 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOD-DEAL: Dynamic Expert-Guided Adversarial Learning with Online Decomposition for Scalable Capacitated Vehicle Routing
Feb 03, 2026Solving large-scale capacitated vehicle routing problems (CVRP) is hindered by the high complexity of heuristics and the limited generalization of neural solvers on massive graphs. We propose OD-DEAL, an adversarial learning framework that tightly integrates hybrid genetic search (HGS) and online barycenter clustering (BCC) decomposition, and leverages high-fidelity knowledge distillation to transfer expert heuristic behavior. OD-DEAL trains a graph attention network (GAT)-based generative policy through a minimax game, in which divide-and-conquer strategies from a hybrid expert are distilled into dense surrogate rewards. This enables high-quality, clustering-free inference on large-scale instances. Empirical results demonstrate that OD-DEAL achieves state-of-the-art (SOTA) real-time CVRP performance, solving 10000-node instances with near-constant neural scaling. This uniquely enables the sub-second, heuristic-quality inference required for dynamic large-scale deployment.
C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025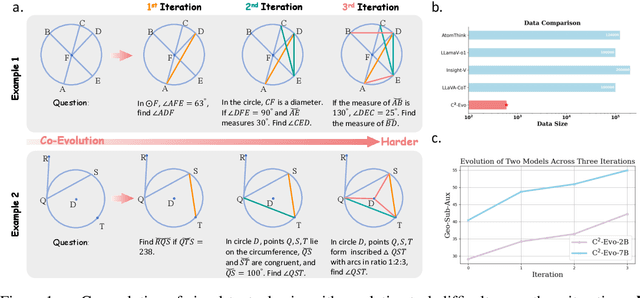

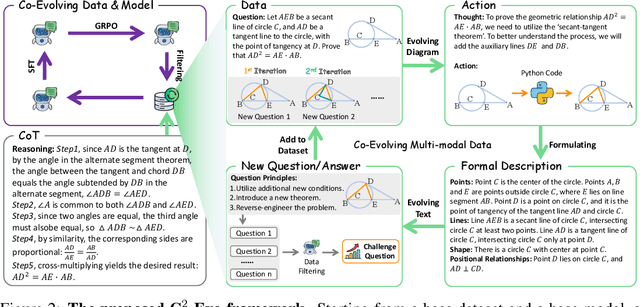
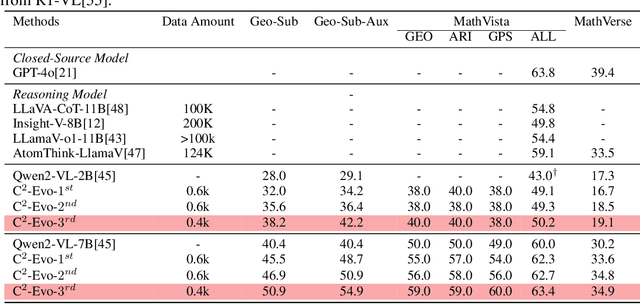
Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
SemHiTok: A Unified Image Tokenizer via Semantic-Guided Hierarchical Codebook for Multimodal Understanding and Generation
Mar 09, 2025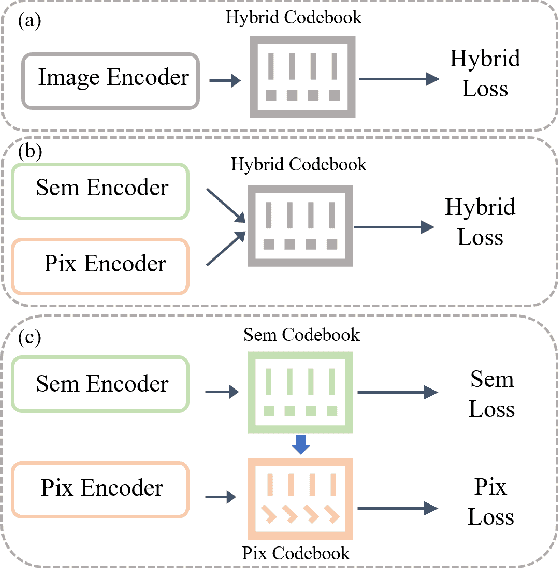
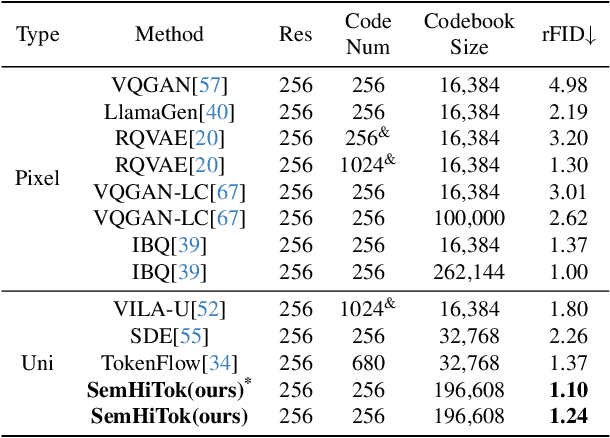
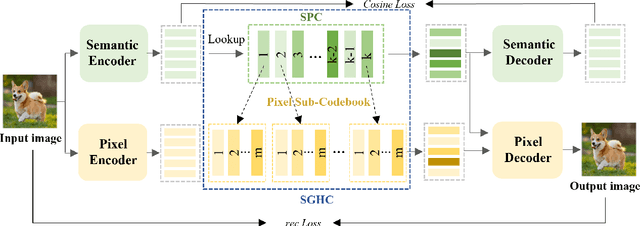
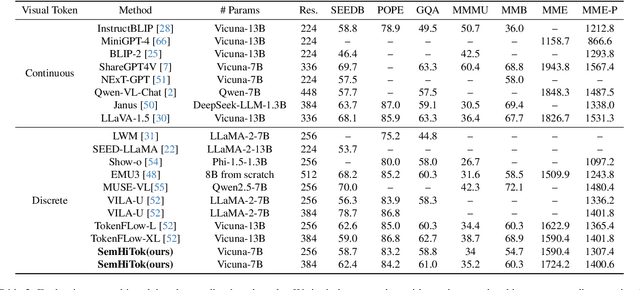
We present SemHiTok, a unified image Tokenizer via Semantic-Guided Hierarchical codebook that provides consistent discrete feature representations for multimodal understanding and generation tasks. Recently, unified multimodal large models (MLLMs) for understanding and generation have sparked exploration within research community. Previous works attempt to train a unified image tokenizer by combining loss functions for semantic feature reconstruction and pixel reconstruction. However, due to the differing levels of features prioritized by multimodal understanding and generation tasks, joint training methods face significant challenges in achieving a good trade-off. SemHiTok addresses this challenge through Semantic-Guided Hierarchical codebook which builds texture sub-codebooks on pre-trained semantic codebook. This design decouples the training of semantic reconstruction and pixel reconstruction and equips the tokenizer with low-level texture feature extraction capability without degradation of high-level semantic feature extraction ability. Our experiments demonstrate that SemHiTok achieves state-of-the-art rFID score at 256X256resolution compared to other unified tokenizers, and exhibits competitive performance on multimodal understanding and generation tasks.
TransMamba: Fast Universal Architecture Adaption from Transformers to Mamba
Feb 21, 2025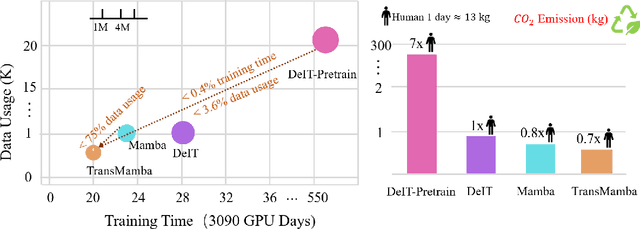
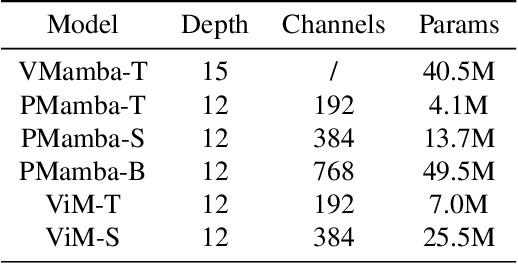
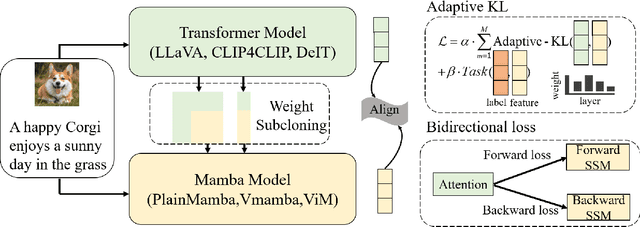
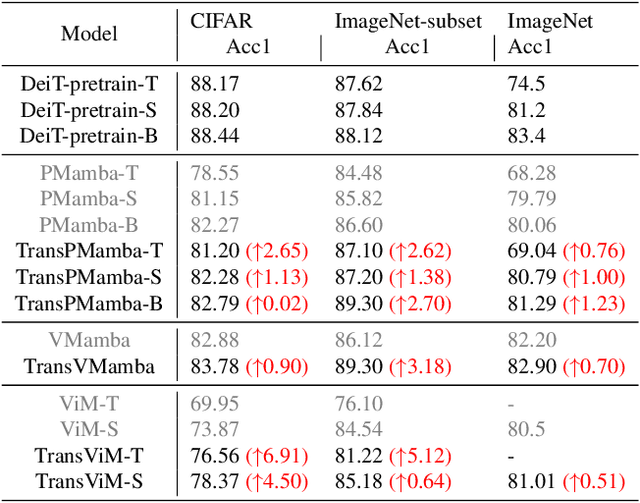
Transformers have been favored in both uni-modal and multi-modal foundation models for their flexible scalability in attention modules. Consequently, a number of pre-trained Transformer models, e.g., LLaVA, CLIP, and DEIT, are publicly available. Recent research has introduced subquadratic architectures like Mamba, which enables global awareness with linear complexity. Nevertheless, training specialized subquadratic architectures from scratch for certain tasks is both resource-intensive and time-consuming. As a motivator, we explore cross-architecture training to transfer the ready knowledge in existing Transformer models to alternative architecture Mamba, termed TransMamba. Our approach employs a two-stage strategy to expedite training new Mamba models, ensuring effectiveness in across uni-modal and cross-modal tasks. Concerning architecture disparities, we project the intermediate features into an aligned latent space before transferring knowledge. On top of that, a Weight Subcloning and Adaptive Bidirectional distillation method (WSAB) is introduced for knowledge transfer without limitations on varying layer counts. For cross-modal learning, we propose a cross-Mamba module that integrates language awareness into Mamba's visual features, enhancing the cross-modal interaction capabilities of Mamba architecture. Despite using less than 75% of the training data typically required for training from scratch, TransMamba boasts substantially stronger performance across various network architectures and downstream tasks, including image classification, visual question answering, and text-video retrieval. The code will be publicly available.
Unsupervised Semantic Segmentation of 3D Point Clouds via Cross-modal Distillation and Super-Voxel Clustering
Apr 18, 2023
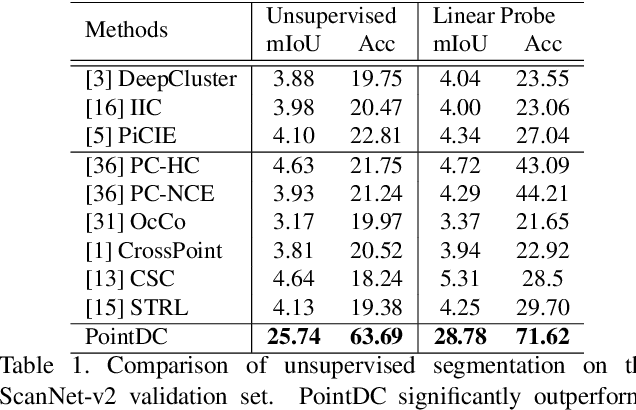


Semantic segmentation of point clouds usually requires exhausting efforts of human annotations, hence it attracts wide attention to the challenging topic of learning from unlabeled or weaker forms of annotations. In this paper, we take the first attempt for fully unsupervised semantic segmentation of point clouds, which aims to delineate semantically meaningful objects without any form of annotations. Previous works of unsupervised pipeline on 2D images fails in this task of point clouds, due to: 1) Clustering Ambiguity caused by limited magnitude of data and imbalanced class distribution; 2) Irregularity Ambiguity caused by the irregular sparsity of point cloud. Therefore, we propose a novel framework, PointDC, which is comprised of two steps that handle the aforementioned problems respectively: Cross-Modal Distillation (CMD) and Super-Voxel Clustering (SVC). In the first stage of CMD, multi-view visual features are back-projected to the 3D space and aggregated to a unified point feature to distill the training of the point representation. In the second stage of SVC, the point features are aggregated to super-voxels and then fed to the iterative clustering process for excavating semantic classes. PointDC yields a significant improvement over the prior state-of-the-art unsupervised methods, on both the ScanNet-v2 (+18.4 mIoU) and S3DIS (+11.5 mIoU) semantic segmentation benchmarks.