 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiTformer: Efficient Modeling and Analysis of High-Speed Link Transmitters Using Non-Autoregressive Transformer
Nov 18, 2024



High-speed serial links are fundamental to energy-efficient and high-performance computing systems such as artificial intelligence, 5G mobile and automotive, enabling low-latency and high-bandwidth communication. Transmitters (TXs) within these links are key to signal quality, while their modeling presents challenges due to nonlinear behavior and dynamic interactions with links. In this paper, we propose LiTformer: a Transformer-based model for high-speed link TXs, with a non-sequential encoder and a Transformer decoder to incorporate link parameters and capture long-range dependencies of output signals. We employ a non-autoregressive mechanism in model training and inference for parallel prediction of the signal sequence. LiTformer achieves precise TX modeling considering link impacts including crosstalk from multiple links, and provides fast prediction for various long-sequence signals with high data rates. Experimental results show that LiTformer achieves 148-456$\times$ speedup for 2-link TXs and 404-944$\times$ speedup for 16-link with mean relative errors of 0.68-1.25%, supporting 4-bit signals at Gbps data rates of single-ended and differential TXs, as well as PAM4 TXs.
Virtual histological staining of unlabeled autopsy tissue
Aug 02, 2023Histological examination is a crucial step in an autopsy; however, the traditional histochemical staining of post-mortem samples faces multiple challenges, including the inferior staining quality due to autolysis caused by delayed fixation of cadaver tissue, as well as the resource-intensive nature of chemical staining procedures covering large tissue areas, which demand substantial labor, cost, and time. These challenges can become more pronounced during global health crises when the availability of histopathology services is limited, resulting in further delays in tissue fixation and more severe staining artifacts. Here, we report the first demonstration of virtual staining of autopsy tissue and show that a trained neural network can rapidly transform autofluorescence images of label-free autopsy tissue sections into brightfield equivalent images that match hematoxylin and eosin (H&E) stained versions of the same samples, eliminating autolysis-induced severe staining artifacts inherent in traditional histochemical staining of autopsied tissue. Our virtual H&E model was trained using >0.7 TB of image data and a data-efficient collaboration scheme that integrates the virtual staining network with an image registration network. The trained model effectively accentuated nuclear, cytoplasmic and extracellular features in new autopsy tissue samples that experienced severe autolysis, such as COVID-19 samples never seen before, where the traditional histochemical staining failed to provide consistent staining quality. This virtual autopsy staining technique can also be extended to necrotic tissue, and can rapidly and cost-effectively generate artifact-free H&E stains despite severe autolysis and cell death, also reducing labor, cost and infrastructure requirements associated with the standard histochemical staining.
Unidirectional Imaging using Deep Learning-Designed Materials
Dec 05, 2022A unidirectional imager would only permit image formation along one direction, from an input field-of-view (FOV) A to an output FOV B, and in the reverse path, the image formation would be blocked. Here, we report the first demonstration of unidirectional imagers, presenting polarization-insensitive and broadband unidirectional imaging based on successive diffractive layers that are linear and isotropic. These diffractive layers are optimized using deep learning and consist of hundreds of thousands of diffractive phase features, which collectively modulate the incoming fields and project an intensity image of the input onto an output FOV, while blocking the image formation in the reverse direction. After their deep learning-based training, the resulting diffractive layers are fabricated to form a unidirectional imager. As a reciprocal device, the diffractive unidirectional imager has asymmetric mode processing capabilities in the forward and backward directions, where the optical modes from B to A are selectively guided/scattered to miss the output FOV, whereas for the forward direction such modal losses are minimized, yielding an ideal imaging system between the input and output FOVs. Although trained using monochromatic illumination, the diffractive unidirectional imager maintains its functionality over a large spectral band and works under broadband illumination. We experimentally validated this unidirectional imager using terahertz radiation, very well matching our numerical results. Using the same deep learning-based design strategy, we also created a wavelength-selective unidirectional imager, where two unidirectional imaging operations, in reverse directions, are multiplexed through different illumination wavelengths. Diffractive unidirectional imaging using structured materials will have numerous applications in e.g., security, defense, telecommunications and privacy protection.
Hybrid Robotic Grasping with a Soft Multimodal Gripper and a Deep Multistage Learning Scheme
Feb 28, 2022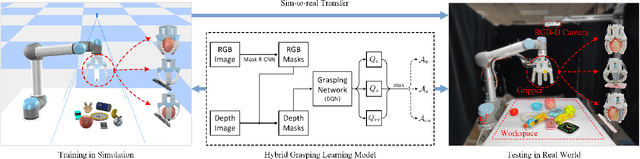
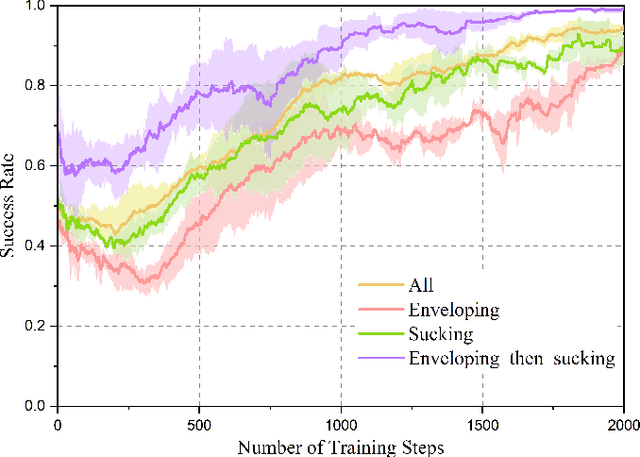
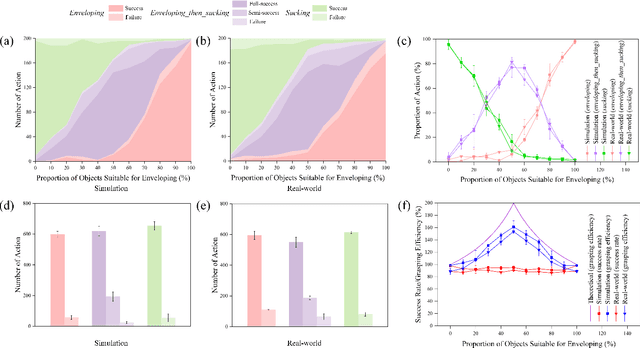
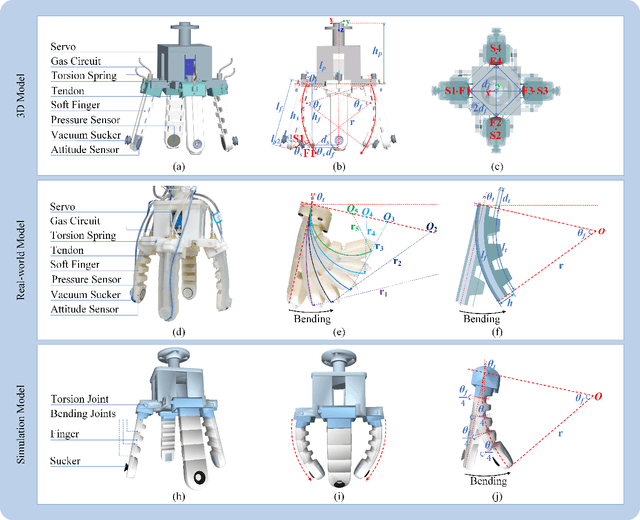
Grasping has long been considered an important and practical task in robotic manipulation. Yet achieving robust and efficient grasps of diverse objects is challenging, since it involves gripper design, perception, control and learning, etc. Recent learning-based approaches have shown excellent performance in grasping a variety of novel objects. However, these methods either are typically limited to one single grasping mode, or else more end effectors are needed to grasp various objects. In addition, gripper design and learning methods are commonly developed separately, which may not adequately explore the ability of a multimodal gripper. In this paper, we present a deep reinforcement learning (DRL) framework to achieve multistage hybrid robotic grasping with a new soft multimodal gripper. A soft gripper with three grasping modes (i.e., \textit{enveloping}, \textit{sucking}, and \textit{enveloping\_then\_sucking}) can both deal with objects of different shapes and grasp more than one object simultaneously. We propose a novel hybrid grasping method integrated with the multimodal gripper to optimize the number of grasping actions. We evaluate the DRL framework under different scenarios (i.e., with different ratios of objects of two grasp types). The proposed algorithm is shown to reduce the number of grasping actions (i.e., enlarge the grasping efficiency, with maximum values of 161\% in simulations and 154\% in real-world experiments) compared to single grasping modes.