 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyCrowd: Instance-Isolated Identity-Pose Binding for Arbitrary Multi-Character Animation
Mar 16, 2026Controllable character animation has advanced rapidly in recent years, yet multi-character animation remains underexplored. As the number of characters grows, multi-character reference encoding becomes more susceptible to latent identity entanglement, resulting in identity bleeding and reduced controllability. Moreover, learning precise and spatio-temporally consistent correspondences between reference identities and driving pose sequences becomes increasingly challenging, often leading to identity-pose mis-binding and inconsistency in generated videos. To address these challenges, we propose AnyCrowd, a Diffusion Transformer (DiT)-based video generation framework capable of scaling to an arbitrary number of characters. Specifically, we first introduce an Instance-Isolated Latent Representation (IILR), which encodes character instances independently prior to DiT processing to prevent latent identity entanglement. Building on this disentangled representation, we further propose Tri-Stage Decoupled Attention (TSDA) to bind identities to driving poses by decomposing self-attention into: (i) instance-aware foreground attention, (ii) background-centric interaction, and (iii) global foreground-background coordination. Furthermore, to mitigate token ambiguity in overlapping regions, an Adaptive Gated Fusion (AGF) module is integrated within TSDA to predict identity-aware weights, effectively fusing competing token groups into identity-consistent representations...
ComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
Jan 21, 2025



Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.
CatV2TON: Taming Diffusion Transformers for Vision-Based Virtual Try-On with Temporal Concatenation
Jan 20, 2025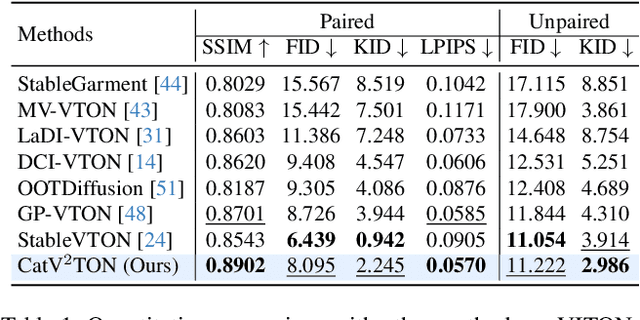
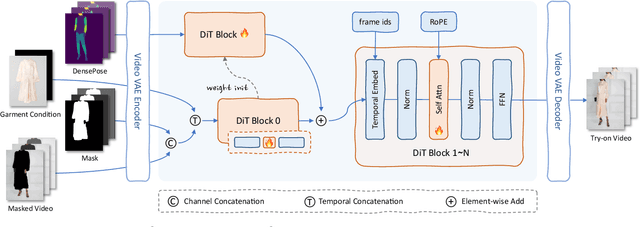
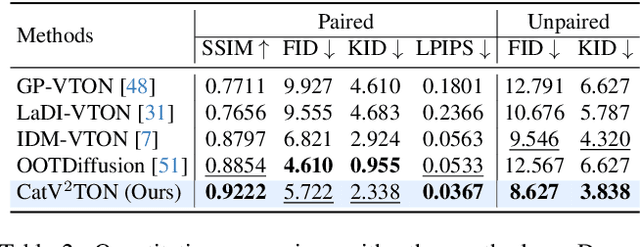
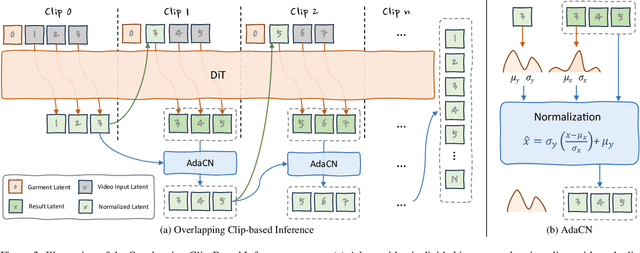
Virtual try-on (VTON) technology has gained attention due to its potential to transform online retail by enabling realistic clothing visualization of images and videos. However, most existing methods struggle to achieve high-quality results across image and video try-on tasks, especially in long video scenarios. In this work, we introduce CatV2TON, a simple and effective vision-based virtual try-on (V2TON) method that supports both image and video try-on tasks with a single diffusion transformer model. By temporally concatenating garment and person inputs and training on a mix of image and video datasets, CatV2TON achieves robust try-on performance across static and dynamic settings. For efficient long-video generation, we propose an overlapping clip-based inference strategy that uses sequential frame guidance and Adaptive Clip Normalization (AdaCN) to maintain temporal consistency with reduced resource demands. We also present ViViD-S, a refined video try-on dataset, achieved by filtering back-facing frames and applying 3D mask smoothing for enhanced temporal consistency. Comprehensive experiments demonstrate that CatV2TON outperforms existing methods in both image and video try-on tasks, offering a versatile and reliable solution for realistic virtual try-ons across diverse scenarios.
GarmentAligner: Text-to-Garment Generation via Retrieval-augmented Multi-level Corrections
Aug 23, 2024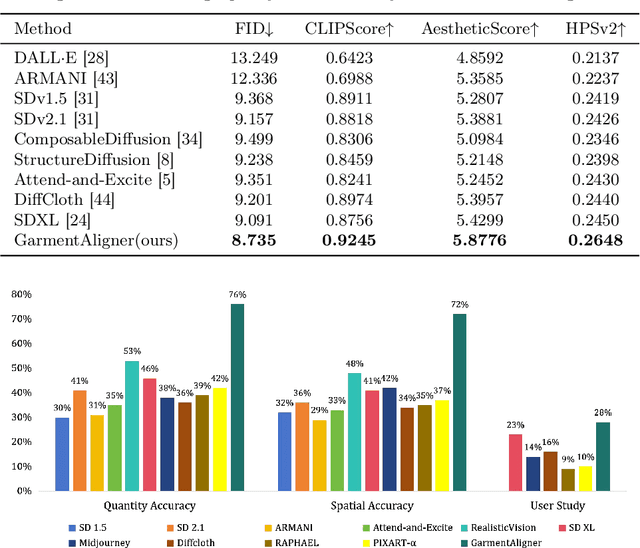



General text-to-image models bring revolutionary innovation to the fields of arts, design, and media. However, when applied to garment generation, even the state-of-the-art text-to-image models suffer from fine-grained semantic misalignment, particularly concerning the quantity, position, and interrelations of garment components. Addressing this, we propose GarmentAligner, a text-to-garment diffusion model trained with retrieval-augmented multi-level corrections. To achieve semantic alignment at the component level, we introduce an automatic component extraction pipeline to obtain spatial and quantitative information of garment components from corresponding images and captions. Subsequently, to exploit component relationships within the garment images, we construct retrieval subsets for each garment by retrieval augmentation based on component-level similarity ranking and conduct contrastive learning to enhance the model perception of components from positive and negative samples. To further enhance the alignment of components across semantic, spatial, and quantitative granularities, we propose the utilization of multi-level correction losses that leverage detailed component information. The experimental findings demonstrate that GarmentAligner achieves superior fidelity and fine-grained semantic alignment when compared to existing competitors.
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models
Jul 21, 2024



Virtual try-on methods based on diffusion models achieve realistic try-on effects but often replicate the backbone network as a ReferenceNet or use additional image encoders to process condition inputs, leading to high training and inference costs. In this work, we rethink the necessity of ReferenceNet and image encoders and innovate the interaction between garment and person by proposing CatVTON, a simple and efficient virtual try-on diffusion model. CatVTON facilitates the seamless transfer of in-shop or worn garments of any category to target persons by simply concatenating them in spatial dimensions as inputs. The efficiency of our model is demonstrated in three aspects: (1) Lightweight network: Only the original diffusion modules are used, without additional network modules. The text encoder and cross-attentions for text injection in the backbone are removed, reducing the parameters by 167.02M. (2) Parameter-efficient training: We identified the try-on relevant modules through experiments and achieved high-quality try-on effects by training only 49.57M parameters, approximately 5.51 percent of the backbone network's parameters. (3) Simplified inference: CatVTON eliminates all unnecessary conditions and preprocessing steps, including pose estimation, human parsing, and text input, requiring only a garment reference, target person image, and mask for the virtual try-on process. Extensive experiments demonstrate that CatVTON achieves superior qualitative and quantitative results with fewer prerequisites and trainable parameters than baseline methods. Furthermore, CatVTON shows good generalization in in-the-wild scenarios despite using open-source datasets with only 73K samples.
Fashion Matrix: Editing Photos by Just Talking
Jul 25, 2023



The utilization of Large Language Models (LLMs) for the construction of AI systems has garnered significant attention across diverse fields. The extension of LLMs to the domain of fashion holds substantial commercial potential but also inherent challenges due to the intricate semantic interactions in fashion-related generation. To address this issue, we developed a hierarchical AI system called Fashion Matrix dedicated to editing photos by just talking. This system facilitates diverse prompt-driven tasks, encompassing garment or accessory replacement, recoloring, addition, and removal. Specifically, Fashion Matrix employs LLM as its foundational support and engages in iterative interactions with users. It employs a range of Semantic Segmentation Models (e.g., Grounded-SAM, MattingAnything, etc.) to delineate the specific editing masks based on user instructions. Subsequently, Visual Foundation Models (e.g., Stable Diffusion, ControlNet, etc.) are leveraged to generate edited images from text prompts and masks, thereby facilitating the automation of fashion editing processes. Experiments demonstrate the outstanding ability of Fashion Matrix to explores the collaborative potential of functionally diverse pre-trained models in the domain of fashion editing.