 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMU-Flownet: Exploring Point Cloud Scene Flow Estimation in Occluded Scenario
Apr 16, 2024Occlusions hinder point cloud frame alignment in LiDAR data, a challenge inadequately addressed by scene flow models tested mainly on occlusion-free datasets. Attempts to integrate occlusion handling within networks often suffer accuracy issues due to two main limitations: a) the inadequate use of occlusion information, often merging it with flow estimation without an effective integration strategy, and b) reliance on distance-weighted upsampling that falls short in correcting occlusion-related errors. To address these challenges, we introduce the Correlation Matrix Upsampling Flownet (CMU-Flownet), incorporating an occlusion estimation module within its cost volume layer, alongside an Occlusion-aware Cost Volume (OCV) mechanism. Specifically, we propose an enhanced upsampling approach that expands the sensory field of the sampling process which integrates a Correlation Matrix designed to evaluate point-level similarity. Meanwhile, our model robustly integrates occlusion data within the context of scene flow, deploying this information strategically during the refinement phase of the flow estimation. The efficacy of this approach is demonstrated through subsequent experimental validation. Empirical assessments reveal that CMU-Flownet establishes state-of-the-art performance within the realms of occluded Flyingthings3D and KITTY datasets, surpassing previous methodologies across a majority of evaluated metrics.
DRSM: efficient neural 4d decomposition for dynamic reconstruction in stationary monocular cameras
Feb 01, 2024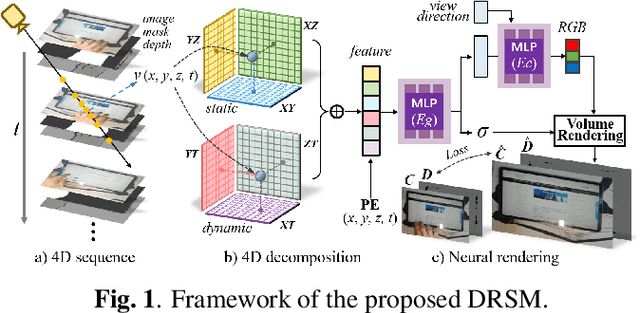



With the popularity of monocular videos generated by video sharing and live broadcasting applications, reconstructing and editing dynamic scenes in stationary monocular cameras has become a special but anticipated technology. In contrast to scene reconstructions that exploit multi-view observations, the problem of modeling a dynamic scene from a single view is significantly more under-constrained and ill-posed. Inspired by recent progress in neural rendering, we present a novel framework to tackle 4D decomposition problem for dynamic scenes in monocular cameras. Our framework utilizes decomposed static and dynamic feature planes to represent 4D scenes and emphasizes the learning of dynamic regions through dense ray casting. Inadequate 3D clues from a single-view and occlusion are also particular challenges in scene reconstruction. To overcome these difficulties, we propose deep supervised optimization and ray casting strategies. With experiments on various videos, our method generates higher-fidelity results than existing methods for single-view dynamic scene representation.
SSFlowNet: Semi-supervised Scene Flow Estimation On Point Clouds With Pseudo Label
Dec 23, 2023



In the domain of supervised scene flow estimation, the process of manual labeling is both time-intensive and financially demanding. This paper introduces SSFlowNet, a semi-supervised approach for scene flow estimation, that utilizes a blend of labeled and unlabeled data, optimizing the balance between the cost of labeling and the precision of model training. SSFlowNet stands out through its innovative use of pseudo-labels, mainly reducing the dependency on extensively labeled datasets while maintaining high model accuracy. The core of our model is its emphasis on the intricate geometric structures of point clouds, both locally and globally, coupled with a novel spatial memory feature. This feature is adept at learning the geometric relationships between points over sequential time frames. By identifying similarities between labeled and unlabeled points, SSFlowNet dynamically constructs a correlation matrix to evaluate scene flow dependencies at individual point level. Furthermore, the integration of a flow consistency module within SSFlowNet enhances its capability to consistently estimate flow, an essential aspect for analyzing dynamic scenes. Empirical results demonstrate that SSFlowNet surpasses existing methods in pseudo-label generation and shows adaptability across varying data volumes. Moreover, our semi-supervised training technique yields promising outcomes even with different smaller ratio labeled data, marking a substantial advancement in the field of scene flow estimation.