 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Automatic Chord Recognition via Pseudo-Labeling and Knowledge Distillation
Feb 23, 2026Automatic Chord Recognition (ACR) is constrained by the scarcity of aligned chord labels, as well-aligned annotations are costly to acquire. At the same time, open-weight pre-trained models are currently more accessible than their proprietary training data. In this work, we present a two-stage training pipeline that leverages pre-trained models together with unlabeled audio. The proposed method decouples training into two stages. In the first stage, we use a pre-trained BTC model as a teacher to generate pseudo-labels for over 1,000 hours of diverse unlabeled audio and train a student model solely on these pseudo-labels. In the second stage, the student is continually trained on ground-truth labels as they become available, with selective knowledge distillation (KD) from the teacher applied as a regularizer to prevent catastrophic forgetting of the representations learned in the first stage. In our experiments, two models (BTC, 2E1D) were used as students. In stage 1, using only pseudo-labels, the BTC student achieves over 98% of the teacher's performance, while the 2E1D model achieves about 96% across seven standard mir_eval metrics. After a single training run for both students in stage 2, the resulting BTC student model surpasses the traditional supervised learning baseline by 2.5% and the original pre-trained teacher model by 1.55% on average across all metrics. And the resulting 2E1D student model improves from the traditional supervised learning baseline by 3.79% on average and achieves almost the same performance as the teacher. Both cases show the large gains on rare chord qualities.
TransMamba: Fast Universal Architecture Adaption from Transformers to Mamba
Feb 21, 2025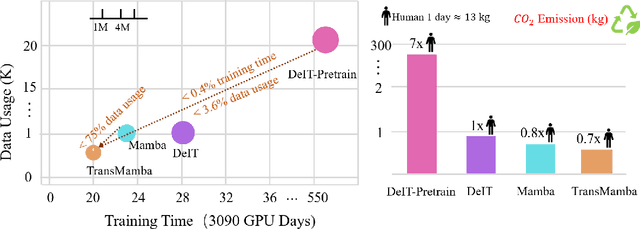
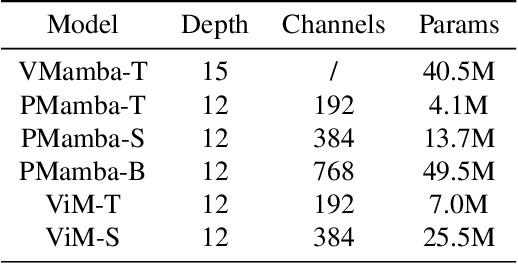
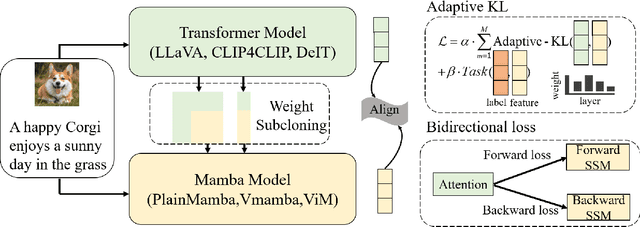
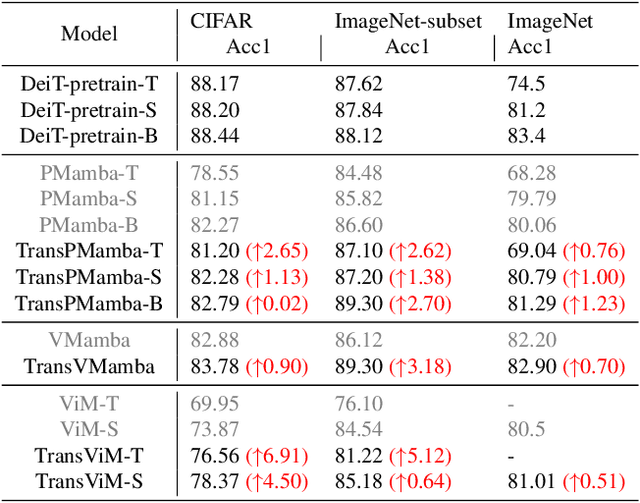
Transformers have been favored in both uni-modal and multi-modal foundation models for their flexible scalability in attention modules. Consequently, a number of pre-trained Transformer models, e.g., LLaVA, CLIP, and DEIT, are publicly available. Recent research has introduced subquadratic architectures like Mamba, which enables global awareness with linear complexity. Nevertheless, training specialized subquadratic architectures from scratch for certain tasks is both resource-intensive and time-consuming. As a motivator, we explore cross-architecture training to transfer the ready knowledge in existing Transformer models to alternative architecture Mamba, termed TransMamba. Our approach employs a two-stage strategy to expedite training new Mamba models, ensuring effectiveness in across uni-modal and cross-modal tasks. Concerning architecture disparities, we project the intermediate features into an aligned latent space before transferring knowledge. On top of that, a Weight Subcloning and Adaptive Bidirectional distillation method (WSAB) is introduced for knowledge transfer without limitations on varying layer counts. For cross-modal learning, we propose a cross-Mamba module that integrates language awareness into Mamba's visual features, enhancing the cross-modal interaction capabilities of Mamba architecture. Despite using less than 75% of the training data typically required for training from scratch, TransMamba boasts substantially stronger performance across various network architectures and downstream tasks, including image classification, visual question answering, and text-video retrieval. The code will be publicly available.
WonderHuman: Hallucinating Unseen Parts in Dynamic 3D Human Reconstruction
Feb 03, 2025In this paper, we present WonderHuman to reconstruct dynamic human avatars from a monocular video for high-fidelity novel view synthesis. Previous dynamic human avatar reconstruction methods typically require the input video to have full coverage of the observed human body. However, in daily practice, one typically has access to limited viewpoints, such as monocular front-view videos, making it a cumbersome task for previous methods to reconstruct the unseen parts of the human avatar. To tackle the issue, we present WonderHuman, which leverages 2D generative diffusion model priors to achieve high-quality, photorealistic reconstructions of dynamic human avatars from monocular videos, including accurate rendering of unseen body parts. Our approach introduces a Dual-Space Optimization technique, applying Score Distillation Sampling (SDS) in both canonical and observation spaces to ensure visual consistency and enhance realism in dynamic human reconstruction. Additionally, we present a View Selection strategy and Pose Feature Injection to enforce the consistency between SDS predictions and observed data, ensuring pose-dependent effects and higher fidelity in the reconstructed avatar. In the experiments, our method achieves SOTA performance in producing photorealistic renderings from the given monocular video, particularly for those challenging unseen parts. The project page and source code can be found at https://wyiguanw.github.io/WonderHuman/.
ComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
Jan 21, 2025



Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.
CatV2TON: Taming Diffusion Transformers for Vision-Based Virtual Try-On with Temporal Concatenation
Jan 20, 2025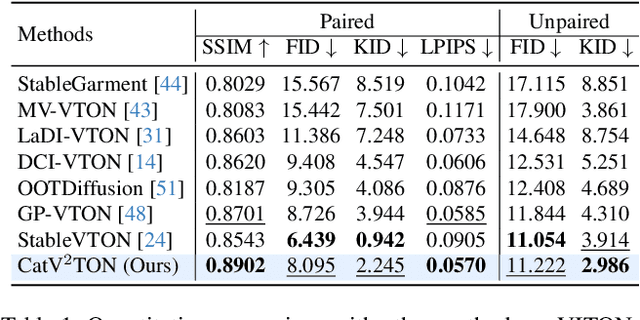
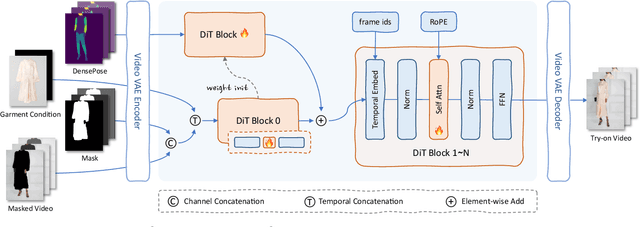
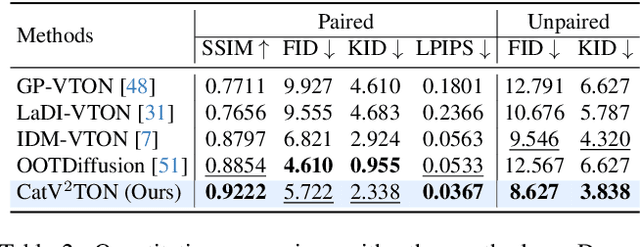
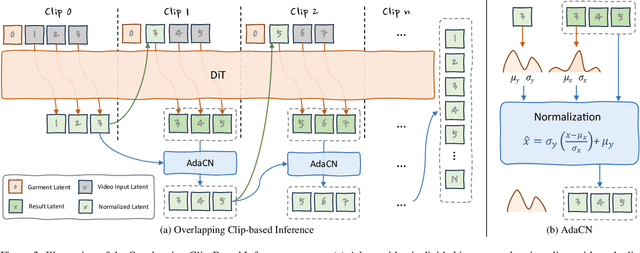
Virtual try-on (VTON) technology has gained attention due to its potential to transform online retail by enabling realistic clothing visualization of images and videos. However, most existing methods struggle to achieve high-quality results across image and video try-on tasks, especially in long video scenarios. In this work, we introduce CatV2TON, a simple and effective vision-based virtual try-on (V2TON) method that supports both image and video try-on tasks with a single diffusion transformer model. By temporally concatenating garment and person inputs and training on a mix of image and video datasets, CatV2TON achieves robust try-on performance across static and dynamic settings. For efficient long-video generation, we propose an overlapping clip-based inference strategy that uses sequential frame guidance and Adaptive Clip Normalization (AdaCN) to maintain temporal consistency with reduced resource demands. We also present ViViD-S, a refined video try-on dataset, achieved by filtering back-facing frames and applying 3D mask smoothing for enhanced temporal consistency. Comprehensive experiments demonstrate that CatV2TON outperforms existing methods in both image and video try-on tasks, offering a versatile and reliable solution for realistic virtual try-ons across diverse scenarios.
RMAvatar: Photorealistic Human Avatar Reconstruction from Monocular Video Based on Rectified Mesh-embedded Gaussians
Jan 13, 2025



We introduce RMAvatar, a novel human avatar representation with Gaussian splatting embedded on mesh to learn clothed avatar from a monocular video. We utilize the explicit mesh geometry to represent motion and shape of a virtual human and implicit appearance rendering with Gaussian Splatting. Our method consists of two main modules: Gaussian initialization module and Gaussian rectification module. We embed Gaussians into triangular faces and control their motion through the mesh, which ensures low-frequency motion and surface deformation of the avatar. Due to the limitations of LBS formula, the human skeleton is hard to control complex non-rigid transformations. We then design a pose-related Gaussian rectification module to learn fine-detailed non-rigid deformations, further improving the realism and expressiveness of the avatar. We conduct extensive experiments on public datasets, RMAvatar shows state-of-the-art performance on both rendering quality and quantitative evaluations. Please see our project page at https://rm-avatar.github.io.
LiTformer: Efficient Modeling and Analysis of High-Speed Link Transmitters Using Non-Autoregressive Transformer
Nov 18, 2024



High-speed serial links are fundamental to energy-efficient and high-performance computing systems such as artificial intelligence, 5G mobile and automotive, enabling low-latency and high-bandwidth communication. Transmitters (TXs) within these links are key to signal quality, while their modeling presents challenges due to nonlinear behavior and dynamic interactions with links. In this paper, we propose LiTformer: a Transformer-based model for high-speed link TXs, with a non-sequential encoder and a Transformer decoder to incorporate link parameters and capture long-range dependencies of output signals. We employ a non-autoregressive mechanism in model training and inference for parallel prediction of the signal sequence. LiTformer achieves precise TX modeling considering link impacts including crosstalk from multiple links, and provides fast prediction for various long-sequence signals with high data rates. Experimental results show that LiTformer achieves 148-456$\times$ speedup for 2-link TXs and 404-944$\times$ speedup for 16-link with mean relative errors of 0.68-1.25%, supporting 4-bit signals at Gbps data rates of single-ended and differential TXs, as well as PAM4 TXs.
A Survey of Foundation Models for Music Understanding
Sep 15, 2024
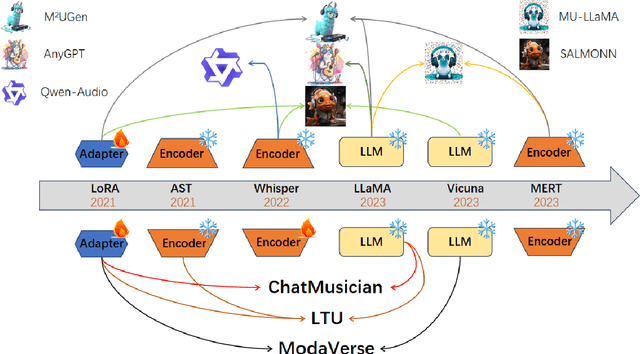
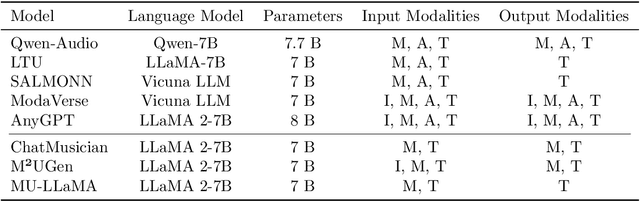
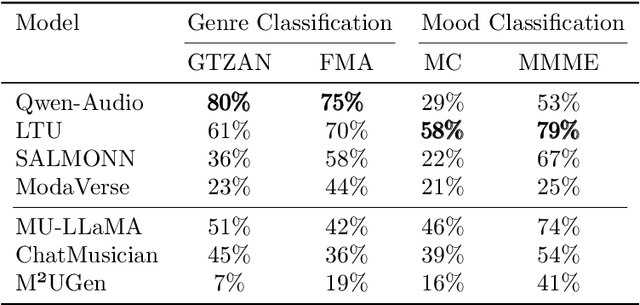
Music is essential in daily life, fulfilling emotional and entertainment needs, and connecting us personally, socially, and culturally. A better understanding of music can enhance our emotions, cognitive skills, and cultural connections. The rapid advancement of artificial intelligence (AI) has introduced new ways to analyze music, aiming to replicate human understanding of music and provide related services. While the traditional models focused on audio features and simple tasks, the recent development of large language models (LLMs) and foundation models (FMs), which excel in various fields by integrating semantic information and demonstrating strong reasoning abilities, could capture complex musical features and patterns, integrate music with language and incorporate rich musical, emotional and psychological knowledge. Therefore, they have the potential in handling complex music understanding tasks from a semantic perspective, producing outputs closer to human perception. This work, to our best knowledge, is one of the early reviews of the intersection of AI techniques and music understanding. We investigated, analyzed, and tested recent large-scale music foundation models in respect of their music comprehension abilities. We also discussed their limitations and proposed possible future directions, offering insights for researchers in this field.
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models
Jul 21, 2024



Virtual try-on methods based on diffusion models achieve realistic try-on effects but often replicate the backbone network as a ReferenceNet or use additional image encoders to process condition inputs, leading to high training and inference costs. In this work, we rethink the necessity of ReferenceNet and image encoders and innovate the interaction between garment and person by proposing CatVTON, a simple and efficient virtual try-on diffusion model. CatVTON facilitates the seamless transfer of in-shop or worn garments of any category to target persons by simply concatenating them in spatial dimensions as inputs. The efficiency of our model is demonstrated in three aspects: (1) Lightweight network: Only the original diffusion modules are used, without additional network modules. The text encoder and cross-attentions for text injection in the backbone are removed, reducing the parameters by 167.02M. (2) Parameter-efficient training: We identified the try-on relevant modules through experiments and achieved high-quality try-on effects by training only 49.57M parameters, approximately 5.51 percent of the backbone network's parameters. (3) Simplified inference: CatVTON eliminates all unnecessary conditions and preprocessing steps, including pose estimation, human parsing, and text input, requiring only a garment reference, target person image, and mask for the virtual try-on process. Extensive experiments demonstrate that CatVTON achieves superior qualitative and quantitative results with fewer prerequisites and trainable parameters than baseline methods. Furthermore, CatVTON shows good generalization in in-the-wild scenarios despite using open-source datasets with only 73K samples.
OV-DINO: Unified Open-Vocabulary Detection with Language-Aware Selective Fusion
Jul 10, 2024



Open-vocabulary detection is a challenging task due to the requirement of detecting objects based on class names, including those not encountered during training. Existing methods have shown strong zero-shot detection capabilities through pre-training on diverse large-scale datasets. However, these approaches still face two primary challenges: (i) how to universally integrate diverse data sources for end-to-end training, and (ii) how to effectively leverage the language-aware capability for region-level cross-modality understanding. To address these challenges, we propose a novel unified open-vocabulary detection method called OV-DINO, which pre-trains on diverse large-scale datasets with language-aware selective fusion in a unified framework. Specifically, we introduce a Unified Data Integration (UniDI) pipeline to enable end-to-end training and eliminate noise from pseudo-label generation by unifying different data sources into detection-centric data. In addition, we propose a Language-Aware Selective Fusion (LASF) module to enable the language-aware ability of the model through a language-aware query selection and fusion process. We evaluate the performance of the proposed OV-DINO on popular open-vocabulary detection benchmark datasets, achieving state-of-the-art results with an AP of 50.6\% on the COCO dataset and 40.0\% on the LVIS dataset in a zero-shot manner, demonstrating its strong generalization ability. Furthermore, the fine-tuned OV-DINO on COCO achieves 58.4\% AP, outperforming many existing methods with the same backbone. The code for OV-DINO will be available at \href{https://github.com/wanghao9610/OV-DINO}{https://github.com/wanghao9610/OV-DINO}.