 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasisN: Reprogramming-Free RRAM-Based In-Memory-Computing by Basis Combination for Deep Neural Networks
Jul 04, 2024Deep neural networks (DNNs) have made breakthroughs in various fields including image recognition and language processing. DNNs execute hundreds of millions of multiply-and-accumulate (MAC) operations. To efficiently accelerate such computations, analog in-memory-computing platforms have emerged leveraging emerging devices such as resistive RAM (RRAM). However, such accelerators face the hurdle of being required to have sufficient on-chip crossbars to hold all the weights of a DNN. Otherwise, RRAM cells in the crossbars need to be reprogramed to process further layers, which causes huge time/energy overhead due to the extremely slow writing and verification of the RRAM cells. As a result, it is still not possible to deploy such accelerators to process large-scale DNNs in industry. To address this problem, we propose the BasisN framework to accelerate DNNs on any number of available crossbars without reprogramming. BasisN introduces a novel representation of the kernels in DNN layers as combinations of global basis vectors shared between all layers with quantized coefficients. These basis vectors are written to crossbars only once and used for the computations of all layers with marginal hardware modification. BasisN also provides a novel training approach to enhance computation parallelization with the global basis vectors and optimize the coefficients to construct the kernels. Experimental results demonstrate that cycles per inference and energy-delay product were reduced to below 1% compared with applying reprogramming on crossbars in processing large-scale DNNs such as DenseNet and ResNet on ImageNet and CIFAR100 datasets, while the training and hardware costs are negligible.
Class-Aware Pruning for Efficient Neural Networks
Dec 10, 2023



Deep neural networks (DNNs) have demonstrated remarkable success in various fields. However, the large number of floating-point operations (FLOPs) in DNNs poses challenges for their deployment in resource-constrained applications, e.g., edge devices. To address the problem, pruning has been introduced to reduce the computational cost in executing DNNs. Previous pruning strategies are based on weight values, gradient values and activation outputs. Different from previous pruning solutions, in this paper, we propose a class-aware pruning technique to compress DNNs, which provides a novel perspective to reduce the computational cost of DNNs. In each iteration, the neural network training is modified to facilitate the class-aware pruning. Afterwards, the importance of filters with respect to the number of classes is evaluated. The filters that are only important for a few number of classes are removed. The neural network is then retrained to compensate for the incurred accuracy loss. The pruning iterations end until no filter can be removed anymore, indicating that the remaining filters are very important for many classes. This pruning technique outperforms previous pruning solutions in terms of accuracy, pruning ratio and the reduction of FLOPs. Experimental results confirm that this class-aware pruning technique can significantly reduce the number of weights and FLOPs, while maintaining a high inference accuracy.
Analog Feedback-Controlled Memristor programming Circuit for analog Content Addressable Memory
Apr 21, 2023Recent breakthroughs in associative memories suggest that silicon memories are coming closer to human memories, especially for memristive Content Addressable Memories (CAMs) which are capable to read and write in analog values. However, the Program-Verify algorithm, the state-of-the-art memristor programming algorithm, requires frequent switching between verifying and programming memristor conductance, which brings many defects such as high dynamic power and long programming time. Here, we propose an analog feedback-controlled memristor programming circuit that makes use of a novel look-up table-based (LUT-based) programming algorithm. With the proposed algorithm, the programming and the verification of a memristor can be performed in a single-direction sequential process. Besides, we also integrated a single proposed programming circuit with eight analog CAM (aCAM) cells to build an aCAM array. We present SPICE simulations on TSMC 28nm process. The theoretical analysis shows that 1. A memristor conductance within an aCAM cell can be converted to an output boundary voltage in aCAM searching operations and 2. An output boundary voltage in aCAM searching operations can be converted to a programming data line voltage in aCAM programming operations. The simulation results of the proposed programming circuit prove the theoretical analysis and thus verify the feasibility to program memristors without frequently switching between verifying and programming the conductance. Besides, the simulation results of the proposed aCAM array show that the proposed programming circuit can be integrated into a large array architecture.
CorrectNet: Robustness Enhancement of Analog In-Memory Computing for Neural Networks by Error Suppression and Compensation
Nov 27, 2022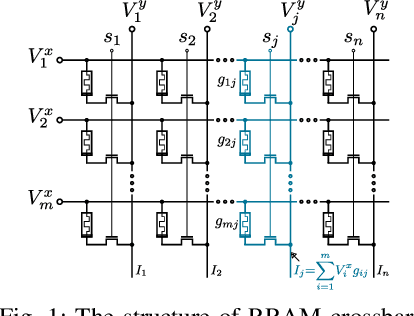
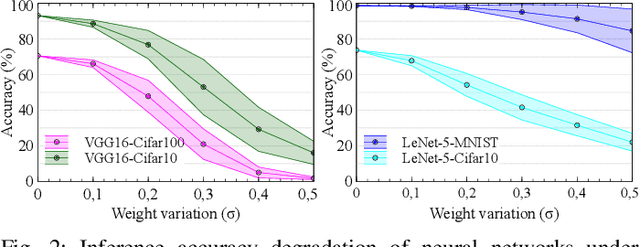
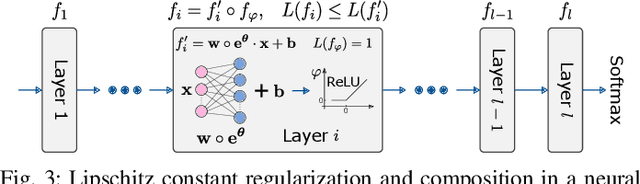
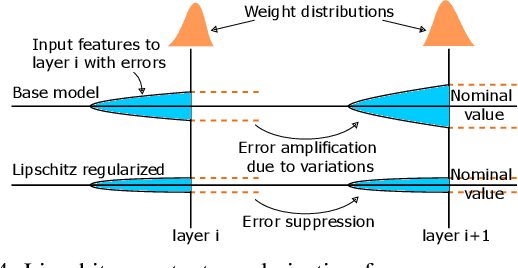
The last decade has witnessed the breakthrough of deep neural networks (DNNs) in many fields. With the increasing depth of DNNs, hundreds of millions of multiply-and-accumulate (MAC) operations need to be executed. To accelerate such operations efficiently, analog in-memory computing platforms based on emerging devices, e.g., resistive RAM (RRAM), have been introduced. These acceleration platforms rely on analog properties of the devices and thus suffer from process variations and noise. Consequently, weights in neural networks configured into these platforms can deviate from the expected values, which may lead to feature errors and a significant degradation of inference accuracy. To address this issue, in this paper, we propose a framework to enhance the robustness of neural networks under variations and noise. First, a modified Lipschitz constant regularization is proposed during neural network training to suppress the amplification of errors propagated through network layers. Afterwards, error compensation is introduced at necessary locations determined by reinforcement learning to rescue the feature maps with remaining errors. Experimental results demonstrate that inference accuracy of neural networks can be recovered from as low as 1.69% under variations and noise back to more than 95% of their original accuracy, while the training and hardware cost are negligible.