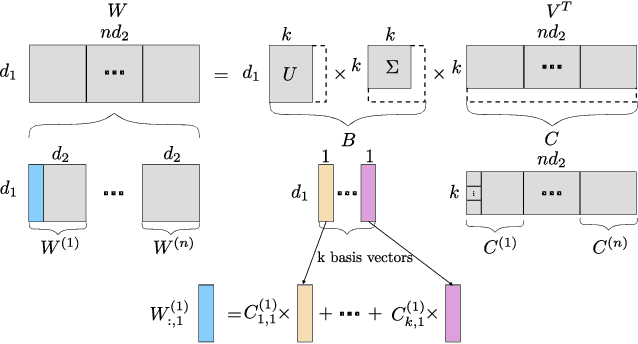

Large Language Models (LLMs) have achieved remarkable breakthroughs. However, the huge number of parameters in LLMs require significant amount of memory storage in inference, which prevents their practical deployment in many applications. To reduce memory storage of LLMs, singular value decomposition (SVD) provides a promising solution to approximate weight matrices for compressing LLMs. In this paper, we take a step further to explore parameter sharing across different layers with SVD to achieve more effective compression for LLMs. Specifically, weight matrices in different layers are decomposed and represented as a linear combination of a set of shared basis vectors and unique coefficients. The types of weight matrices and the layer selection for basis sharing are examined when compressing LLMs to maintain the performance. Comprehensive experiments demonstrate that Basis Sharing outperforms state-of-the-art SVD-based compression approaches and parameter sharing techniques, especially under large compression ratios. Code is available at: https://github.com/TUDa-HWAI/Basis_Sharing
Class-Aware Pruning for Efficient Neural Networks
Dec 10, 2023



Deep neural networks (DNNs) have demonstrated remarkable success in various fields. However, the large number of floating-point operations (FLOPs) in DNNs poses challenges for their deployment in resource-constrained applications, e.g., edge devices. To address the problem, pruning has been introduced to reduce the computational cost in executing DNNs. Previous pruning strategies are based on weight values, gradient values and activation outputs. Different from previous pruning solutions, in this paper, we propose a class-aware pruning technique to compress DNNs, which provides a novel perspective to reduce the computational cost of DNNs. In each iteration, the neural network training is modified to facilitate the class-aware pruning. Afterwards, the importance of filters with respect to the number of classes is evaluated. The filters that are only important for a few number of classes are removed. The neural network is then retrained to compensate for the incurred accuracy loss. The pruning iterations end until no filter can be removed anymore, indicating that the remaining filters are very important for many classes. This pruning technique outperforms previous pruning solutions in terms of accuracy, pruning ratio and the reduction of FLOPs. Experimental results confirm that this class-aware pruning technique can significantly reduce the number of weights and FLOPs, while maintaining a high inference accuracy.
Early Classification for Dynamic Inference of Neural Networks
Sep 23, 2023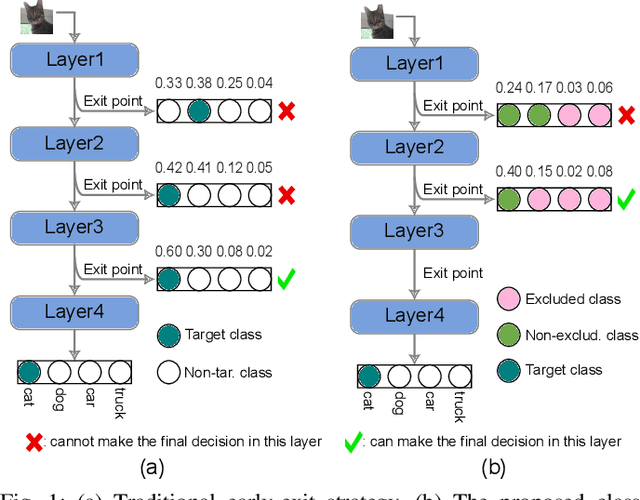
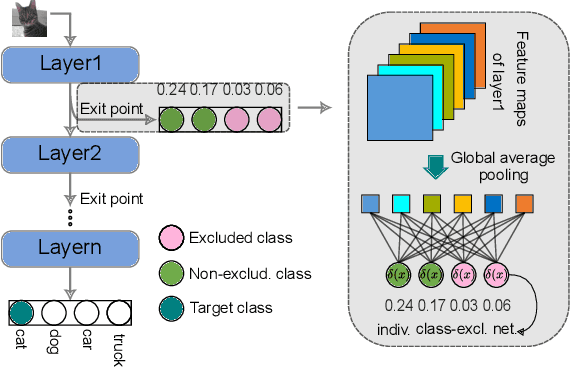
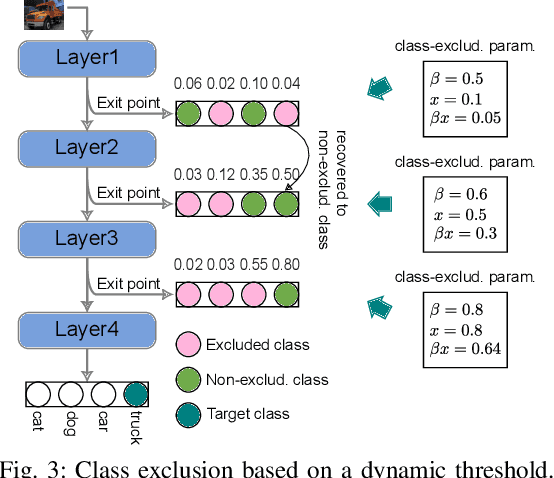
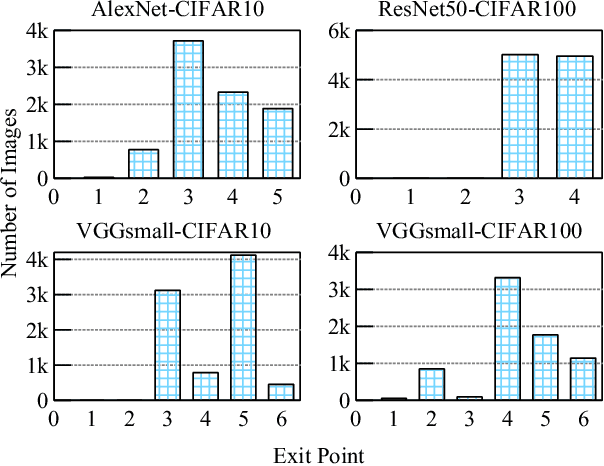
Deep neural networks (DNNs) have been successfully applied in various fields. In DNNs, a large number of multiply-accumulate (MAC) operations is required to be performed, posing critical challenges in applying them in resource-constrained platforms, e.g., edge devices. Dynamic neural networks have been introduced to allow a structural adaption, e.g., early-exit, according to different inputs to reduce the computational cost of DNNs. Existing early-exit techniques deploy classifiers at intermediate layers of DNNs to push them to make a classification decision as early as possible. However, the learned features at early layers might not be sufficient to exclude all the irrelevant classes and decide the correct class, leading to suboptimal results. To address this challenge, in this paper, we propose a class-based early-exit for dynamic inference. Instead of pushing DNNs to make a dynamic decision at intermediate layers, we take advantages of the learned features in these layers to exclude as many irrelevant classes as possible, so that later layers only have to determine the target class among the remaining classes. Until at a layer only one class remains, this class is the corresponding classification result. To realize this class-based exclusion, we assign each class with a classifier at intermediate layers and train the networks together with these classifiers. Afterwards, an exclusion strategy is developed to exclude irrelevant classes at early layers. Experimental results demonstrate the computational cost of DNNs in inference can be reduced significantly.