 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMAvatar: Photorealistic Human Avatar Reconstruction from Monocular Video Based on Rectified Mesh-embedded Gaussians
Jan 13, 2025



We introduce RMAvatar, a novel human avatar representation with Gaussian splatting embedded on mesh to learn clothed avatar from a monocular video. We utilize the explicit mesh geometry to represent motion and shape of a virtual human and implicit appearance rendering with Gaussian Splatting. Our method consists of two main modules: Gaussian initialization module and Gaussian rectification module. We embed Gaussians into triangular faces and control their motion through the mesh, which ensures low-frequency motion and surface deformation of the avatar. Due to the limitations of LBS formula, the human skeleton is hard to control complex non-rigid transformations. We then design a pose-related Gaussian rectification module to learn fine-detailed non-rigid deformations, further improving the realism and expressiveness of the avatar. We conduct extensive experiments on public datasets, RMAvatar shows state-of-the-art performance on both rendering quality and quantitative evaluations. Please see our project page at https://rm-avatar.github.io.
SurgicalGaussian: Deformable 3D Gaussians for High-Fidelity Surgical Scene Reconstruction
Jul 06, 2024



Dynamic reconstruction of deformable tissues in endoscopic video is a key technology for robot-assisted surgery. Recent reconstruction methods based on neural radiance fields (NeRFs) have achieved remarkable results in the reconstruction of surgical scenes. However, based on implicit representation, NeRFs struggle to capture the intricate details of objects in the scene and cannot achieve real-time rendering. In addition, restricted single view perception and occluded instruments also propose special challenges in surgical scene reconstruction. To address these issues, we develop SurgicalGaussian, a deformable 3D Gaussian Splatting method to model dynamic surgical scenes. Our approach models the spatio-temporal features of soft tissues at each time stamp via a forward-mapping deformation MLP and regularization to constrain local 3D Gaussians to comply with consistent movement. With the depth initialization strategy and tool mask-guided training, our method can remove surgical instruments and reconstruct high-fidelity surgical scenes. Through experiments on various surgical videos, our network outperforms existing method on many aspects, including rendering quality, rendering speed and GPU usage. The project page can be found at https://surgicalgaussian.github.io.
DRSM: efficient neural 4d decomposition for dynamic reconstruction in stationary monocular cameras
Feb 01, 2024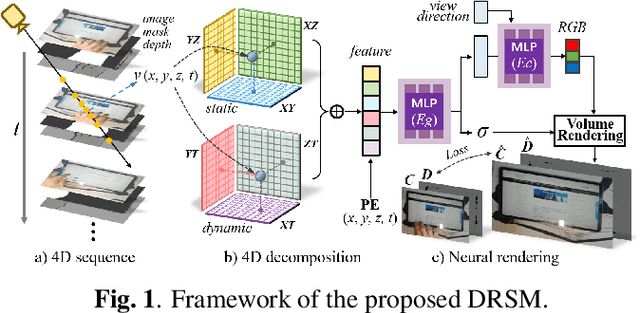



With the popularity of monocular videos generated by video sharing and live broadcasting applications, reconstructing and editing dynamic scenes in stationary monocular cameras has become a special but anticipated technology. In contrast to scene reconstructions that exploit multi-view observations, the problem of modeling a dynamic scene from a single view is significantly more under-constrained and ill-posed. Inspired by recent progress in neural rendering, we present a novel framework to tackle 4D decomposition problem for dynamic scenes in monocular cameras. Our framework utilizes decomposed static and dynamic feature planes to represent 4D scenes and emphasizes the learning of dynamic regions through dense ray casting. Inadequate 3D clues from a single-view and occlusion are also particular challenges in scene reconstruction. To overcome these difficulties, we propose deep supervised optimization and ray casting strategies. With experiments on various videos, our method generates higher-fidelity results than existing methods for single-view dynamic scene representation.