 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Interaction: Training-Free Inference Acceleration for Interactive Video World Models
May 29, 2026Interactive video world models generate video chunk by chunk in response to user-controlled camera movements, enabling applications such as real-time game simulation, virtual scene navigation, and embodied AI training. However, scaling to long interactive trajectories is prohibitively expensive due to growing context memory, quadratic attention complexity, and repeated denoising steps. We present Light Interaction, a training-free inference acceleration framework for interactive video world models. Our key insight is that interaction naturally enables trajectory-dependent adaptive computation: retrieved spatial memory can be discarded during novel exploration, temporal context can be adjusted according to local latent dynamics, and early-step model outputs can be reused when the camera revisits familiar regions. Based on this insight, Light Interaction combines adaptive context management, denoising cache acceleration, and hardware-software co-designed 3D block sparse attention with fused Triton kernels. Evaluated on HY-WorldPlay and Matrix-Game-3.0, Light Interaction achieves up to 2.59x speedup without model retraining while maintaining competitive visual quality.
KV Packet: Recomputation-Free Context-Independent KV Caching for LLMs
Apr 14, 2026Large Language Models (LLMs) rely heavily on Key-Value (KV) caching to minimize inference latency. However, standard KV caches are context-dependent: reusing a cached document in a new context requires recomputing KV states to account for shifts in attention distribution. Existing solutions such as CacheBlend, EPIC, and SAM-KV mitigate this issue by selectively recomputing a subset of tokens; however, they still incur non-negligible computational overhead (FLOPs) and increased Time-to-First-Token (TTFT) latency. In this paper, we propose KV Packet, a recomputation-free cache reuse framework that treats cached documents as immutable ``packets'' wrapped in light-weight trainable soft-token adapters, which are trained via self-supervised distillation to bridge context discontinuities. Experiments on Llama-3.1 and Qwen2.5 demonstrate that the proposed KV Packet method achieves near-zero FLOPs and lower TTFT than recomputation-based baselines, while retaining F1 scores comparable to those of the full recomputation baseline.
ScoRe-Flow: Complete Distributional Control via Score-Based Reinforcement Learning for Flow Matching
Apr 13, 2026Flow Matching (FM) policies have emerged as an efficient backbone for robotic control, offering fast and expressive action generation that underpins recent large-scale embodied AI systems. However, FM policies trained via imitation learning inherit the limitations of demonstration data; surpassing suboptimal behaviors requires reinforcement learning (RL) fine-tuning. Recent methods convert deterministic flows into stochastic differential equations (SDEs) with learnable noise injection, enabling exploration and tractable likelihoods, but such noise-only control can compromise training efficiency when demonstrations already provide strong priors. We observe that modulating the drift via the score function, i.e., the gradient of log-density, steers exploration toward high-probability regions, improving stability. The score admits a closed-form expression from the velocity field, requiring no auxiliary networks. Based on this, we propose ScoRe-Flow, a score-based RL fine-tuning method that combines drift modulation with learned variance prediction to achieve decoupled control over the mean and variance of stochastic transitions. Experiments demonstrate that ScoRe-Flow achieves 2.4x faster convergence than flow-based SOTA on D4RL locomotion tasks and up to 5.4% higher success rates on Robomimic and Franka Kitchen manipulation tasks.
FluxEDA: A Unified Execution Infrastructure for Stateful Agentic EDA
Mar 26, 2026Large language models and autonomous agents are increasingly explored for EDA automation, but many existing integrations still rely on script-level or request-level interactions, which makes it difficult to preserve tool state and support iterative optimization in real production-oriented environments. In this work, we present FluxEDA, a unified and stateful infrastructure substrate for agentic EDA. FluxEDA introduces a managed gateway-based execution interface with structured request and response handling. It also maintains persistent backend instances. Together, these features allow upper-layer agents and programmable clients to interact with heterogeneous EDA tools through preserved runtime state, rather than through isolated shell invocations. We evaluate the framework using two representative commercial backend case studies: automated post-route timing ECO and standard-cell sub-library optimization. The results show that FluxEDA can support multi-step analysis and optimization over real tool contexts, including state reuse, rollback, and coordinated iterative execution. These findings suggest that a stateful and governed infrastructure layer is a practical foundation for agent-assisted EDA automation.
Unitho: A Unified Multi-Task Framework for Computational Lithography
Nov 14, 2025Reliable, generalizable data foundations are critical for enabling large-scale models in computational lithography. However, essential tasks-mask generation, rule violation detection, and layout optimization-are often handled in isolation, hindered by scarce datasets and limited modeling approaches. To address these challenges, we introduce Unitho, a unified multi-task large vision model built upon the Transformer architecture. Trained on a large-scale industrial lithography simulation dataset with hundreds of thousands of cases, Unitho supports end-to-end mask generation, lithography simulation, and rule violation detection. By enabling agile and high-fidelity lithography simulation, Unitho further facilitates the construction of robust data foundations for intelligent EDA. Experimental results validate its effectiveness and generalizability, with performance substantially surpassing academic baselines.
FactorHD: A Hyperdimensional Computing Model for Multi-Object Multi-Class Representation and Factorization
Jul 16, 2025Neuro-symbolic artificial intelligence (neuro-symbolic AI) excels in logical analysis and reasoning. Hyperdimensional Computing (HDC), a promising brain-inspired computational model, is integral to neuro-symbolic AI. Various HDC models have been proposed to represent class-instance and class-class relations, but when representing the more complex class-subclass relation, where multiple objects associate different levels of classes and subclasses, they face challenges for factorization, a crucial task for neuro-symbolic AI systems. In this article, we propose FactorHD, a novel HDC model capable of representing and factorizing the complex class-subclass relation efficiently. FactorHD features a symbolic encoding method that embeds an extra memorization clause, preserving more information for multiple objects. In addition, it employs an efficient factorization algorithm that selectively eliminates redundant classes by identifying the memorization clause of the target class. Such model significantly enhances computing efficiency and accuracy in representing and factorizing multiple objects with class-subclass relation, overcoming limitations of existing HDC models such as "superposition catastrophe" and "the problem of 2". Evaluations show that FactorHD achieves approximately 5667x speedup at a representation size of 10^9 compared to existing HDC models. When integrated with the ResNet-18 neural network, FactorHD achieves 92.48% factorization accuracy on the Cifar-10 dataset.
SafeMVDrive: Multi-view Safety-Critical Driving Video Synthesis in the Real World Domain
May 23, 2025



Safety-critical scenarios are rare yet pivotal for evaluating and enhancing the robustness of autonomous driving systems. While existing methods generate safety-critical driving trajectories, simulations, or single-view videos, they fall short of meeting the demands of advanced end-to-end autonomous systems (E2E AD), which require real-world, multi-view video data. To bridge this gap, we introduce SafeMVDrive, the first framework designed to generate high-quality, safety-critical, multi-view driving videos grounded in real-world domains. SafeMVDrive strategically integrates a safety-critical trajectory generator with an advanced multi-view video generator. To tackle the challenges inherent in this integration, we first enhance scene understanding ability of the trajectory generator by incorporating visual context -- which is previously unavailable to such generator -- and leveraging a GRPO-finetuned vision-language model to achieve more realistic and context-aware trajectory generation. Second, recognizing that existing multi-view video generators struggle to render realistic collision events, we introduce a two-stage, controllable trajectory generation mechanism that produces collision-evasion trajectories, ensuring both video quality and safety-critical fidelity. Finally, we employ a diffusion-based multi-view video generator to synthesize high-quality safety-critical driving videos from the generated trajectories. Experiments conducted on an E2E AD planner demonstrate a significant increase in collision rate when tested with our generated data, validating the effectiveness of SafeMVDrive in stress-testing planning modules. Our code, examples, and datasets are publicly available at: https://zhoujiawei3.github.io/SafeMVDrive/.
LiTformer: Efficient Modeling and Analysis of High-Speed Link Transmitters Using Non-Autoregressive Transformer
Nov 18, 2024



High-speed serial links are fundamental to energy-efficient and high-performance computing systems such as artificial intelligence, 5G mobile and automotive, enabling low-latency and high-bandwidth communication. Transmitters (TXs) within these links are key to signal quality, while their modeling presents challenges due to nonlinear behavior and dynamic interactions with links. In this paper, we propose LiTformer: a Transformer-based model for high-speed link TXs, with a non-sequential encoder and a Transformer decoder to incorporate link parameters and capture long-range dependencies of output signals. We employ a non-autoregressive mechanism in model training and inference for parallel prediction of the signal sequence. LiTformer achieves precise TX modeling considering link impacts including crosstalk from multiple links, and provides fast prediction for various long-sequence signals with high data rates. Experimental results show that LiTformer achieves 148-456$\times$ speedup for 2-link TXs and 404-944$\times$ speedup for 16-link with mean relative errors of 0.68-1.25%, supporting 4-bit signals at Gbps data rates of single-ended and differential TXs, as well as PAM4 TXs.
A Remedy to Compute-in-Memory with Dynamic Random Access Memory: 1FeFET-1C Technology for Neuro-Symbolic AI
Oct 20, 2024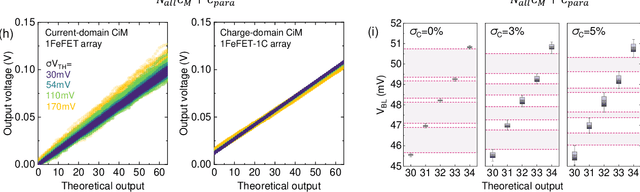
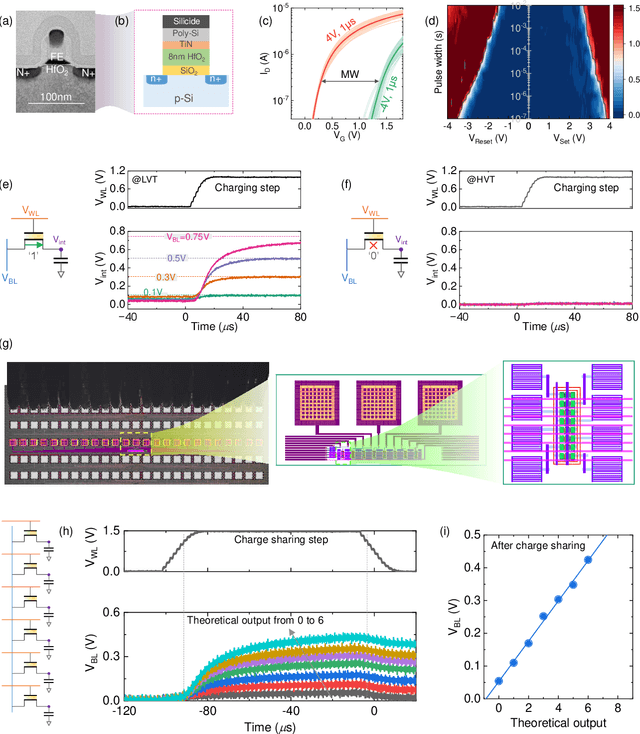
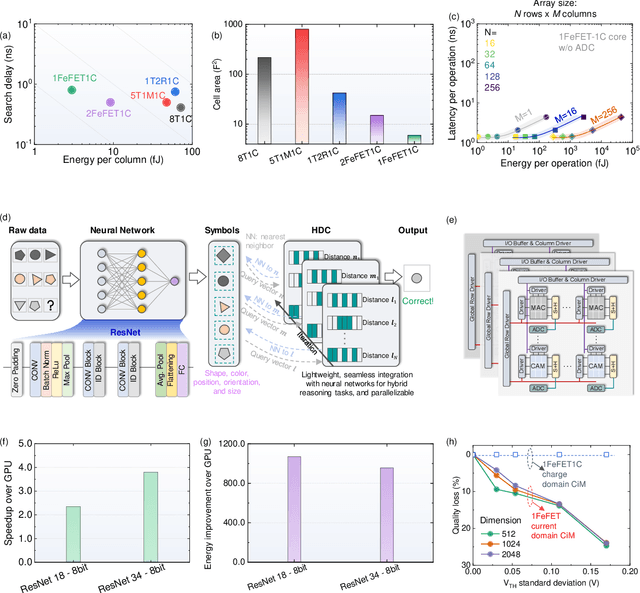
Neuro-symbolic artificial intelligence (AI) excels at learning from noisy and generalized patterns, conducting logical inferences, and providing interpretable reasoning. Comprising a 'neuro' component for feature extraction and a 'symbolic' component for decision-making, neuro-symbolic AI has yet to fully benefit from efficient hardware accelerators. Additionally, current hardware struggles to accommodate applications requiring dynamic resource allocation between these two components. To address these challenges-and mitigate the typical data-transfer bottleneck of classical Von Neumann architectures-we propose a ferroelectric charge-domain compute-in-memory (CiM) array as the foundational processing element for neuro-symbolic AI. This array seamlessly handles both the critical multiply-accumulate (MAC) operations of the 'neuro' workload and the parallel associative search operations of the 'symbolic' workload. To enable this approach, we introduce an innovative 1FeFET-1C cell, combining a ferroelectric field-effect transistor (FeFET) with a capacitor. This design, overcomes the destructive sensing limitations of DRAM in CiM applications, while capable of capitalizing decades of DRAM expertise with a similar cell structure as DRAM, achieves high immunity against FeFET variation-crucial for neuro-symbolic AI-and demonstrates superior energy efficiency. The functionalities of our design have been successfully validated through SPICE simulations and prototype fabrication and testing. Our hardware platform has been benchmarked in executing typical neuro-symbolic AI reasoning tasks, showing over 2x improvement in latency and 1000x improvement in energy efficiency compared to GPU-based implementations.
FabGPT: An Efficient Large Multimodal Model for Complex Wafer Defect Knowledge Queries
Jul 15, 2024



Intelligence is key to advancing integrated circuit (IC) fabrication. Recent breakthroughs in Large Multimodal Models (LMMs) have unlocked unparalleled abilities in understanding images and text, fostering intelligent fabrication. Leveraging the power of LMMs, we introduce FabGPT, a customized IC fabrication large multimodal model for wafer defect knowledge query. FabGPT manifests expertise in conducting defect detection in Scanning Electron Microscope (SEM) images, performing root cause analysis, and providing expert question-answering (Q&A) on fabrication processes. FabGPT matches enhanced multimodal features to automatically detect minute defects under complex wafer backgrounds and reduce the subjectivity of manual threshold settings. Besides, the proposed modulation module and interactive corpus training strategy embed wafer defect knowledge into the pre-trained model, effectively balancing Q&A queries related to defect knowledge and original knowledge and mitigating the modality bias issues. Experiments on in-house fab data (SEM-WaD) show that our FabGPT achieves significant performance improvement in wafer defect detection and knowledge querying.