 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatV2TON: Taming Diffusion Transformers for Vision-Based Virtual Try-On with Temporal Concatenation
Jan 20, 2025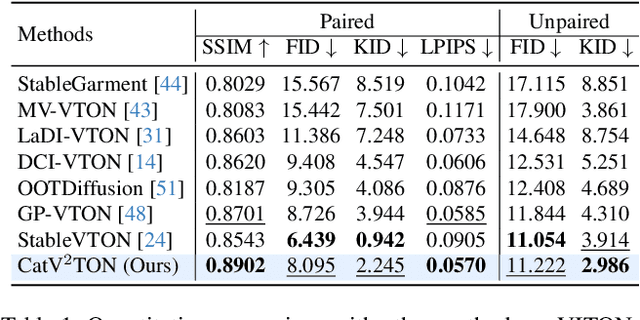
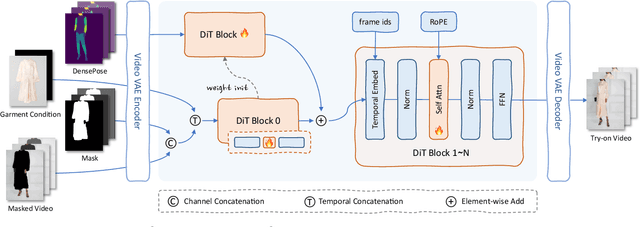
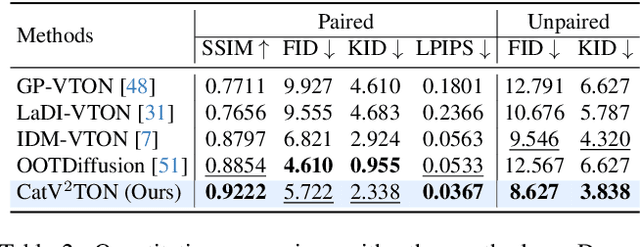
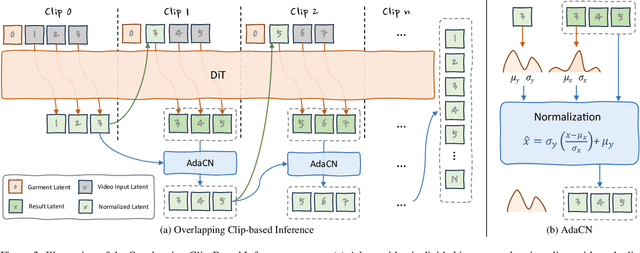
Virtual try-on (VTON) technology has gained attention due to its potential to transform online retail by enabling realistic clothing visualization of images and videos. However, most existing methods struggle to achieve high-quality results across image and video try-on tasks, especially in long video scenarios. In this work, we introduce CatV2TON, a simple and effective vision-based virtual try-on (V2TON) method that supports both image and video try-on tasks with a single diffusion transformer model. By temporally concatenating garment and person inputs and training on a mix of image and video datasets, CatV2TON achieves robust try-on performance across static and dynamic settings. For efficient long-video generation, we propose an overlapping clip-based inference strategy that uses sequential frame guidance and Adaptive Clip Normalization (AdaCN) to maintain temporal consistency with reduced resource demands. We also present ViViD-S, a refined video try-on dataset, achieved by filtering back-facing frames and applying 3D mask smoothing for enhanced temporal consistency. Comprehensive experiments demonstrate that CatV2TON outperforms existing methods in both image and video try-on tasks, offering a versatile and reliable solution for realistic virtual try-ons across diverse scenarios.
KAN4TSF: Are KAN and KAN-based models Effective for Time Series Forecasting?
Aug 21, 2024



Time series forecasting is a crucial task that predicts the future values of variables based on historical data. Time series forecasting techniques have been developing in parallel with the machine learning community, from early statistical learning methods to current deep learning methods. Although existing methods have made significant progress, they still suffer from two challenges. The mathematical theory of mainstream deep learning-based methods does not establish a clear relation between network sizes and fitting capabilities, and these methods often lack interpretability. To this end, we introduce the Kolmogorov-Arnold Network (KAN) into time series forecasting research, which has better mathematical properties and interpretability. First, we propose the Reversible Mixture of KAN experts (RMoK) model, which is a KAN-based model for time series forecasting. RMoK uses a mixture-of-experts structure to assign variables to KAN experts. Then, we compare performance, integration, and speed between RMoK and various baselines on real-world datasets, and the experimental results show that RMoK achieves the best performance in most cases. And we find the relationship between temporal feature weights and data periodicity through visualization, which roughly explains RMoK's mechanism. Thus, we conclude that KAN and KAN-based models (RMoK) are effective in time series forecasting. Code is available at KAN4TSF: https://github.com/2448845600/KAN4TSF.
VLAD-VSA: Cross-Domain Face Presentation Attack Detection with Vocabulary Separation and Adaptation
Feb 21, 2022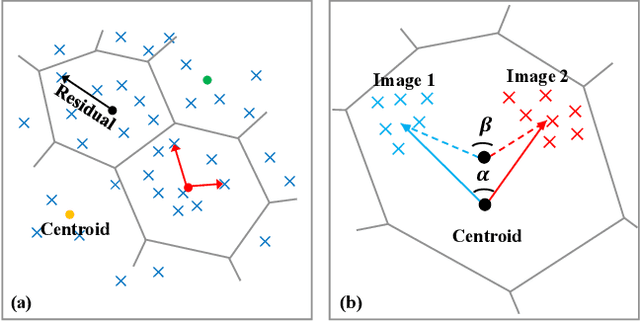
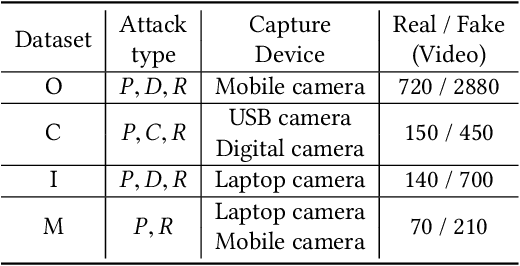
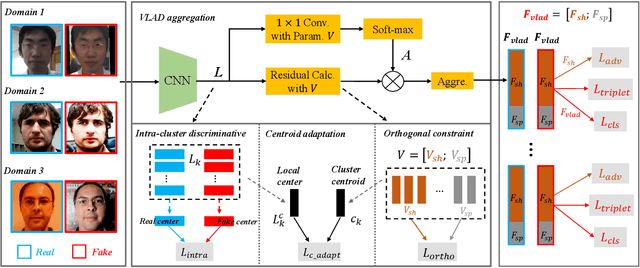

For face presentation attack detection (PAD), most of the spoofing cues are subtle, local image patterns (e.g., local image distortion, 3D mask edge and cut photo edges). The representations of existing PAD works with simple global pooling method, however, lose the local feature discriminability. In this paper, the VLAD aggregation method is adopted to quantize local features with visual vocabulary locally partitioning the feature space, and hence preserve the local discriminability. We further propose the vocabulary separation and adaptation method to modify VLAD for cross-domain PADtask. The proposed vocabulary separation method divides vocabulary into domain-shared and domain-specific visual words to cope with the diversity of live and attack faces under the cross-domain scenario. The proposed vocabulary adaptation method imitates the maximization step of the k-means algorithm in the end-to-end training, which guarantees the visual words be close to the center of assigned local features and thus brings robust similarity measurement. We give illustrations and extensive experiments to demonstrate the effectiveness of VLAD with the proposed vocabulary separation and adaptation method on standard cross-domain PAD benchmarks. The codes are available at https://github.com/Liubinggunzu/VLAD-VSA.